Within Parallel scale
The paper that made scaling look practical
The 2017 Transformer paper made hardware efficiency part of the breakthrough by showing strong translation results after short multi-GPU training.
On this page
- Machine translation as the early test case
- What the eight GPU training result showed
- Why the result changed architectural expectations
Page outline Jump by section
Introduction
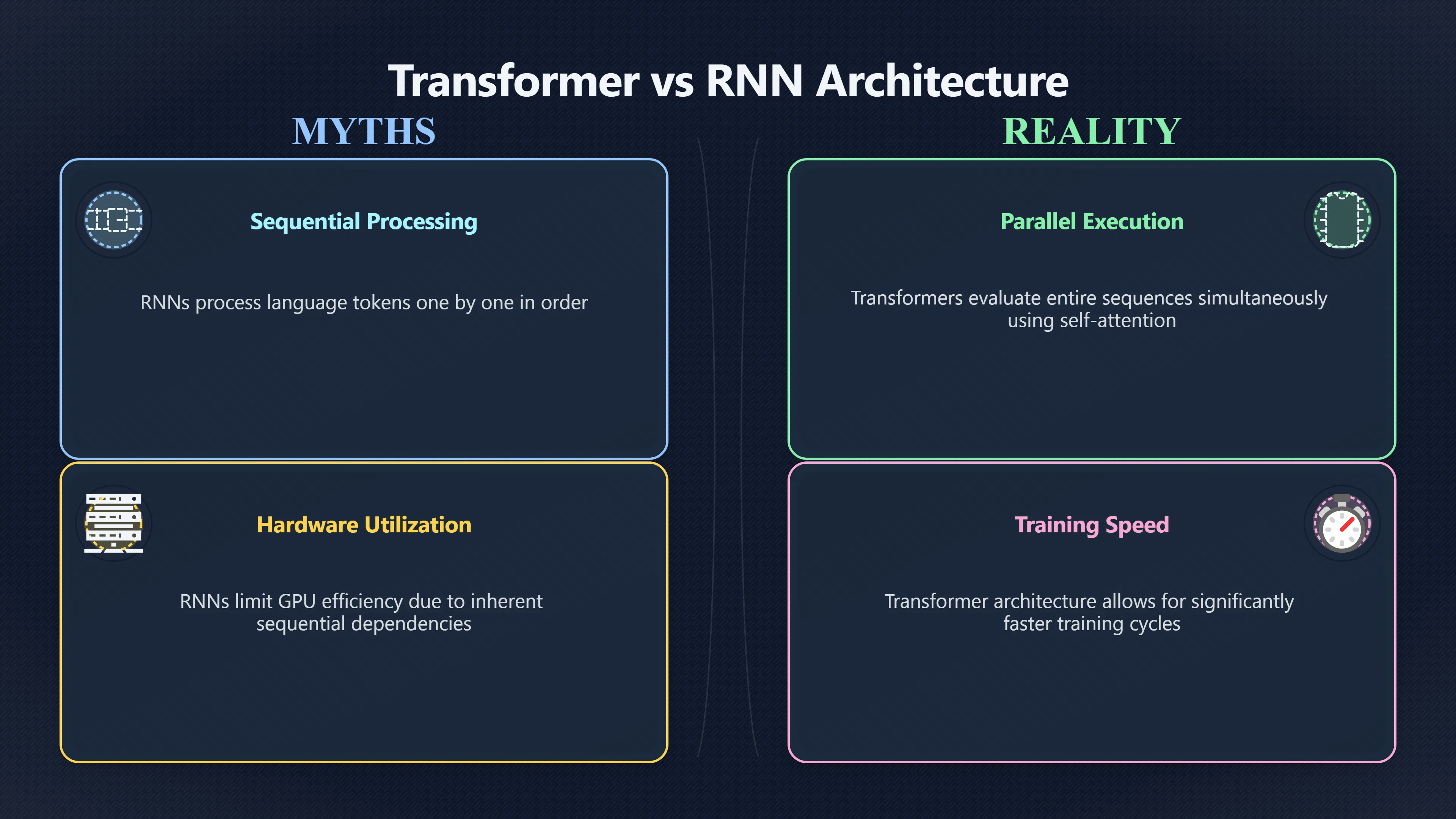
The original Transformer paper did more than introduce a new neural-network design. It provided one of the clearest demonstrations that hardware-efficient training could become a competitive advantage in artificial intelligence. In 2017, machine translation was one of the most demanding and closely watched benchmarks in AI. Many leading systems achieved strong results, but they relied on architectures that processed sequences step by step. The Transformer showed that an architecture designed for parallel computation could not only match those systems but surpass them while training far more efficiently. That result helped convince researchers that future progress might come from scaling computation and data, not merely inventing increasingly complex recurrent networks. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…

Machine translation as the early test case
Before large language models became the centre of AI research, machine translation served as a proving ground for new sequence-learning architectures. Success on major translation benchmarks such as WMT 2014 English–German and English–French carried significant weight because these tasks required models to handle long sequences, complex grammar and dependencies between distant words. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
At the time, the dominant approaches were recurrent neural networks (RNNs), long short-term memory networks (LSTMs), and related encoder–decoder systems. Although these models could be trained across batches of examples, each sentence still had to be processed token by token. This limited how effectively modern GPUs could be used. Adding more hardware did not eliminate the sequential dependency built into the architecture itself. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
The Transformer was therefore tested in an environment where efficiency mattered. Translation researchers were already spending substantial computational resources to achieve incremental improvements. If a new architecture could deliver both better accuracy and better hardware utilisation, it would challenge prevailing assumptions about how sequence models should be built. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
What the eight-GPU training result showed
The strongest evidence in the paper was not simply the final benchmark score. It was the combination of performance and training cost.
