Within Attention maps
Why Following Attention Across Layers Changes the Story
Following information across layers often gives a more faithful picture of model influence than a single attention visualization.
On this page
- How attention flow works
- What rollout reveals that heat maps miss
- Comparing attention flow with other attribution methods
Page outline Jump by section
Introduction
A coloured attention heat map can be visually persuasive. If a token receives a bright, high-attention score, it appears to be the piece of text that mattered most. The problem is that a Transformer does not make decisions from a single attention layer. Information is repeatedly mixed, copied, and transformed across many layers. By the time a model reaches a later layer, the representation associated with one token may already contain information gathered from numerous earlier tokens. As a result, a single attention map often shows only a local routing decision rather than the full path of influence through the network. Research on attention flow and attention rollout was developed specifically to address this problem by tracing how information propagates across layers rather than inspecting one layer in isolation. These methods generally correlate more strongly with independent measures of token importance than raw attention heat maps do. [ACL Anthology]aclanthology.org2020.acl main.385ACL AnthologyQuantifying Attention Flow in Transformersby S Abnar · 2020 · Cited by 1768 — We propose two methods for approximating the a…

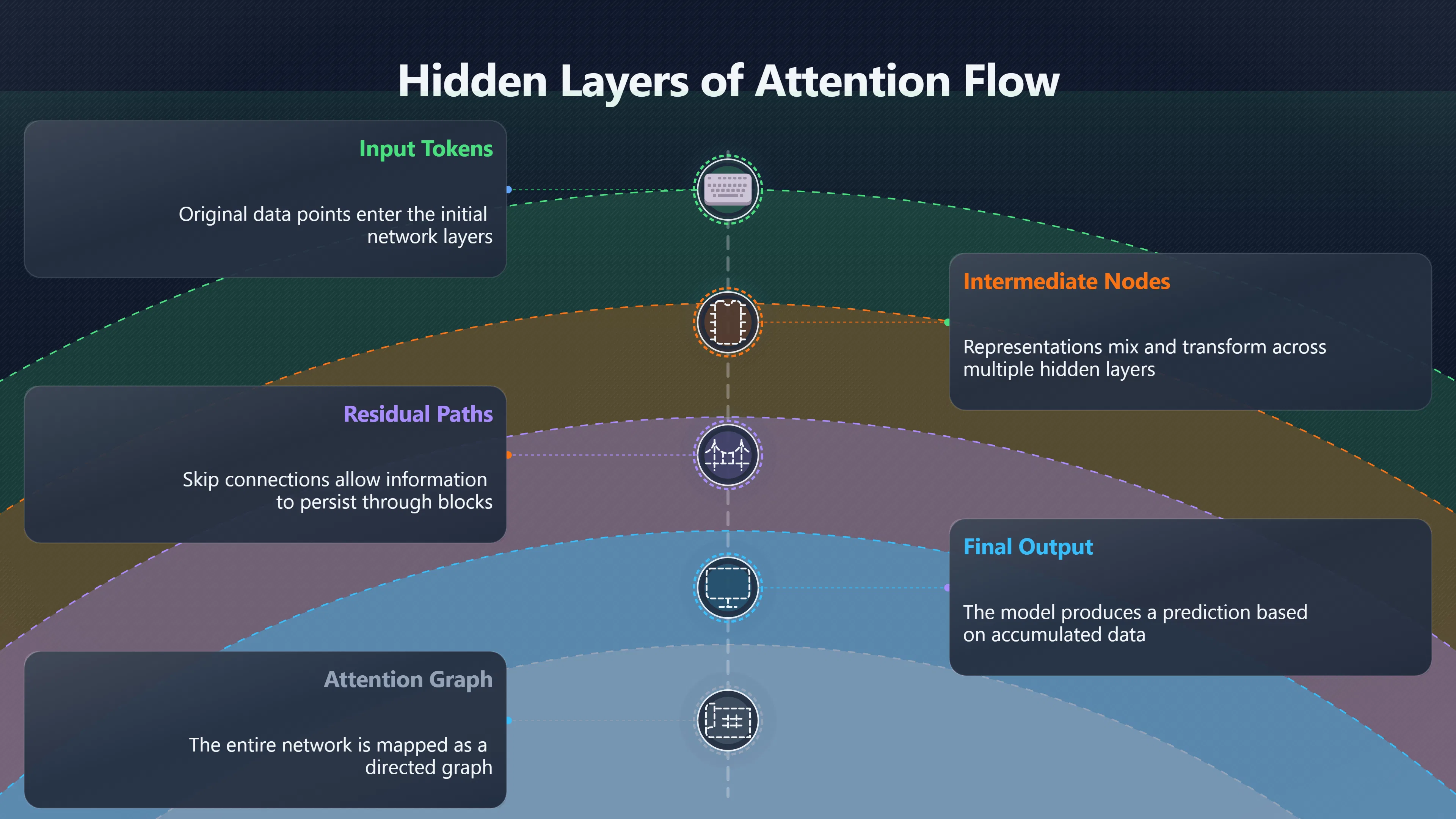
How attention flow works
The key idea behind attention flow is that influence in a Transformer is cumulative. Every self-attention layer takes representations from the previous layer and combines them into new representations. Because this process repeats many times, information originating from one input token can travel through numerous intermediate nodes before contributing to a final prediction. [ACL Anthology]aclanthology.org2020.acl main.385ACL AnthologyQuantifying Attention Flow in Transformersby S Abnar · 2020 · Cited by 1768 — We propose two methods for approximating the a…
A standard attention heat map typically answers a narrow question:
