Within Image layers
How do parts become object recognition?
Deeper image layers can combine fur, eyes, snouts and other part-like signals into stronger evidence for an object category.
On this page
- From texture signals to part like responses
- Dog face features as a concrete example
- Why final predictions combine many detectors
Page outline Jump by section
Introduction
When a deep image-recognition network identifies a dog, it usually does not rely on a single “dog detector” hidden somewhere inside the model. Instead, deeper layers combine many learned signals that correspond to useful object parts and visual arrangements. Fur textures, eyes, ears, snouts, noses and characteristic face shapes can all contribute evidence. The network gradually assembles these pieces into a strong judgement that a dog is present. Research on feature visualisation and network interpretability has repeatedly shown that many deep neural networks develop units that respond to meaningful object parts, even though engineers never explicitly program those concepts into the model. [Distill+2netdissect.csail.mit.edu]distill.pubFeature VisualizationFeature VisualizationNovember 7, 2017 — by C Olah · 2017 · Cited by 1615 — Feature visualization answers questions about what a ne…
 This part-based strategy helps explain how image networks move from recognising local patterns to recognising complete objects. Rather than searching for one perfect feature, they aggregate many imperfect but useful clues.
This part-based strategy helps explain how image networks move from recognising local patterns to recognising complete objects. Rather than searching for one perfect feature, they aggregate many imperfect but useful clues.
From texture signals to part-like responses
Earlier image layers tend to respond to simple patterns such as edges, colour contrasts and textures. As information moves through additional layers, those lower-level signals are combined into increasingly structured representations. Researchers studying convolutional neural networks have found that later layers often contain units associated with higher-level concepts, including object parts and recurring visual structures. christophm.github.io+2netdissect.csail.mit.edu [christophm.github.io]christophm.github.ioDeep neural networks learn high-level features in the hidden layers27 Learned Features – Interpretable Machine LearningNetwork Dissection labels neural network units (e.g., channels) with human concepts…
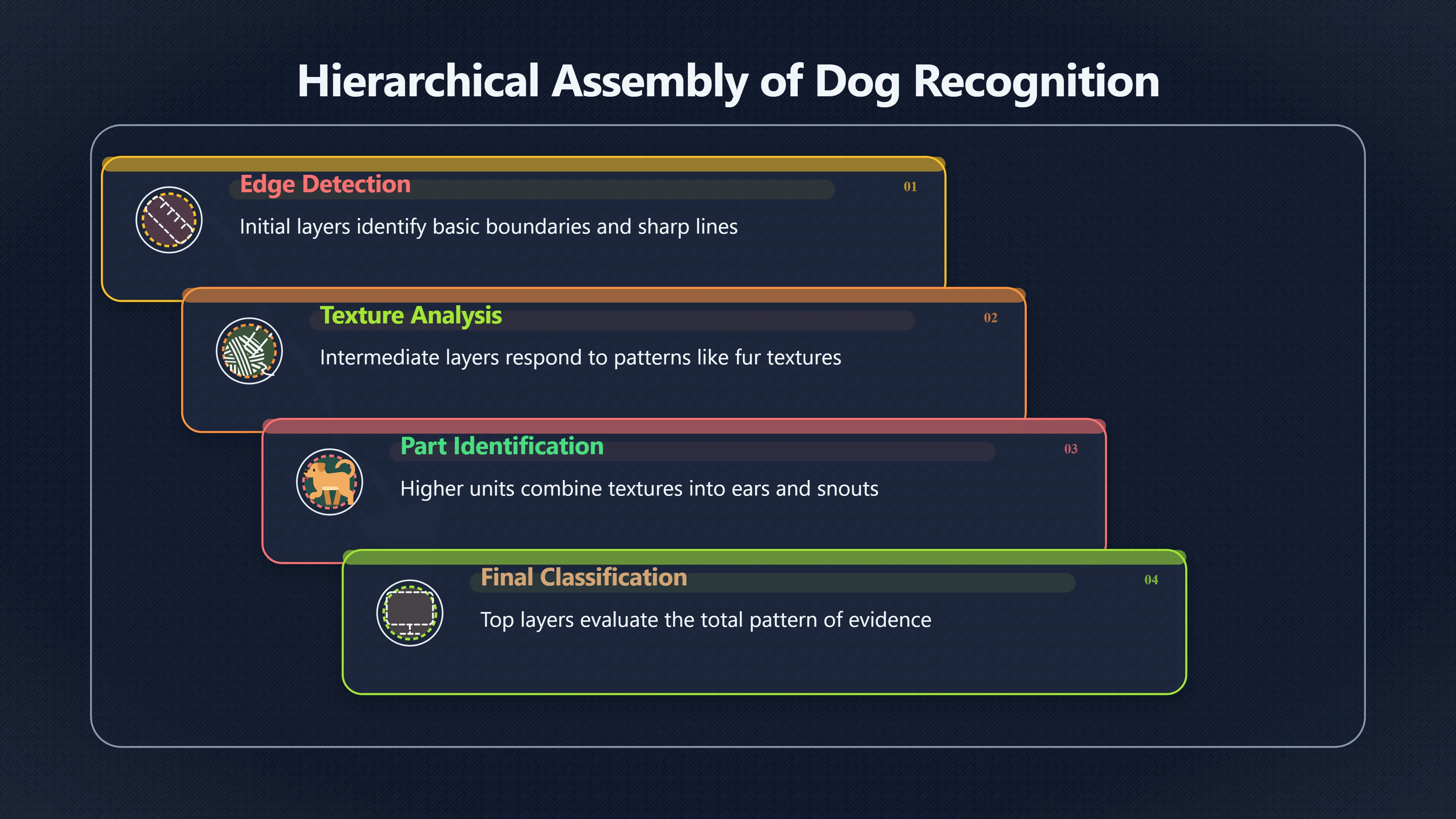
A useful way to think about the process is hierarchical assembly:
- Edge detectors help identify boundaries.