The authors reported that their Transformer achieved a BLEU score of 28.4 on the WMT 2014 English–German translation benchmark, exceeding previous published results, including ensemble systems. On the larger English–French task, the model achieved a new single-model state-of-the-art score of 41.8 BLEU after training for 3.5 days on eight NVIDIA P100 GPUs. The paper explicitly highlighted that this represented only a small fraction of the training cost associated with the best competing systems. [arXiv+2NeurIPS Papers]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
The hardware details mattered because they demonstrated practical scalability. The Transformer’s self-attention operations could be expressed as large matrix calculations, allowing GPUs to process many positions in a sequence simultaneously. Instead of waiting for one word’s computation to finish before beginning the next, the model could evaluate relationships across an entire sequence within a layer at the same time. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
The paper also revealed an important contrast between model variants. The base Transformer could be trained in roughly 12 hours on eight P100 GPUs, while the larger version required about 3.5 days. Even so, these training schedules produced state-of-the-art translation quality, showing that larger models could be trained within realistic research timelines rather than requiring prohibitively long runs. [LinkedIn]linkedin.comLinked In Understanding the Groundbreaking 'Attention Is All You …Our models on one machine with 8 NVIDIA P100 GPUs · Base models usingLinkedInUnderstanding the Groundbreaking 'Attention Is All You …Our models on one machine with 8 NVIDIA P100 GPUs · Base models using t…
This was not merely a laboratory curiosity. Researchers could now see a direct path from architectural design to better utilisation of available hardware.


Why the result changed architectural expectations
The most important consequence of the paper was psychological as much as technical. For years, many researchers assumed that sequence modelling required recurrence. Language unfolds over time, so it seemed natural that neural networks should process it sequentially. The Transformer challenged that assumption by removing recurrence entirely while still producing better translation results. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
The paper’s abstract made the claim directly: the new models were both “more parallelizable” and required significantly less time to train. That wording signalled a shift in what counted as progress. Instead of judging architectures solely by accuracy, researchers increasingly evaluated whether they could exploit modern computing hardware efficiently. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
The reaction was amplified by what happened next. Subsequent work rapidly pushed Transformer training times even lower. Within roughly a year, researchers demonstrated that comparable translation performance could be reached in under five hours on eight GPUs through improved large-batch training techniques. That speed-up was possible because the underlying architecture was already designed for parallel execution. [statmt.org]statmt.orgScaling Neural Machine TranslationNovember 21, 2018 — by M Ott · Cited by 770 — 1 On WMT'14 English-German translation, we match the accu…
In retrospect, the eight-GPU result served as an early proof that scaling computation could become a reliable route to better AI systems. The Transformer did not merely outperform earlier translation models. It showed that an architecture aligned with GPU hardware could improve as more computing resources were applied. That lesson became one of the foundational ideas behind the later development of large language models and the broader scaling era of artificial intelligence. [arXiv+2Google Research]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
Amazon book picks
Further Reading
Books and field guides related to The paper that made scaling look practical. Use these as the next step if you want deeper reading beyond the article.
Hands-On Large Language Models
Shows how scaling emerged from transformer foundations.
Natural Language Processing with Transformers
Connects the original paper to modern implementations.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: arxiv.org
Title: arXiv [Attention]({{ ‘attention/’ | relative_url }}) Is All You Need
Link: https://arxiv.org/abs/1706.03762Source snippet
Attention Is All You NeedJune 12, 2017...
Published: June 12, 2017
-
Source: arxiv.org
Title: arXiv Attention is All You Need in Speech Separation
Link: https://arxiv.org/abs/2010.13154 -
Source: papers.neurips.cc
Title: 7181 attention is all you need
Link: https://papers.neurips.cc/paper/7181-attention-is-all-you-need.pdfSource snippet
Even our base model surpasses all previously published models and ensembles, at a fraction of the training cost of...Read more...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/[understandingSource snippet
Understanding the Groundbreaking 'Attention Is All You...Our models on one machine with 8 NVIDIA P100 GPUs · Base models using t...
-
Source: statmt.org
Link: https://www.statmt.org/wmt18/pdf/WMT001.pdfSource snippet
Scaling Neural Machine TranslationNovember 21, 2018 — by M Ott · Cited by 770 — 1 On WMT'14 English-German translation, we match the accu...