Which representations is this token attending to right now?
Attention flow asks a different question:
Through all layers of the network, how much information from each input token can reach this representation?
To answer that question, the model is treated as a directed graph. Tokens and hidden representations become nodes, while attention connections become weighted edges. The method then estimates how much influence can travel from input tokens to later representations through the entire network rather than through a single layer. [ACL Anthology]aclanthology.org2020.acl main.385ACL AnthologyQuantifying Attention Flow in Transformersby S Abnar · 2020 · Cited by 1768 — We propose two methods for approximating the a…
This distinction matters because residual connections—the skip connections present in Transformer blocks—allow information to persist even when attention weights appear small. Attention flow and related methods explicitly account for these pathways, producing a more realistic picture of how information moves through the model. [ResearchGate]researchgate.netResearch Gate(PDF) Quantifying Attention Flow in TransformersResearchGate(PDF) Quantifying Attention Flow in TransformersMay 8, 2020 — To understand how attention is aggregated through the network…
A useful analogy is air travel. Looking at the final flight into a destination does not reveal where passengers originally started. Many travellers may have arrived through connecting airports. Attention flow reconstructs the entire journey, while a single heat map only shows the final leg.
What rollout reveals that heat maps miss
Attention rollout was introduced alongside attention flow as a practical way to estimate how attention accumulates through layers. Instead of examining one attention matrix at a time, rollout recursively combines attention matrices across layers. The result is an estimate of how strongly a final representation is connected to the original input tokens. [ACL Anthology]aclanthology.org2020.acl main.385ACL AnthologyQuantifying Attention Flow in Transformersby S Abnar · 2020 · Cited by 1768 — We propose two methods for approximating the a…
This approach reveals several patterns that are often hidden in ordinary visualisations.
