Within Parallel scale
Why attention could train all tokens at once
Self-attention turns sentence processing into parallel matrix work, avoiding the step-by-step bottleneck that slowed recurrent models.
On this page
- The recurrent bottleneck in sequence models
- How self attention becomes matrix multiplication
- Why parallel token processing changed training speed
Page outline Jump by section
Introduction
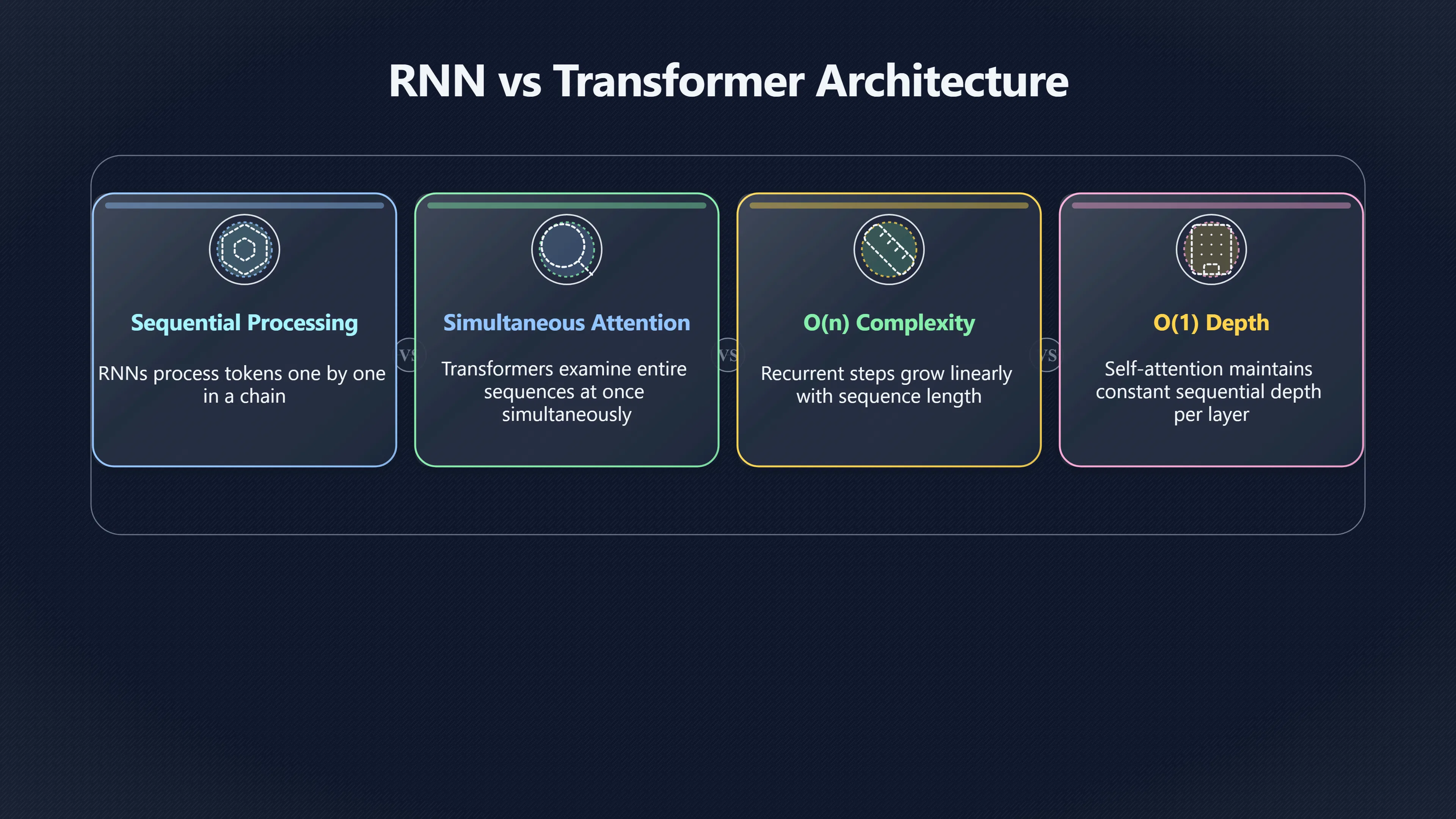
A key reason Transformers became scalable is that self-attention removed the step-by-step processing constraint that defined recurrent neural networks (RNNs) and long short-term memory networks (LSTMs). In a recurrent model, each token must wait for the previous token’s computation to finish before it can be processed. Self-attention replaces that chain with operations that can examine an entire sequence simultaneously. Because those operations are largely implemented as matrix multiplications, they match the strengths of GPUs and other AI accelerators, which are designed to perform many calculations in parallel. The result is not merely a modest speed improvement: it changes how effectively additional hardware can be used, making it practical to train much larger models on much larger datasets. [arXiv]arxiv.orgAttention Is All You NeedWe propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispen…

The recurrent bottleneck in sequence models
Recurrent networks process language as a sequence of dependent steps. When an RNN reads a sentence, the hidden state for token 20 depends on the hidden state produced for token 19, which depends on token 18, and so on. This creates a computational chain that cannot be broken during training. Even if thousands of processing cores are available, the model still has to advance through the sequence one position at a time. [Reddit]reddit.comIt's commonly said that transformers are more parallelizable…
This dependence limits hardware utilisation. Modern GPUs achieve their highest performance when they execute large blocks of mathematical operations simultaneously. Recurrent architectures force part of the workload into a serial process, leaving less opportunity to exploit massive parallel hardware. Researchers could process multiple training examples in a batch, but within each individual sequence the time-step dependency remained. [Reddit]reddit.comIt's commonly said that transformers are more parallelizable…
The problem becomes more severe as sequences grow longer. A sentence with 100 tokens requires roughly twice as many recurrent processing steps as a sentence with 50 tokens. Training speed therefore scales poorly because additional hardware cannot eliminate the need for sequential execution. [arXiv]arxiv.orgarXiv:1706.03762v7 [cs.CL] 2 Aug 2023June 12, 2017 — by A Vaswani · 2017 · Cited by 252179 — a self-attention layer connects all pos…
How self-attention becomes matrix multiplication
