Within Web Filters
When safety filters erase real communities
Profanity filters can remove ordinary discussions of gender, sexuality, race, and religion when identity terms overlap with block lists.
On this page
- Why identity terms trigger automated filters
- How legitimate discussion gets mistaken for abuse
- What better filtering would need to preserve
Page outline Jump by section
Introduction
Before a language model learns from web text, that text is usually filtered. One common method is the block list: a list of words that automatically causes a document to be removed. The idea is simple—exclude pornography, slurs, or other unwanted material—but language does not separate neatly into “safe” and “unsafe” words. Many terms that appear on block lists are also used in ordinary discussions of gender, sexuality, race, religion, health, and community identity. As a result, filtering systems designed to remove harmful content can also erase large amounts of legitimate conversation about real people and real communities. Research on major AI training datasets has repeatedly shown that this effect is not theoretical: identity-related discussions are often removed at disproportionately high rates when simple word-based filters are used. [Maarten Sap]maartensap.comMaarten Sap A Case Study on the Colossal Clean Crawled CorpusMaarten SapA Case Study on the Colossal Clean Crawled CorpusSeptember 30, 2021 — by J Dodge · Cited by 875 — mentions of sexual orientati…

Why identity terms trigger automated filters
Block-list filtering operates through a straightforward rule: if a document contains a listed term, the document is rejected. This approach is attractive because it is fast, easy to implement, and can process billions of web pages. The weakness is that the filter often ignores context. It reacts to the presence of a word rather than the meaning of the surrounding discussion. [ACL Anthology]aclanthology.orgACL Anthology A Case Study on the Colossal Clean Crawled CorpusACL AnthologyA Case Study on the Colossal Clean Crawled CorpusSeptember 10, 2021 — by J Dodge · 2021 · Cited by 876 — NOBLOCKLIST, which…
Identity discussions are especially vulnerable because many communities use language that also appears in lists intended to catch offensive or sexual content. Terms related to sexual orientation, gender identity, anatomy, religion, ethnicity, or reclaimed slurs can appear in:
- Educational material.
- Personal narratives.
- Health information.
- Community forums.
- News reporting.
- Civil-rights discussions.