Influence can come from indirect paths
Suppose a final-layer token strongly attends to token B. A heat map might suggest that B is the main source of information. However, token B may itself have obtained most of its information from tokens A and C in earlier layers. Looking only at the final layer obscures that history. Rollout and flow methods recover these indirect dependencies. [ACL Anthology]aclanthology.org2020.acl main.385ACL AnthologyQuantifying Attention Flow in Transformersby S Abnar · 2020 · Cited by 1768 — We propose two methods for approximating the a…

Late-layer attention can be misleading
As representations become more abstract, a token’s embedding increasingly contains mixed information from multiple sources. A late-layer attention score therefore reflects attention to an already-combined representation rather than to a single original token. Tracking attention across layers helps disentangle those mixtures. [arXiv]arxiv.orgarXiv Quantifying Attention Flow in TransformersarXiv Quantifying Attention Flow in Transformers
Hidden contributors become visible
In many cases, important input tokens receive modest attention in the final layers but exert substantial influence through chains of intermediate interactions. Heat maps can understate their role, whereas attention flow often identifies them as significant contributors. [ACL Anthology]aclanthology.org2020.acl main.385ACL AnthologyQuantifying Attention Flow in Transformersby S Abnar · 2020 · Cited by 1768 — We propose two methods for approximating the a…
The empirical evidence is one reason these methods attracted attention. In experiments on Transformer models, attention rollout and attention flow showed substantially higher agreement with independent importance measures, including gradient-based attribution and input-ablation tests, than raw attention weights did. [ACL Anthology]aclanthology.org2020.acl main.385ACL AnthologyQuantifying Attention Flow in Transformersby S Abnar · 2020 · Cited by 1768 — We propose two methods for approximating the a…
Why this matters for explanations
The broader debate around attention as explanation emerged after studies showed that raw attention weights often correlate poorly with other measures of feature importance. Researchers demonstrated that very different attention patterns could sometimes produce essentially the same prediction, raising doubts about interpreting a heat map as a causal explanation. [arXiv]arxiv.orgarXiv Attention is not ExplanationAttention is not ExplanationFebruary 26, 2019…
Attention flow does not completely solve the explanation problem, but it addresses one of the main weaknesses of raw attention visualisation: the failure to account for information mixing across layers. Instead of treating attention as a single snapshot, it models attention as a process unfolding through the network. [ACL Anthology]aclanthology.org2020.acl main.385ACL AnthologyQuantifying Attention Flow in Transformersby S Abnar · 2020 · Cited by 1768 — We propose two methods for approximating the a…
This shift changes the interpretation:
- A heat map shows where information is being routed at one step. [Attention Rollout]creatis-myriad.github.ioQuantifying Attention Flow in Transformers7 Jul 2022 — This paper presents two methods, Attention Rollout and Attention Flow, that allow… ut estimates how routing decisions accumulate across steps.
- Attention flow estimates how influence can travel through the entire attention graph. [ACL Anthology]aclanthology.org2020.acl main.385ACL AnthologyQuantifying Attention Flow in Transformersby S Abnar · 2020 · Cited by 1768 — We propose two methods for approximating the a…
For someone trying to understand why a Transformer produced a particular output, the latter two perspectives are usually closer to the underlying computation.

Comparing attention flow with other attribution methods
Attention flow is best viewed as part of a broader interpretability toolkit rather than a definitive measure of causation. Researchers commonly compare it with gradient-based attribution, input ablation, and relevance-propagation methods. [CVF Open Access]openaccess.thecvf.comCVF Open AccessTransformer Interpretability Beyond Attention Visualizationby H Chefer · 2021 · Cited by 1538 — The rollout method [1] is…
Each approach answers a slightly different question:
MethodMain questionRaw attention heat mapsWhere is attention directed in a particular layer?Attention rolloutHow does attention accumulate across layers?Attention flowWhich input tokens can transmit influence through the network graph?GradientsHow much would the output change if an input changed slightly?Ablation testsWhat happens if an input token is removed or masked?
Attention flow has an important advantage over simple heat maps because it respects the multi-layer structure of Transformers. However, gradient and ablation methods often remain stronger indicators of causal influence because they directly measure output sensitivity rather than relying solely on attention patterns. This is why many modern interpretability studies use attention flow as one source of evidence and compare it against independent attribution methods. [ACL Anthology+2CVF Open Access]aclanthology.org2020.acl main.385ACL AnthologyQuantifying Attention Flow in Transformersby S Abnar · 2020 · Cited by 1768 — We propose two methods for approximating the a…
The practical lesson is that attention heat maps are easiest to visualise but often oversimplify what is happening. Following attention through the network—whether through rollout, flow, or related methods—produces a richer and usually more faithful picture of how information from the input contributes to the model’s final behaviour. [ACL Anthology]aclanthology.org2020.acl main.385ACL AnthologyQuantifying Attention Flow in Transformersby S Abnar · 2020 · Cited by 1768 — We propose two methods for approximating the a…
Amazon book picks
Further Reading
Books and field guides related to Why Following Attention Across Layers Changes the Story. Use these as the next step if you want deeper reading beyond the article.
