Within AI Drafts
How Do You Judge a Useful AI Draft?
Generative AI is often used very differently from predictive AI. A predictive model is usually judged by whether it gives the correct answer: did it identify fraud, predict demand, or classify an image accurately? A generative model, by contrast, produces drafts, summaries, code, designs, and ideas that people often revise before using.
On this page
- Why accuracy metrics are not enough
- Usefulness, revision, and reader fit
- When a good starting point is still risky
Page outline Jump by section
Introduction
Generative AI is often used very differently from predictive AI. A predictive model is usually judged by whether it gives the correct answer: did it identify fraud, predict demand, or classify an image accurately? A generative model, by contrast, produces drafts, summaries, code, designs, and ideas that people often revise before using. That difference means accuracy remains important, but it is no longer sufficient as the main measure of success.
 When people use generative AI as a starting point rather than a final authority, the central question changes from “Was it correct?” to “Did it help someone accomplish a task?” Researchers, standards bodies, and organisations increasingly argue that generative AI should be evaluated through a broader set of measures that include usefulness, efficiency, creativity support, revision effort, safety, and real-world outcomes rather than benchmark accuracy alone. [NIST Publications+2nae.edu]nvlpubs.nist.govNIST PublicationsArtificial Intelligence Risk Management Frameworkby N AI · 2024 · Cited by 134 — Organizations' use of GAI systems may a…
When people use generative AI as a starting point rather than a final authority, the central question changes from “Was it correct?” to “Did it help someone accomplish a task?” Researchers, standards bodies, and organisations increasingly argue that generative AI should be evaluated through a broader set of measures that include usefulness, efficiency, creativity support, revision effort, safety, and real-world outcomes rather than benchmark accuracy alone. [NIST Publications+2nae.edu]nvlpubs.nist.govNIST PublicationsArtificial Intelligence Risk Management Frameworkby N AI · 2024 · Cited by 134 — Organizations' use of GAI systems may a…
How Do You Judge a Useful AI Draft?
The challenge begins with the nature of the output itself. A prediction usually has a single target outcome that can be compared against ground truth. A generated draft may have many acceptable versions.
Consider an email draft. Two different responses can both be effective even if they use different wording. The same applies to reports, software code, marketing copy, lesson plans, or brainstorming ideas. Because there is often no single “correct” output, traditional accuracy measures capture only part of what users actually value. [awslabs.github.io]awslabs.github.ioModel EvaluationGenerative AI AtlasModel evaluation provides systematic approaches to assess LLM performance across various dimensions including accuracy…
This is one reason organisations such as the US National Institute of Standards and Technology (NIST) have developed specialised guidance for generative AI evaluation. Their work emphasises broader testing of capability, trustworthiness, human oversight, and real-world performance rather than relying on a single score. [NIST+2NIST Publications]nist.govArtificial Intelligence Risk Management Frameworkby C Autio · 2024 · Cited by 135 — This document is a cross-sectoral profile of and…
A draft can therefore succeed even when it is imperfect. If it saves substantial time, helps organise ideas, or provides a useful structure for further work, many users will consider it valuable despite requiring edits.
Why Accuracy Metrics Are Not Enough
Accuracy remains necessary because factual errors, fabricated references, and incorrect reasoning can create serious problems. However, generative systems introduce additional dimensions that matter just as much in practice.
A useful evaluation may need to ask questions such as:
- How much time did the draft save?
- How many edits were required before use?
- Did it help the user reach a better outcome?
- Was the content appropriate for the audience?
- Did it introduce safety, legal, or reputational risks?
- Did it support or hinder creative thinking?
Research on workplace adoption increasingly focuses on productivity and workflow outcomes rather than benchmark scores alone. Microsoft’s studies of AI-assisted work, for example, examine how generative systems affect efficiency, quality, and day-to-day knowledge work rather than simply measuring model correctness. [Microsoft+2arXiv]microsoft.comgenerative ai in real world workplacesGenerative AI in Real-World Workplaces25 Jul 2024 — This report presents the most recent findings of Microsoft's research initia…
This reflects a practical reality: a model that scores highly on laboratory benchmarks may still provide little value if its outputs require extensive correction or fail to fit real organisational needs. Researchers have described this as a gap between benchmark performance and real-world utility. [arXiv]arxiv.orgOpen source on arxiv.org.