A filter that cannot distinguish between “a discussion about a group” and “an attack on a group” may remove both. The result is not merely the loss of offensive content; it is the loss of context, self-description, and community knowledge. [Maarten Sap]maartensap.comMaarten Sap A Case Study on the Colossal Clean Crawled CorpusMaarten SapA Case Study on the Colossal Clean Crawled CorpusSeptember 30, 2021 — by J Dodge · Cited by 875 — mentions of sexual orientati…
The problem becomes more severe when a single word has multiple meanings. A term may be used as a slur in one context, as a reclaimed identity label in another, and as a neutral descriptive term in a third. Word-level filtering treats all uses as identical. [Dr Alan D. Thompson – LifeArchitect.ai]s10251.pcdn.coDr Alan DThompson – LifeArchitect.aiarXiv:2104.08758v1 [cs.CL] 18 Apr 2021April 20, 2021 — 18 Apr 2021 — As such, blocklist filtering risks removi…
How legitimate discussion gets mistaken for abuse
The best-known evidence comes from analyses of the Colossal Clean Crawled Corpus (C4), a major web dataset used in language-model research. Researchers examined the effects of a block list that removed any document containing words from a large list of supposedly offensive terms. Their audit found that mentions of sexual orientations such as “lesbian”, “gay”, “homosexual”, and “bisexual” were among the identity references most likely to be filtered out. [Maarten Sap]maartensap.comMaarten Sap A Case Study on the Colossal Clean Crawled CorpusMaarten SapA Case Study on the Colossal Clean Crawled CorpusSeptember 30, 2021 — by J Dodge · Cited by 875 — mentions of sexual orientati…
Importantly, many of the removed documents were not pornography, harassment, or hate speech. Researchers found substantial numbers of non-offensive and non-sexual documents among pages mentioning these identities. The filter was responding to vocabulary rather than harmful intent. [CSE UST]home.cse.ust.hklec11 ust F24CSE USTMSBD 6000N Presentation22 Oct 2024 — Compute the PMI between an identity occurring and being filtered by blocklist. ● sexual orien…
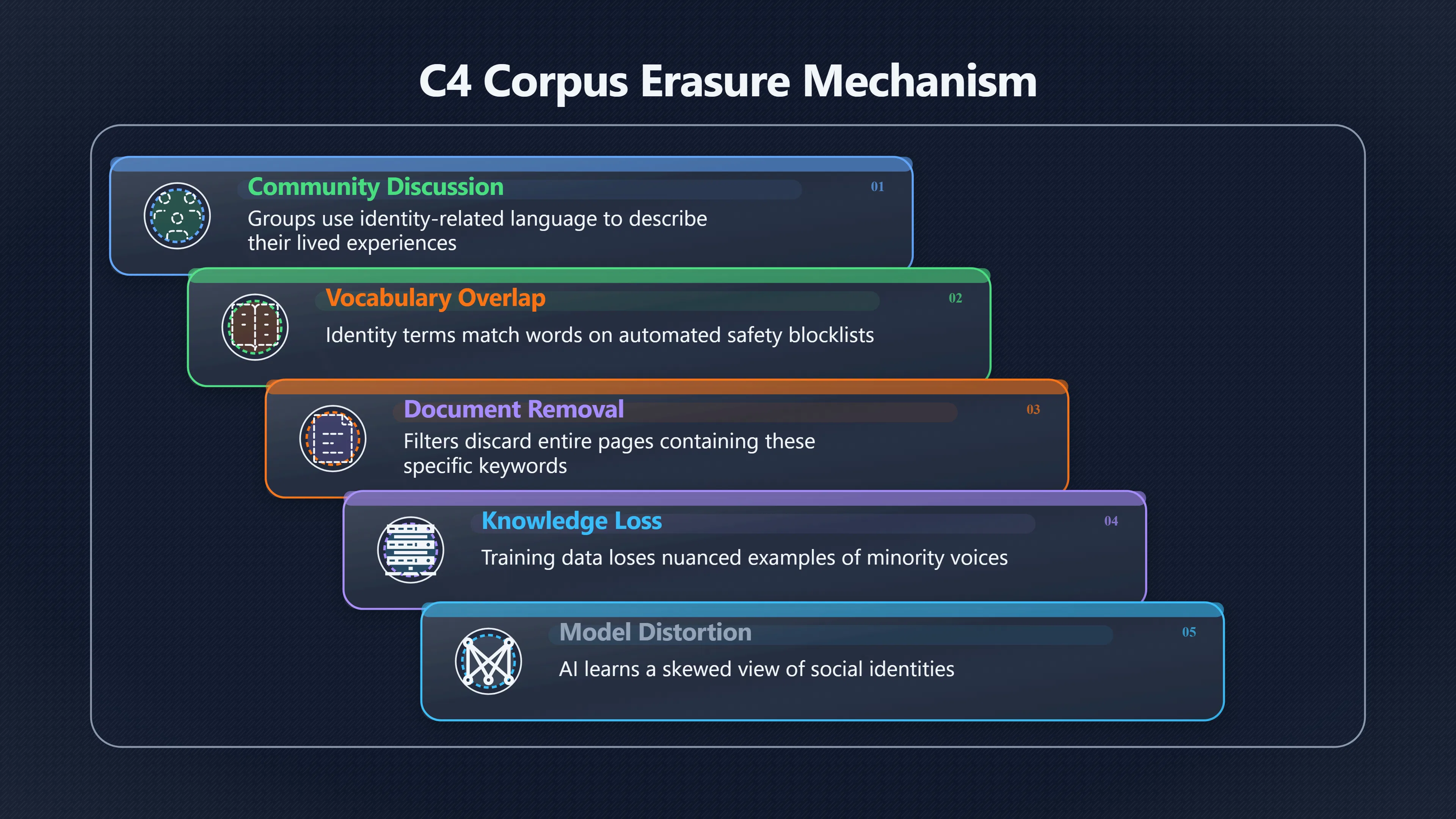
This creates a specific mechanism of erasure:
- A community discusses itself using identity-related language.
- Some of that language overlaps with words considered risky by a block list.
- Entire documents are removed.
- The remaining dataset contains fewer examples of those communities speaking in their own voices.
- Models trained on the filtered dataset learn less about those communities.