- Texture detectors respond to patterns such as fur.
- Higher-level units combine textures and shapes into structures resembling ears, eyes or snouts.
- Final classification layers evaluate the overall pattern of evidence.
Importantly, these part-like responses are learned because they help reduce classification errors during training. The network is rewarded for discovering internal features that reliably separate dogs from other categories. [Distill]distill.pubFeature VisualizationFeature VisualizationNovember 7, 2017 — by C Olah · 2017 · Cited by 1615 — Feature visualization answers questions about what a ne…
Studies using Network Dissection, a method that matches neural units to human-interpretable concepts, found that deep networks frequently contain units aligned with objects, object parts, materials and textures. Object-part detectors emerge naturally during training rather than being manually inserted by designers. netdissect.csail.mit.edu+2CVF Open Access [netdissect.csail.mit.edu]netdissect.csail.mit.eduOpen source on mit.edu.
Dog-face features as a concrete example
Dog recognition provides one of the clearest examples of part-based processing. Interpretability researchers have visualised neurons whose preferred patterns resemble dog faces or specific dog-face components. When these neurons are activated most strongly, the triggering image regions often contain combinations of eyes, snouts, fur and facial structure rather than isolated pixels. [Distill+2interpretablevision.github.io]distill.pubZoom In: An Introduction to Circuitsby C Olah · 2020 · Cited by 1088 — Let's consider this unit which we believe to be a pose-inva…
Consider a photograph of a Labrador:
- One set of units may respond strongly to short fur textures.
- Another may react to dark eye regions surrounded by lighter fur.
- Others may detect elongated snout shapes or ear contours.
- Additional units may encode the spatial arrangement of those parts.
Individually, none of these signals proves that the image contains a dog. Fur appears on other animals. Dark eyes appear on many species. A snout-like shape might occur elsewhere in an image. The strength comes from combining them. When several compatible detectors activate together in the expected arrangement, the network gains much greater confidence that it is looking at a dog. [interpretablevision.github.io+2Distill]interpretablevision.github.iocvpr20 chrisAn Introduction to Circuits in CNNsUsing feature visualization confirms that the neuron cares about a combination of snout, eyes and fur…
Feature-visualisation work has shown examples where neurons appear sensitive not merely to isolated features but to larger structures resembling complete dog heads. In these cases, the neuron responds to a coordinated pattern of eyes, ears, fur and muzzle geometry rather than a single texture patch. [Distill+2interpretablevision.github.io]distill.pubZoom In: An Introduction to Circuitsby C Olah · 2020 · Cited by 1088 — Let's consider this unit which we believe to be a pose-inva…

Why final predictions combine many detectors
A common misunderstanding is that one neuron corresponds to one concept. Real networks are usually more distributed than that. While some neurons may align strongly with interpretable concepts such as dog snouts or dog faces, object recognition generally depends on populations of neurons working together. [netdissect.csail.mit.edu+2arXiv]netdissect.csail.mit.eduOpen source on mit.edu.
This population-based approach offers several advantages.