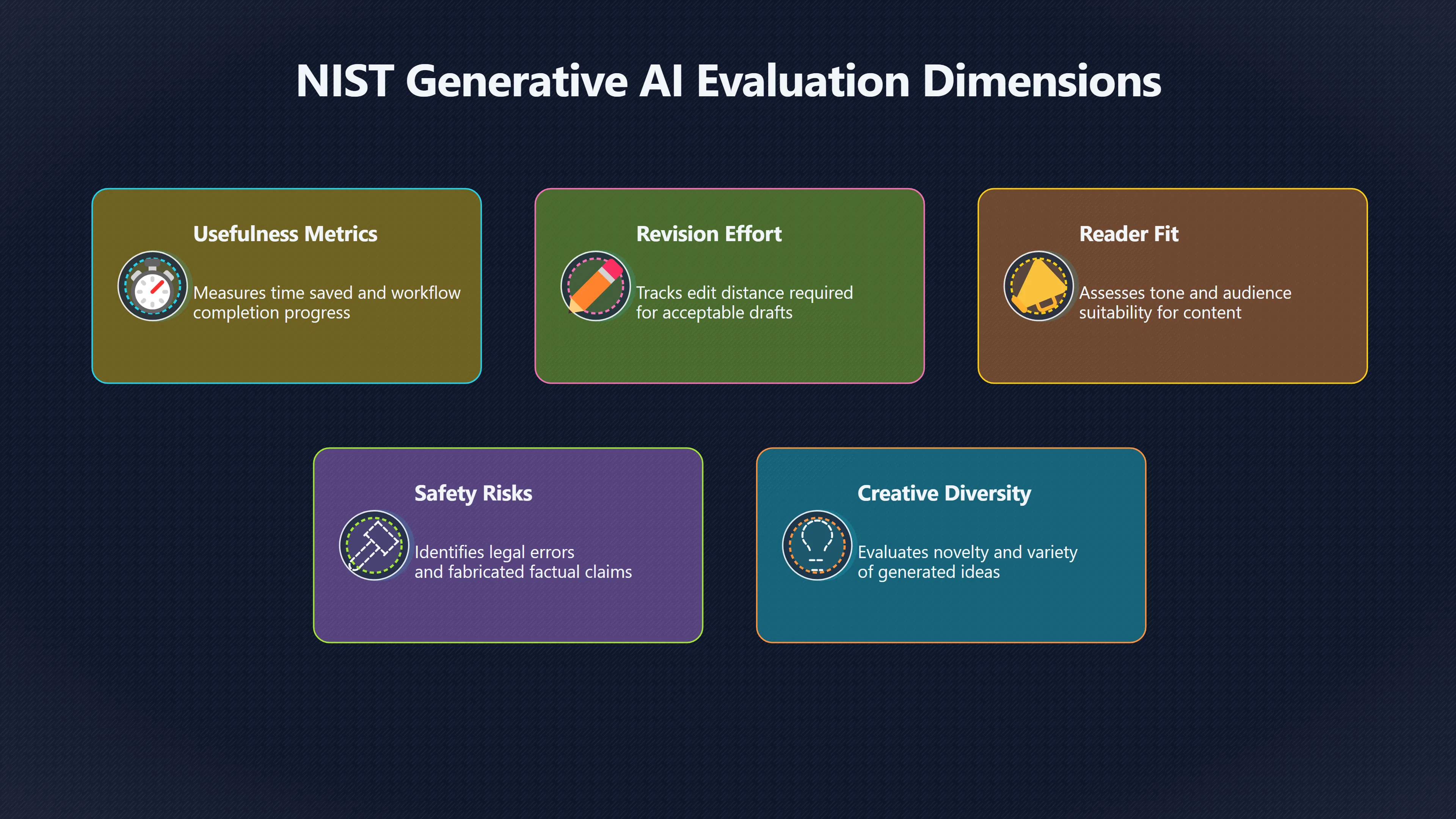
Usefulness, Revision, and Reader Fit
One of the most distinctive measures for generative AI is revision effort.