Natural Language Processing with Transformers
Explains transformer layers and attention mechanisms that attention-flow methods analyse.
Deep Learning
Rating: 3.5/5 from 6 Google Books ratings
Provides foundations for layered neural representations and gradient-based learning.
Hands-on Machine Learning with Scikit-Learn, Keras, and Tenso...
Helps readers build enough practical ML context to understand model internals and visualisation methods.
Interpretable Machine Learning
Gives readers broader tools for judging attribution and explanation methods.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.



Endnotes
-
Source: arxiv.org
Title: arXiv Quantifying Attention Flow in Transformers
Link: https://arxiv.org/abs/2005.00928 -
Source: researchgate.net
Title: Research Gate(PDF) Quantifying Attention Flow in Transformers
Link: https://www.researchgate.net/publication/341148976_Quantifying_Attention_Flow_in_TransformersSource snippet
ResearchGate(PDF) Quantifying Attention Flow in TransformersMay 8, 2020 — To understand how attention is aggregated through the network...
Published: May 8, 2020
-
Source: arxiv.org
Title: arXiv Attention is not Explanation
Link: https://arxiv.org/abs/1902.10186Source snippet
Attention is not ExplanationFebruary 26, 2019...
Published: February 26, 2019
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/343298597_Quantifying_Attention_Flow_in_TransformersSource snippet
introduced attention rollout, attention flow, and more elaborate graph-based...Read more...
-
Source: aclanthology.org
Title: 2020.acl main.385
Link: https://aclanthology.org/2020.acl-main.385/Source snippet
ACL AnthologyQuantifying Attention Flow in Transformersby S Abnar · 2020 · Cited by 1768 — We propose two methods for approximating the a...
-
Source: samiraabnar.github.io
Title: attention flow
Link: https://samiraabnar.github.io/articles/2020-04/attention_flowSource snippet
Quantifying Attention Flow in TransformersApr 5, 2020 — I explain two simple but effective methods, called Attention Rollout and Attentio...
-
Source: aclanthology.org
Title: 2020.acl main.385
Link: https://aclanthology.org/2020.acl-main.385.pdfSource snippet
ACL AnthologyQuantifying Attention Flow in Transformersby S Abnar · 2020 · Cited by 1691 — The main difference between attention rollout...
-
Source: openaccess.thecvf.com
Link: https://openaccess.thecvf.com/content/CVPR2021/papers/Chefer_Transformer_Interpretability_Beyond_Attention_Visualization_CVPR_2021_paper.pdfSource snippet
CVF Open AccessTransformer Interpretability Beyond Attention Visualizationby H Chefer · 2021 · Cited by 1538 — The rollout method [1] is...
-
Source: Wikipedia
Link: https://en.wikipedia.org/wiki/TransformerSource snippet
TransformerA transformer is a passive component that transfers electrical energy from one electrical circuit to another circuit, or mu...
-
Source: github.com
Title: attention rollout for vision transformer.ipynb
Link: https://github.com/arnavs04/paper-implementations/blob/main/attention-rollout/attention-rollout-for-vision-transformer.ipynbSource snippet
20, 2024 — Attention rollout has been shown to produce more interpretable and [meaningful]({{ 'human-review/' | relative_url }}) visualizations of attention, especially for deep...
-
Source: medium.com
Link: https://medium.com/data-science-collective/how-to-read-a-transformers-mind-and-when-you-can-t-ccaedf4b83eaSource snippet
Attention Rollout: One Beautiful Idea, One Easy-to-Miss Fix...In this article we will build the attention rollout mechanism from scratch...
-
Source: scribd.com
Link: https://www.scribd.com/document/913571062/2020-acl-main-385Source snippet
rdam ILLC, University of AmsterdamRead more...