Self-attention approaches the same problem differently. Instead of carrying a hidden state forward token by token, every token creates query, key, and value representations. The model then computes relationships between all tokens in the sequence at once. These relationships can be expressed as large matrix operations rather than a chain of sequential updates. [arXiv]arxiv.orgAttention Is All You NeedWe propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispen…
From a hardware perspective, this is a crucial shift. Matrix multiplication is one of the most heavily optimised operations in modern computing. GPU architectures, tensor processors, and specialised AI accelerators are designed specifically to perform huge matrix calculations efficiently. Self-attention transforms language processing into exactly the type of workload these devices handle best. [Towards AI]towardsai.netThese innovations have …Read moreTowards AIA Deep Dive into the Revolutionary Transformer ArchitectureApril 10, 2025 — 10 Apr 2025 — Fully Parallelizable: The Transformer…
Instead of computing:
- Token 1, then token 2, then token 3, and so on,
the model computes:
- Relationships among all tokens simultaneously within a layer.
The computation still proceeds layer by layer, but the expensive token-level dependency disappears. This dramatically increases the amount of work that can be executed in parallel. [Reddit]reddit.comIt's commonly said that transformers are more parallelizable…

Why fewer sequential operations matter
The original Transformer paper highlighted a particularly important difference: self-attention requires a constant number of sequentially executed operations per layer, whereas recurrent layers require a number of sequential operations that grows with sequence length. In complexity terms, recurrent models need O(n) sequential steps for a sequence of length n, while self-attention can connect positions using O(1) sequential depth within a layer. [arXiv]arxiv.orgarXiv:1706.03762v7 [cs.CL] 2 Aug 2023June 12, 2017 — by A Vaswani · 2017 · Cited by 252179 — a self-attention layer connects all pos…
This distinction matters because training time is often determined less by total arithmetic and more by how much of that arithmetic can be parallelised. A model that performs many calculations simultaneously can finish sooner than a model that performs fewer calculations but must execute them one after another. [arXiv]arxiv.orgarXiv:1706.03762v7 [cs.CL] 2 Aug 2023June 12, 2017 — by A Vaswani · 2017 · Cited by 252179 — a self-attention layer connects all pos…
A useful analogy is a factory assembly line. An RNN resembles a process where each worker must wait for the previous worker to finish before starting. Self-attention resembles a process where many workers can operate on the same batch simultaneously and then combine their results. The total amount of work may still be substantial, but the waiting time is greatly reduced.