If a person receives a draft and only needs to make minor adjustments, the system has created substantial value. If every paragraph must be rewritten, the same draft may have little practical benefit even if many sentences are technically accurate.
This shifts attention toward measures such as:
Usefulness. Did the output help the user move forward with a task?
Edit distance. How much rewriting was required before the draft became acceptable?
Reader fit. Did the content match the intended audience, tone, and purpose?
Workflow impact. Did it reduce effort, speed up completion, or improve quality?
Studies of workplace AI adoption frequently find that users evaluate systems according to perceived usefulness, ease of use, and support for specific tasks rather than purely technical measures of correctness. [arXiv+2digital.gov.au]arxiv.orgGenerative AI in Knowledge Work: Perception, Usefulness, and Acceptance of Microsoft 365 CopilotFebruary 20, 2026…
This explains why organisations often conduct human evaluations alongside automated benchmarks. Human reviewers can judge clarity, relevance, persuasiveness, and suitability in ways that simple accuracy metrics cannot.

Creativity Creates a New Evaluation Problem
Generative AI is frequently used for idea generation and creative work, which introduces another challenge: originality.
A creative suggestion does not have a single correct answer. In many situations, users want surprising, diverse, and inspiring ideas rather than predictable ones.
Research examining creativity and generative AI suggests that AI-assisted users often produce stronger creative outputs than unaided users. At the same time, some studies indicate that AI assistance can reduce diversity by encouraging many users toward similar ideas. [arXiv]arxiv.orgGenerative AI and Creativity: A Systematic Literature Review and Meta-AnalysisMay 22, 2025…
This creates a trade-off that traditional accuracy measures cannot capture. An AI system might generate polished and coherent ideas while simultaneously narrowing the range of possible solutions.
As a result, evaluations increasingly examine:
- Novelty of ideas
- Diversity of outputs
- Support for human creativity [arxiv.org]arxiv.orgMeasuring Creativity in the Age of Generative AI: Distinguishing Human and AI-Generated Creative Performance in Hiring and Talent Sy…
- Distinctiveness rather than mere fluency
In creative and knowledge work, these qualities may matter as much as factual correctness. [arXiv]arxiv.orgGenerative AI and Creativity: A Systematic Literature Review and Meta-AnalysisMay 22, 2025…
When a Good Starting Point Is Still Risky
The fact that a draft is useful does not mean it is safe.
Generative AI can produce convincing but inaccurate information. A draft that appears professional may still contain fabricated facts, misleading claims, or subtle errors. Because generated content often resembles human writing, users may overestimate its reliability. NIST’s generative AI guidance highlights risks related to information integrity, human oversight, and trustworthiness that require ongoing evaluation beyond simple performance scores. [NIST+2NIST Publications]nist.govArtificial Intelligence Risk Management Frameworkby C Autio · 2024 · Cited by 135 — This document is a cross-sectoral profile of and…
This means successful evaluation must balance two questions:
- Did the system help the user accomplish a task?
- Did it do so without creating unacceptable risks?
A draft that saves thirty minutes but introduces a legal error may ultimately be a poor result. Conversely, a cautious draft that requires minor editing but avoids serious mistakes may be more valuable in practice.
For many organisations, the best success measures therefore combine productivity indicators with quality, safety, and human-review requirements. [NIST Publications+2NIST]nvlpubs.nist.govNIST PublicationsArtificial Intelligence Risk Management Frameworkby N AI · 2024 · Cited by 134 — Organizations' use of GAI systems may a…

The Shift From Model Performance to Human Outcomes
The deepest change in generative AI evaluation is a shift from measuring the model alone to measuring what happens when people use it.
Traditional AI evaluation often asks whether the system made the right prediction. Generative AI evaluation increasingly asks whether people achieved better outcomes because the system was available.
That may include faster completion of work, improved communication, better brainstorming, higher-quality documents, or reduced effort. Emerging research argues that long-term utility and human outcomes are often more meaningful measures than isolated benchmark scores because generative AI functions as part of a human–AI workflow rather than as an independent decision-maker. [arXiv]arxiv.orgOpen source on arxiv.org.