Published: November 21, 2018
-
Source: arxiv.org
Link: https://arxiv.org/html/1706.03762v7Source snippet
Attention Is All You NeedTraining took 3.5 3.5 days on 8 8 P100 GPUs. Even our base model surpasses all previously published models and e...
-
Source: arxiv.org
Link: https://arxiv.org/pdf/1706.03762Source snippet
1706.03762v7 [cs.CL] 2 Aug 2023by A Vaswani · 2017 · Cited by 252349 — We propose a new simple network architecture, the Transforme...
-
Source: arxiv.org
Link: https://arxiv.org/html/1706.03762v3Source snippet
Attention Is All You Need20 Jun 2017 — On the WMT 2014 English-to-French translation task, our big model achieves a BLEU score of 41.17 4...
-
Source: papers.nips.cc
Title: 7181 attention is all you need
Link: https://papers.nips.cc/paper/7181-attention-is-all-you-needSource snippet
NeurIPS PapersAttention is All you Needby A Vaswani · 2017 · Cited by 240733 — Experiments on two machine translation tasks show these mo...
-
Source: research.google
Title: transformer a novel neural network architecture for language understanding
Link: https://research.google/blog/transformer-a-novel-neural-network-architecture-for-language-understanding/Source snippet
Google ResearchTransformer: A Novel Neural Network Architecture for...Aug 31, 2017 — In “Attention Is All You Need”, we introduce the Tr...
-
Source: research.google
Title: attention is all you need
Link: https://research.google/pubs/attention-is-all-you-need/Source snippet
Google ResearchAttention is All You NeedOur model achieves 28.4 BLEU on the WMT 2014 English-to-German translation... a small fraction o...
-
Source: Wikipedia
Link: https://en.wikipedia.org/wiki/AttentionSource snippet
AttentionAttention is the concentration of awareness directed at some task or phenomenon while mostly excluding others. Focused attent...
Additional References
-
Source: academia.edu
Link: https://www.academia.edu/76518792/Attention_is_All_you_NeedSource snippet
(PDF) Attention is All you NeedThe Transformer model achieves a state-of-the-art BLEU score of 28.4 on English-to-German translation. Tra...
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/394854371_Revolutionizing_Vision_A_Deep_Dive_into_Attention_Is_All_You_Need_and_Its_Impact_on_AI_and_Machine_LearningSource snippet
A Deep Dive into "Attention Is All You Need" and Its Impact...Aug 23, 2025 — This research paper discusses in depth the transformer mode...
-
Source: medium.com
Link: https://medium.com/%40Elongated_musk/attention-is-all-you-need-until-you-need-memory-0450aa84af3fSource snippet
Attention Is All You Need… Until You Need MemoryTransformers replaced the old step‑by‑step approach with fully [parallel self]({{ 'parallel-attention/' | relative_url }})‑attention, l...
-
Source: medium.com
Link: https://medium.com/%40aminasaeed223/attention-is-all-you-need-simply-explained-24b6ceffb945Source snippet
Attention is all you need — simply explainedThe Transformer is a powerful model that relies purely on attention mechanisms instead of tra...
-
Source: dev.to
Link: https://dev.to/anurag_deo_83cb605e78d252/the-ai-revolution-you-didnt-see-coming-how-attention-is-all-you-need-changed-everything-42jhSource snippet
The AI Revolution You Didn't See Coming: How "Attention...Jun 4, 2025 — While CNNs can capture local patterns and are more parallelizabl...
-
Source: medium.com
Link: https://medium.com/codex/attention-is-all-you-need-explained-ebdb02c7f4d4Source snippet
“Attention Is All You Need” Explained | by Zaynab AwofesoTransformer ran on just 8 NVIDIA P100 GPUs and completed training in only 3.5 da...
-
Source: proceedings.mlr.press
Link: https://proceedings.mlr.press/v97/so19a/so19a.pdfSource snippet
Evolved Transformer establishes a new state-of- the-art BLEU score of 29.8 on WMT'14 English-. German; at smaller sizes, it achieves...R...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=54uLU7Nxyv8Source snippet
Kaggle Reading Group: Attention is All You Need | KaggleJoin Kaggle Data Scientist Rachael as she reads through an NLP paper! Today's pap...
-
Source: techwithram.medium.com
Title: attention is all you need ai paper that changed whole world 1425c326ca3c
Link: https://techwithram.medium.com/attention-is-all-you-need-ai-paper-that-changed-whole-world-1425c326ca3cSource snippet
Is All You Need: AI paper that changed the whole worldThe Transformer achieves new state-of-the-art performance on machine translation be...
-
Source: medium.com
Title: A Paper A Day: #24 Attention Is All You Need | by Amr Sharaf
Link: https://medium.com/%40sharaf/a-paper-a-day-24-attention-is-all-you-need-26eb2da90a91Source snippet
BLEU. On the WMT 2014 English-to-French translation task, the model establishes a new single-model state-of-the-art BLEU score of 41.0 af...
Topic Tree