Why parallel token processing changed training speed
The practical effect was visible in the Transformer’s first major results. The authors reported that the architecture was substantially more parallelisable than recurrent alternatives and achieved state-of-the-art machine translation performance with comparatively low training cost. Their English–French translation system reached leading results after only a few days of training on eight GPUs, demonstrating that removing recurrence could translate directly into faster experimentation and faster model development. [arXiv]arxiv.orgarXiv[1706.03762] Attention Is All You Need12 Jun 2017 — We propose a new simple network architecture, the Transformer, based solely on a…
The advantage became even more important as models grew. When researchers discovered that larger models trained on larger datasets often produced better results, architectures that scaled efficiently across many GPUs gained a decisive advantage. Self-attention fit naturally into distributed training systems because matrix operations can be split across processors far more easily than long chains of recurrent updates. [Introl]introl.comHow Transformers replaced RNNs with parallelizable self-attentionTransformer Architecture: How Attention Changed AI | Introl BlogMay 2, 2025 — 2 May 2025 — The 2017 Attention Is All You Need paper…
This hardware compatibility helped transform scaling from a theoretical possibility into a practical engineering strategy. Instead of being constrained by sequential token processing, researchers could increasingly improve performance by adding computing resources and training data. [arXiv]arxiv.orgAttention Is All You NeedWe propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispen…

An important nuance: faster training does not mean cheaper attention
Self-attention is not universally more efficient in every respect. Standard attention compares every token with every other token, causing computation and memory use to grow rapidly as sequences become very long. This quadratic scaling has become one of the major challenges in modern Transformer design. [Reddit]reddit.comReddit[D] Attention layer complexity vs context lengthMarch 5, 2024 — The computational complexity of the attention layers scales quadrat…
However, this does not negate the training-speed advantage over recurrence. For the sentence lengths and representation sizes that dominated early machine translation tasks, the Transformer authors argued that self-attention layers were often faster than recurrent layers while also being far more parallelisable. [arXiv]arxiv.orgarXiv:1706.03762v7 [cs.CL] 2 Aug 2023June 12, 2017 — by A Vaswani · 2017 · Cited by 252179 — a self-attention layer connects all pos…
The result is a trade-off that shaped modern AI: self-attention may perform more pairwise comparisons, but those comparisons can be packaged into highly parallel matrix operations that accelerator hardware executes extremely efficiently. Recurrence performs fewer comparisons but forces them into a sequential chain that hardware cannot easily accelerate. [arXiv]arxiv.orgarXiv:1706.03762v7 [cs.CL] 2 Aug 2023June 12, 2017 — by A Vaswani · 2017 · Cited by 252179 — a self-attention layer connects all pos…
The mechanism that made scaling possible
The central reason self-attention trains faster than recurrence is therefore not that it performs less computation. It is that it reorganises sequence processing into a form that modern hardware can execute in parallel. Recurrent models tie each token to the completion of the previous token. Self-attention lets an entire sequence participate in the same computation at once. By converting language modelling into large-scale matrix operations and reducing sequential dependencies, Transformers unlocked far greater hardware utilisation and became dramatically easier to scale. [arXiv+2arXiv]arxiv.orgAttention Is All You NeedWe propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispen…
Amazon book picks
Further Reading
Books and field guides related to Why attention could train all tokens at once. Use these as the next step if you want deeper reading beyond the article.
Natural Language Processing with Transformers
Shows how self-attention enables scalable training.
Transformers for Machine Learning
Directly addresses self-attention and parallel computation.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: arxiv.org
Link: https://arxiv.org/html/1706.03762v7Source snippet
Attention Is All You NeedWe propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispen...
-
Source: arxiv.org
Link: https://arxiv.org/abs/1706.03762Source snippet
arXiv[1706.03762] Attention Is All You Need12 Jun 2017 — We propose a new simple network architecture, the Transformer, based solely on a...
-
Source: reddit.com
Link: https://www.reddit.com/r/MLQuestions/comments/14aedwk/why_is_it_said_that_the_transformer_is_more/Source snippet
It's commonly said that transformers are more parallelizable...
-
Source: arxiv.org
Link: https://arxiv.org/pdf/1706.03762Source snippet
arXiv:1706.03762v7 [cs.CL] 2 Aug 2023June 12, 2017 — by A Vaswani · 2017 · Cited by 252179 — a self-attention layer connects all pos...