The process is largely invisible because users only see the final model, not the millions of documents discarded during training-data preparation. [ar5iv]ar5iv.labs.arxiv.orgar5iv A Case Study on the Colossal Clean Crawled Corpusblocklist filtering disproportionately removes text from and about minority individuals…. Bender, Timnit Gebru, Angelina McMillan-Majo…

Why the effect falls unevenly across communities
A key finding from dataset audits is that filtering does not affect all groups equally. Researchers studying C4 found that documents associated with minority communities and certain English dialects were removed at substantially higher rates than text associated with mainstream written English. [Dr Alan D. Thompson – LifeArchitect.ai]s10251.pcdn.coDr Alan DThompson – LifeArchitect.aiarXiv:2104.08758v1 [cs.CL] 18 Apr 2021April 20, 2021 — 18 Apr 2021 — As such, blocklist filtering risks removi…
Part of the reason is linguistic. Communities often develop specialised vocabularies, reclaimed terms, or conversational styles that differ from formal language. A block list built without considering these uses may treat ordinary community speech as suspicious. Researchers have argued that this can systematically reduce the presence of minority voices in training data even when no explicit decision was made to target those groups. [Dr Alan D. Thompson – LifeArchitect.ai]s10251.pcdn.coDr Alan DThompson – LifeArchitect.aiarXiv:2104.08758v1 [cs.CL] 18 Apr 2021April 20, 2021 — 18 Apr 2021 — As such, blocklist filtering risks removi…
The issue extends beyond sexuality. Studies and audits of filtering systems have repeatedly raised concerns about disproportionate effects on discussions involving gender, race, religion, nationality, and other protected identities. More recent research on pre-training filters and moderation systems continues to find elevated false-positive rates for content discussing marginalised groups, particularly when filters rely heavily on lexical cues rather than context. [arXiv+2ResearchGate]arxiv.orgarXiv Who's in and who's out?A case study of multimodal CLIP-…9 Oct 2024 — Dodge et al. (2021) also examine the blocklist filter used to create the popular C4 data…
What this means for language models
Language models learn statistical patterns from whatever survives data preparation. If discussions about certain identities are removed more frequently than others, the model receives a distorted picture of how people talk about those identities. [ar5iv]ar5iv.labs.arxiv.orgar5iv A Case Study on the Colossal Clean Crawled Corpusblocklist filtering disproportionately removes text from and about minority individuals…. Bender, Timnit Gebru, Angelina McMillan-Majo…
This does not necessarily mean the model becomes overtly biased in a single, obvious way. Instead, the effects can appear as:
- Less familiarity with community-specific language.
- Reduced ability to answer questions about certain identities.
- Missing cultural context.
- Greater uncertainty when discussing underrepresented groups.
- Increased reliance on stereotypes because nuanced examples were filtered out.
In other words, filtering changes not only what harmful content is removed but also what knowledge remains available for learning. The model’s understanding of society becomes partly shaped by the assumptions embedded in the filter itself. [ar5iv]ar5iv.labs.arxiv.orgar5iv A Case Study on the Colossal Clean Crawled Corpusblocklist filtering disproportionately removes text from and about minority individuals…. Bender, Timnit Gebru, Angelina McMillan-Majo…
What better filtering would need to preserve
The lesson from these findings is not that all filtering is harmful. Large web datasets genuinely contain pornography, spam, harassment, and hate speech that many developers want to reduce. The challenge is distinguishing harmful use from ordinary discussion. [Knowing Machines]knowingmachines.orgKnowing MachinesThe case of 'Colossal Cleaned Common Crawl' (C4)Common Crawl is known to include pornographic and abusive content, hate s…
More sophisticated approaches attempt to preserve context rather than relying on single words. Instead of asking whether a document contains a particular term, they ask questions such as:
- Is the document attacking a group or describing one?
- Is the language educational, conversational, journalistic, or abusive?
- Is a potentially offensive term being quoted, reclaimed, or used as a slur?
- Does the surrounding text indicate harm or ordinary discussion?
Researchers increasingly argue that dataset documentation, auditing, and context-sensitive filtering are necessary because simple block lists can hide systematic exclusions that are difficult to detect later. [ACL Anthology+2arXiv]aclanthology.orgACL Anthology Data Statements for Natural Language ProcessingACL AnthologyData Statements for Natural Language ProcessingMarch 1, 2019 — by EM Bender · Cited by 1499 — In this paper, we propose data…
For understanding artificial intelligence, the important point is that a block list is not merely a safety tool. It is also a mechanism that decides which conversations survive long enough to become part of a model’s understanding of the world. When identity-related language overlaps with blocked vocabulary, the filter can unintentionally erase evidence of entire communities, altering what the model learns before training even begins. [Maarten Sap+2ar5iv]maartensap.comMaarten Sap A Case Study on the Colossal Clean Crawled CorpusMaarten SapA Case Study on the Colossal Clean Crawled CorpusSeptember 30, 2021 — by J Dodge · Cited by 875 — mentions of sexual orientati…

Amazon book picks
Further Reading
Books and field guides related to When safety filters erase real communities. Use these as the next step if you want deeper reading beyond the article.