This is why AI drafts feel different from AI predictions. A prediction succeeds when it is correct. A draft succeeds when it helps a person create something better, faster, or more effectively—while remaining trustworthy enough to use. Measuring that broader contribution requires new success measures that extend well beyond accuracy alone. [Microsoft+2awslabs.github.io]microsoft.comgenerative ai in real world workplacesGenerative AI in Real-World Workplaces25 Jul 2024 — This report presents the most recent findings of Microsoft's research initia…
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: nvlpubs.nist.gov
Link: https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdfSource snippet
NIST PublicationsArtificial Intelligence Risk Management Frameworkby N AI · 2024 · Cited by 134 — Organizations' use of GAI systems may a...
-
Source: nae.edu
Title: toward an evaluation science for generative ai systems
Link: https://www.nae.edu/338231/toward-an-evaluation-science-for-generative-ai-systemsSource snippet
15 Apr 2025 — In particular, we present three key lessons: Evaluation metrics must be applicable to real-world performance, metrics must...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2605.06856 -
Source: awslabs.github.io
Title: Model Evaluation
Link: https://awslabs.github.io/generative-ai-atlas/topics/2_0_technical_foundations_and_patterns/2_6_model_evaluation_and_selection_criteria/2_6_1_model_evaluation/2_6_1_model_evaluation.htmlSource snippet
Generative AI AtlasModel evaluation provides systematic approaches to assess LLM performance across various dimensions including accuracy...
-
Source: nist.gov
Link: https://www.nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligenceSource snippet
Artificial Intelligence Risk Management Frameworkby C Autio · 2024 · Cited by 135 — This document is a cross-sectoral profile of and...
-
Source: ai-challenges.nist.gov
Title: AI Challenge Problems Gen AI
Link: https://ai-challenges.nist.gov/genaiSource snippet
GenAI Ongoing Evaluations. NIST GenAI program provides rigorous, science...Read more...
-
Source: microsoft.com
Title: generative ai in real world workplaces
Link: https://www.microsoft.com/en-us/research/publication/generative-ai-in-real-world-workplaces/Source snippet
Generative AI in Real-World Workplaces25 Jul 2024 — This report presents the most recent findings of Microsoft's research initia...
-
Source: arxiv.org
Link: https://arxiv.org/html/2504.11436v1Source snippet
Shifting Work Patterns with Generative AI †14 Apr 2025 — We present evidence on how generative AI changes the work patterns of knowledge...
-
Source: digital.gov.au
Link: https://www.digital.gov.au/initiatives/copilot-trial/microsoft-365-copilot-evaluation-report-full/productivitySource snippet
Full report – productivityThis section outlines the impact of Microsoft 365 Copilot on trial participants' perceived productivity in term...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2602.18576Source snippet
Generative AI in Knowledge Work: Perception, Usefulness, and Acceptance of Microsoft 365 CopilotFebruary 20, 2026...
Published: February 20, 2026
-
Source: arxiv.org
Link: https://arxiv.org/abs/2505.17241Source snippet
Generative AI and Creativity: A Systematic Literature Review and Meta-AnalysisMay 22, 2025...
Published: May 22, 2025
-
Source: arxiv.org
Link: https://arxiv.org/abs/2604.19799Source snippet
Measuring Creativity in the Age of Generative AI: Distinguishing Human and AI-Generated Creative Performance in Hiring and Talent Sy...
-
Source: nist.gov
Link: https://www.nist.gov/itl/ai-risk-management-frameworkSource snippet
iated with artificial intelligence (AI).Read more...
-
Source: nist.gov
Title: 2025 nist genai text challenge evaluation plan
Link: https://www.nist.gov/publications/2025-nist-genai-text-challenge-evaluation-planSource snippet
by S Seo · 2025 — The NIST Generative AI (GenAI) Text Challenge is an evaluation program designed to probe the capabilities and limitatio...
-
Source: ai-challenges.nist.gov
Link: https://ai-challenges.nist.gov/t2tSource snippet
nist.govGenAI: Text-to-Text (T2T) - NIST AI ChallengesMay 1, 2024 — The Text-to-Text Discriminators (T2T-D) task is to detect if a target...