-
Source: emergentmind.com
Title: gradient attention rollout
Link: https://www.emergentmind.com/topics/gradient-attention-rolloutSource snippet
Oct 15, 2025 — Gradient Attention Rollout aggregates attention and gradient data across Transformer layers to yield sharper and more fait...
-
Source: creatis-myriad.github.io
Title: Attention Rollout
Link: https://creatis-myriad.github.io/2022/07/07/AttentionRollout.htmlSource snippet
Quantifying Attention Flow in Transformers7 Jul 2022 — This paper presents two methods, Attention Rollout and Attention Flow, that allow...
-
Source: kaggle.com
Title: attention rollout for vision transformers
Link: https://www.kaggle.com/code/arnavs19/attention-rollout-for-vision-transformersSource snippet
Jun 20, 2024 — Attention rollout has been shown to produce more interpretable and meaningful visualizations of attention, especially for...
-
Source: hackmd.io
Link: https://hackmd.io/%40YungHuiHsu/rk8ZHeqysSource snippet
[Explainable AI] Transformer Interpretability Beyond...Nov 8, 2023 — [Explainable AI] Transformer Interpretability Beyond Attention Visu...
Additional References
-
Source: medium.com
Link: https://medium.com/%40nivonl/exploring-visual-attention-in-transformer-models-ab538c06083aSource snippet
Exploring Visual Attention in Transformer ModelsIn this post, we will delve into how to quantify and visualize attention, focusing on the...
-
Source: merriam-webster.com
Link: https://www.merriam-webster.com/dictionary/informationSource snippet
INFORMATION Definition & Meaning6 days ago — The meaning of INFORMATION is knowledge gained from investigation, study, or instruction. Ho...
-
Source: semanticscholar.org
Link: https://www.semanticscholar.org/paper/Quantifying-Attention-Flow-in-Transformers-Abnar-Zuidema/76a9f336481b39515d6cea2920696f11fb686451Source snippet
[PDF] Quantifying Attention Flow in TransformersThis paper proposes two methods for approximating the attention to input tokens given att...
-
Source: github.com
Link: https://github.com/samiraabnar/attention_flow -
Source: youtube.com
Link: https://www.youtube.com/watch?v=DVoHvmww2lQSource snippet
James Briggs | Vision Transformers (ViT) Explained + Fine-tuning in Python - [https://www.youtube.com/watch?v=qU7wO02urYU](https://www.youtube.com/watch?v=qU7wO02urYU) Good Place to un...
-
Source: youtu.be
Title: Revealing Dark Secrets of BERT (Analysis of BERT’s Attention Heads)
Link: https://youtu.be/mnU9ILoDH68Source snippet
Abstract of the paper In the Transformer model, “self-attention” combines information from attended embed- dings into the representation...
-
Source: medium.com
Title: how to read a transformers mind and when you can t ccaedf4b83ea
Link: https://medium.com/%40sean.j.moran/how-to-read-a-transformers-mind-and-when-you-can-t-ccaedf4b83eaSource snippet
How to read a Transformer's mind — and when you can'tAbnar & Zuidema (2020) — “Quantifying Attention Flow in Transformers” — — The origin...
-
Source: medium.com
Title: interpretability and analysis of models for nlp e6b977ac1dc6
Link: https://medium.com/%40lawrence.carolin/interpretability-and-analysis-of-models-for-nlp-e6b977ac1dc6Source snippet
Interpretability and Analysis of Models for NLP @ ACL 2020To combat this, they introduce attention rollout and attention flow as post-hoc...
-
Source: youtube.com
Title: Image Classification Using Vision Transformer | An Image is Worth 16x16 Words
Link: https://www.youtube.com/watch?v=G6_IA5vKXRISource snippet
Quantifying Attention Flow In Transformers (Effective Way to Interpret Attention in BERT) Explained - YouTube Quantifying Attention Flow...
-
Source: github.com
Link: https://github.com/jacobgil/vit-explainSource snippet
jacobgil/vit-explain: Explainability for Vision TransformersThe Attention Rollout method suggests taking the average attention accross th...
Topic Tree