Algorithms of Oppression
Shows how automated information systems can erase or distort communities.
Weapons of Math Destruction
Gives readers a broad framework for understanding harmful automated decisions.
Automating Inequality
Shows how automated systems can disproportionately affect vulnerable communities.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: arxiv.org
Link: https://arxiv.org/abs/2104.08758Source snippet
A Case Study on the Colossal Clean Crawled Corpusby J Dodge · 2021 · Cited by 876 — In this work we provide some of the first documentati...
-
Source: arxiv.org
Link: https://arxiv.org/pdf/2108.07790Source snippet
Mitigating harm in language models with conditional-...by H Ngo · 2021 · Cited by 49 — After applying a word-level blocklist3 to filter...
-
Source: ar5iv.labs.arxiv.org
Title: ar5iv A Case Study on the Colossal Clean Crawled Corpus
Link: https://ar5iv.labs.arxiv.org/html/2104.08758Source snippet
blocklist filtering disproportionately removes text from and about minority individuals.... Bender, Timnit Gebru, Angelina McMillan-Majo...
-
Source: s10251.pcdn.co
Title: Dr Alan D
Link: https://s10251.pcdn.co/pdf/2021-dodge-c4.pdfSource snippet
Thompson – LifeArchitect.aiarXiv:2104.08758v1 [cs.CL] 18 Apr 2021April 20, 2021 — 18 Apr 2021 — As such, blocklist filtering risks removi...
Published: April 20, 2021
-
Source: home.cse.ust.hk
Title: lec11 ust F24
Link: https://home.cse.ust.hk/~cktang/msbd6000n/Password_Only/lec11-ust-F24.pdfSource snippet
CSE USTMSBD 6000N Presentation22 Oct 2024 — Compute the PMI between an identity occurring and being filtered by blocklist. ● sexual orien...
-
Source: researchgate.net
Title: 350991473 Documenting the English Colossal Clean Crawled Corpus
Link: https://www.researchgate.net/publication/350991473_Documenting_the_English_Colossal_Clean_Crawled_CorpusSource snippet
Documenting the English Colossal Clean Crawled Corpus18 Apr 2021 — In this work we provide the first documentation for the Colossal Clean...
-
Source: arxiv.org
Title: arXiv Who’s in and who’s out?
Link: https://arxiv.org/html/2405.08209v2Source snippet
A case study of multimodal CLIP-...9 Oct 2024 — Dodge et al. (2021) also examine the blocklist filter used to create the popular C4 data...
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/406039756_Epistemic_Injustice_in_Language_Models_An_Audit_of_Pretraining_Filters_and_GuardrailsSource snippet
An Audit of Pretraining Filters and Guardrails7 Jun 2026 — Our analysis shows that filtering and guardrail [decisions]({{ 'decisions/' | relative_url }}) are strongly associa...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2105.02732 -
Source: arxiv.org
Link: https://arxiv.org/html/2606.05936v1Source snippet
An Audit of Pretraining Filters and Guardrails4 Jun 2026 — Dodge et al. (2021) document that blocklists of this kind suppress non-pornogr...
-
Source: arxiv.org
Link: https://arxiv.org/html/2410.22587v2 -
Source: researchgate.net
Title: What’s in the Box?
Link: https://www.researchgate.net/publication/353489691_What%27s_in_the_Box_An_Analysis_of_Undesirable_Content_in_the_Common_Crawl_CorpusSource snippet
An Analysis of Undesirable Content...Dodge et al. (2021) documented the C4 corpus its filtering process correlates with a reduction of t...
-
Source: maartensap.com
Title: Maarten Sap A Case Study on the Colossal Clean Crawled Corpus
Link: https://maartensap.com/pdfs/dodge2021documentingC4.pdfSource snippet
Maarten SapA Case Study on the Colossal Clean Crawled CorpusSeptember 30, 2021 — by J Dodge · Cited by 875 — mentions of sexual orientati...