Published: June 12, 2017
-
Source: introl.com
Title: How Transformers replaced RNNs with parallelizable self-attention
Link: https://introl.com/blog/the-transformer-revolution-how-attention-is-all-you-need-reshaped-modern-aiSource snippet
Transformer Architecture: How Attention Changed AI | Introl BlogMay 2, 2025 — 2 May 2025 — The 2017 Attention Is All You Need paper...
Published: May 2, 2025
-
Source: reddit.com
Link: https://www.reddit.com/r/MachineLearning/comments/1b77fnc/d_attention_layer_complexity_vs_context_length/Source snippet
Reddit[D] Attention layer complexity vs context lengthMarch 5, 2024 — The computational complexity of the attention layers scales quadrat...
Published: March 5, 2024
-
Source: reddit.com
Link: https://www.reddit.com/r/MachineLearning/comments/16l3vx2/discussion_question_on_the_paper_named/Source snippet
[Discussion] Question on the paper named, SELF...SELF-ATTENTION DOES NOT NEED O(n 2) it requires O(1) for a single query, it requires O...
-
Source: towardsai.net
Link: https://towardsai.net/p/[machine-learningSource snippet
Towards AIA Deep Dive into the Revolutionary Transformer ArchitectureApril 10, 2025 — 10 Apr 2025 — Fully Parallelizable: The Transformer...
Published: April 10, 2025
-
Source: pub.towardsai.net
Link: https://pub.towardsai.net/attention-is-all-you-need-a-deep-dive-into-the-revolutionary-transformer-architecture-52734fb355dcSource snippet
Deep Dive into the Revolutionary Transformer Architecture10 Apr 2025 — In the following sections, we will describe the Transformer, motiv...
Additional References
-
Source: apxml.com
Link: https://apxml.com/courses/foundations-transformers-architecture/chapter-6-advanced-architectural-variants-analysis/self-attention-complexitySource snippet
ApX Machine LearningComputational Complexity of Self-AttentionThe standard self-attention mechanism, while powerful, carries a significan...
-
Source: medium.com
Link: https://medium.com/%40mridulrao674385/attention-mechanism-complexity-analysis-7314063459b1Source snippet
Attention Mechanism Complexity Analysis | by Mridul RaoComplexity analysis is about estimating how the time required to execute an algori...
-
Source: note.com
Link: https://note.com/ysuie_o/n/na6f2e6583f2e?hl=enSource snippet
Attention is All You Need|fendoapThe Transformer is the first transduction model that relies entirely on self-attention to compute repres...
-
Source: research.google
Link: https://research.google/pubs/attention-is-all-you-need/Source snippet
Google ResearchAttention is All You NeedWe propose a new simple network architecture, the Transformer, based solely on attention mechanis...
-
Source: medium.com
Link: https://medium.com/%40ding.zhongqiang/recurrent-neural-networks-and-transformers-b1cdbd7e7a21Source snippet
Recurrent Neural Networks and TransformersBecause they process everything in parallel, they train much faster on powerful computers and w...
-
Source: instagram.com
Link: https://www.instagram.com/reel/DGakj4-oEnf/?hl=en-gbSource snippet
(2017) shocked NLP by ditching recurrence in favor of self-attention, allowing parallel processing and faster...
-
Source: dataturbo.medium.com
Title: transformer attention is all you need fe6205c5be33
Link: https://dataturbo.medium.com/transformer-attention-is-all-you-need-fe6205c5be33Source snippet
Clear Explanation: Attention Is All You Need!This paper introduced a deep neural network model that can handle language translation tasks...
-
Source: youtube.com
Title: [Deep Learning]({{ ‘deep-learning/’ | relative_url }}) NYC
Link: https://www.youtube.com/watch?v=jYBNtt9X-FMSource snippet
Pretraining Recurrent Networks without Recurrence (Jun 2026) - YouTube Pretraining Recurrent Networks without Recurrence (Jun 2026) - You...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/[understandingSource snippet
ke RNNs, transformers process entire sequences simultaneously.Read more...
-
Source: medium.com
Link: https://medium.com/%40chilldenaya/transformer-attention-is-all-you-need-a-paper-summary-d5fa82ff65deSource snippet
self-attention layers are faster than recurrent layers...Read more...
Topic Tree