Published: May 1, 2024
-
Source: microsoft.com
Title: New Future Of Work Report 2025
Link: https://www.microsoft.com/en-us/research/wp-content/uploads/2025/12/New-Future-Of-Work-Report-2025.pdfSource snippet
16 Dec 2025 — AI delivers substantial gains in individual productivity. AI can bridge gaps of time, distance, and scale, but only if buil...
-
Source: microsoft.com
Title: lee 2025 ai critical thinking survey
Link: https://www.microsoft.com/en-us/research/wp-content/uploads/2025/01/lee_2025_ai_critical_thinking_survey.pdfSource snippet
The rise of Generative AI (GenAI) in knowledge workflows raises questions about its impact on critical thinking skills and practices.Read...
-
Source: microsoft.com
Title: A I and Productivity Report
Link: https://www.microsoft.com/en-us/research/wp-content/uploads/2023/12/ai-and-productivity-report-first-edition.pdfSource snippet
AI and Productivity Report - First Editionby A Cambon · Cited by 70 — This report presents the initial findings of Microsoft's research i...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/blacktaylor_just-finished-microsoft-researchs-new-future-activity-7440148157646237696-ScFpSource snippet
Microsoft Research Future of Work Report 202583% of employees said AI increased their workload. Time spent on communication more than dou...
Additional References
-
Source: modelop.com
Link: https://www.modelop.com/ai-governance/ai-regulations-standards/nist-ai-rmfSource snippet
NIST AI RMFThe framework emphasizes managing AI risks in terms of likelihood and severity of harm, including unintended, negative outcome...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/asteviebergman_towards-best-practices-for-automated-benchmark-activity-7425259459934953474-snqYSource snippet
NIST Releases Draft AI Evaluation Practices for Public...It resolves the 95% paradox because you don't need humans to catch the 5% if yo...
-
Source: hyperproof.io
Link: https://hyperproof.io/navigating-the-nist-ai-risk-management-framework/Source snippet
Navigating the NIST AI Risk Management FrameworkUnderstand the NIST AI Risk Management Framework and learn how to govern AI risk, align s...
-
Source: teknowledge.com
Link: https://teknowledge.com/insights/closing-the-ai-execution-gap-what-microsofts-research-means-for-enterprise-ai-success/Source snippet
What Microsoft's Research Means For Enterprise AI SuccessThe Microsoft AI research reinforces what we've seen in the field: closing the g...
-
Source: medium.com
Link: https://medium.com/%40vfcarida/a-strategic-field-guide-for-generative-ai-and-agent-evaluation-techniques-metrics-and-maturity-e425b394181eSource snippet
A Strategic Field Guide for Generative AI and Agent...Key metrics include [3]:. · Accuracy: the proportion of correct predictions...
-
Source: unece.org
Link: https://unece.org/sites/default/files/2025-09/Generative%20AI%20for%20Official%20Statistics%20HLG-MOS%20Report.pdf -
Source: clarivate.com
Link: https://clarivate.com/academia-government/blog/evaluating-the-quality-of-generative-ai-output-methods-metrics-and-best-practices/Source snippet
How to Evaluate Generative AI Output Effectively6 May 2025 — Learn how to evaluate generative AI output effectively using the right metho...
Published: May 2025
-
Source: epic.org
Title: comments to nist on managing the risks of misuse with ai foundation models
Link: https://epic.org/documents/epic-comments-to-nist-on-managing-the-risks-of-misuse-with-ai-foundation-models/Source snippet
EPIC Comments to NIST on Managing the Risks of Misuse...Sep 9, 2024 — EPIC reemphasizes our call for NIST and its affiliated entities to...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=hRgcLeYHAGwSource snippet
Evaluating GenAI Products Beyond Accuracy | Amazon AI...Evaluating GenAI: Why Accuracy is Only Half the Battle Welcome to "AI Product St...
-
Source: fedscoop.com
Title: nist launches genai evaluation program releases draft ai publications
Link: https://fedscoop.com/nist-launches-genai-evaluation-program-releases-draft-ai-publications/Source snippet
NIST launches GenAI evaluation program, releases draft...Apr 29, 2024 — “One of the program's goals is to help people determine whether...
Topic Tree