Published: September 30, 2021
-
Source: aclanthology.org
Title: ACL Anthology A Case Study on the Colossal Clean Crawled Corpus
Link: https://aclanthology.org/2021.emnlp-main.98.pdfSource snippet
ACL AnthologyA Case Study on the Colossal Clean Crawled CorpusSeptember 10, 2021 — by J Dodge · 2021 · Cited by 876 — NOBLOCKLIST, which...
Published: September 10, 2021
-
Source: knowingmachines.org
Link: https://knowingmachines.org/publications/9-ways-to-see/essays/c4Source snippet
Knowing MachinesThe case of 'Colossal Cleaned Common Crawl' (C4)Common Crawl is known to include pornographic and abusive content, hate s...
-
Source: aclanthology.org
Title: ACL Anthology Data Statements for Natural Language Processing
Link: https://aclanthology.org/anthology-files/pdf/Q/Q18/Q18-1041.pdfSource snippet
ACL AnthologyData Statements for Natural Language ProcessingMarch 1, 2019 — by EM Bender · Cited by 1499 — In this paper, we propose data...
Published: March 1, 2019
Additional References
-
Source: semanticscholar.org
Link: https://www.semanticscholar.org/paper/Documenting-the-English-Colossal-Clean-Crawled-Dodge-Sap/40c3327a6ddb0603b6892344509c7f428ab43d81Source snippet
Documenting the English Colossal Clean Crawled CorpusThis work provides the first documentation for the Colossal Clean Crawled Corpus (C4...
-
Source: sh-tsang.medium.com
Link: https://sh-tsang.medium.com/review-documenting-largewebtext-corpora-a-case-study-on-the-colossal-clean-crawled-corpus-0bcc6554e4b6Source snippet
Large Webtext Corpora: A Case Study on the...The English Colossal Clean Crawled Corpus (C4) is created by taking the April 2019 snapshot...
Published: April 2019
-
Source: github.com
Link: https://github.com/allenai/c4-documentationSource snippet
allenai/c4-documentationThis is a companion website for our paper Documenting the English Colossal Clean Crawled Corpus. We present some...
-
Source: unite.ai
Title: minority voices filtered out of google natural language processing models
Link: https://www.unite.ai/minority-voices-filtered-out-of-google-natural-language-processing-models/Source snippet
Minority Voices 'Filtered' Out of Google Natural Language...24 Sept 2021 — The report asserts that the Colossal Clean Crawled Corpus ('C...
-
Source: deepai.org
Title: documenting the english colossal clean crawled corpus
Link: https://www.deepai.org/publication/documenting-the-english-colossal-clean-crawled-corpusSource snippet
18 Apr 2021 — In this work we provide the first documentation for the Colossal Clean Crawled Corpus (C4; Raffel et al., 2020), a dataset...
-
Source: ojs.aaai.org
Title: Publications What Are They Filtering Out?
Link: https://ojs.aaai.org/index.php/AAAI/article/view/41279/45240Source snippet
An Experimental Benchmark...by MA Stranisci · 2026 · Cited by 3 — Research on data filtering strategies for harm reduction has been prop...
-
Source: juser.fz-juelich.de
Title: Bachelorarbeit Rahmdel 424069
Link: https://juser.fz-juelich.de/record/1041549/files/Bachelorarbeit_Rahmdel_424069.pdfSource snippet
Linguistic Proximity in C4 [Multilingual]({{ 'language-bias/' | relative_url }}) Data through...by S Rahmdel · 2025 · Cited by 1 — This thesis investigates the proximity of diff...
-
Source: thegradient.pub
Link: https://thegradient.pub/the-benderrule-on-naming-the-languages-we-study-and-why-it-matters/Source snippet
The #BenderRule: On Naming the Languages We Study...14 Sept 2019 — High resource languages constitute a short list starting with English...
-
Source: antmarakis.github.io
Title: documenting large corpora
Link: https://antmarakis.github.io/2021/documenting_large_corpora/Source snippet
Documenting Large Webtext Corpora21 Oct 2021 — The Colossal Clean Crawled Corpus (C4) is a corpus curated for pretraining large language...
-
Source: wik.org
Title: Working paper No12
Link: https://www.wik.org/fileadmin/user_upload/Unternehmen/Veroeffentlichungen/Working_Papers/2025/WIK-Working_paper_No12.pdfSource snippet
A cross-domain framework for auditing algorithmsby F Harpenau · 2025 — This may include varying model assumptions, specifications, and da...
Topic Tree