Robustness to variation. Dogs appear in different breeds, colours, poses and lighting conditions. If recognition depended on a single feature, performance would be fragile. Multiple detectors provide redundancy. [Distill]distill.pubZoom In: An Introduction to Circuitsby C Olah · 2020 · Cited by 1088 — Let's consider this unit which we believe to be a pose-inva…
Tolerance to missing information. A dog may be partially hidden behind furniture or cropped at the edge of a photograph. The network can still classify the image if enough supporting part detectors remain active. [christophm.github.io]christophm.github.ioDeep neural networks learn high-level features in the hidden layers27 Learned Features – Interpretable Machine LearningNetwork Dissection labels neural network units (e.g., channels) with human concepts…
Better generalisation. A detector for eyes, a detector for fur texture and a detector for snout shape can be reused across many dog breeds. The model does not need a separate memorised template for every possible appearance. [Distill]distill.pubFeature VisualizationFeature VisualizationNovember 7, 2017 — by C Olah · 2017 · Cited by 1615 — Feature visualization answers questions about what a ne…
Research also suggests caution when interpreting individual neurons. Some studies argue that supposedly specialised object neurons often have broader and less selective behaviour than first impressions suggest. A unit that appears to detect dogs may still respond to other patterns under certain conditions. This is one reason modern interpretability research increasingly studies groups of neurons and circuits rather than searching for a single decisive “dog neuron”. [arXiv]arxiv.orgOpen source on arxiv.org.
What this reveals about image understanding
The emergence of object-part neurons illustrates a central idea in modern artificial intelligence: recognition is usually built from many learned pieces of evidence rather than one perfect symbolic rule. Deep layers transform textures and shapes into representations that increasingly resemble meaningful visual parts. Those part-like responses then cooperate to support object recognition.
For dog classification, the network’s success comes not from discovering a magical dog feature, but from learning a rich collection of detectors whose combined activity makes the presence of a dog highly likely. In that sense, object recognition is less like matching a single template and more like assembling a case from many visual clues. [netdissect.csail.mit.edu+2Distill]netdissect.csail.mit.eduOpen source on mit.edu.

Amazon book picks
Further Reading
Books and field guides related to How do parts become object recognition?. Use these as the next step if you want deeper reading beyond the article.
Deep Learning
Rating: 3.5/5 from 6 Google Books ratings
Explains hierarchical feature learning and object recognition in deep networks.
Computer Vision
Provides context on object recognition and visual feature hierarchies.
Deep Learning with Python
Illustrates how deep networks combine lower-level features into concepts.
Dive into Deep Learning
Includes convolutional neural networks and feature hierarchy concepts.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.


Endnotes
-
Source: distill.pub
Title: Feature Visualization
Link: https://distill.pub/2017/feature-visualizationSource snippet
Feature VisualizationNovember 7, 2017 — by C Olah · 2017 · Cited by 1615 — Feature visualization answers questions about what a ne...
Published: November 7, 2017
-
Source: netdissect.csail.mit.edu
Link: https://netdissect.csail.mit.edu/ -
Source: christophm.github.io
Title: Deep neural networks learn high-level features in the hidden layers
Link: https://christophm.github.io/interpretable-ml-book/cnn-features.htmlSource snippet
27 Learned Features – Interpretable Machine LearningNetwork Dissection labels neural network units (e.g., channels) with human concepts...
-
Source: arxiv.org
Link: https://arxiv.org/pdf/1711.05611Source snippet
Interpreting Deep Visual Representations via Network...by B Zhou · 2017 · Cited by 455 — The proposed method quantifies the interpretabi...
-
Source: distill.pub
Link: https://distill.pub/2020/circuits/zoom-inSource snippet
Zoom In: An Introduction to Circuitsby C Olah · 2020 · Cited by 1088 — Let's consider this unit which we believe to be a pose-inva...
-
Source: interpretablevision.github.io
Title: cvpr20 chris
Link: https://interpretablevision.github.io/slide/cvpr20_chris.pdfSource snippet
An Introduction to Circuits in CNNsUsing feature visualization confirms that the neuron cares about a combination of snout, eyes and fur...
-
Source: colah.github.io
Title: interp v neuro
Link: https://colah.github.io/notes/interp-v-neuro/Source snippet
Interpretability vs Neuroscience [rough note]12 Mar 2021 — If feature visualization gives you a fully formed dog head with eyes and ears...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2007.01062 -
Source: bmm.mit.edu
Title: Neural Circuits of Visual Intelligence
Link: https://bmm.mit.edu/sample-page/supplemental-materials/neural-circuits-of-visual-intelligence/Source snippet
(BMM) summer courseThe DiCarlo Lab explores neural network models that capture visual processing in the ventral visual stream of the prim...
-
Source: distill.pub
Link: https://distill.pub/2017/feature-visualization/appendix/Source snippet
Feature Visualization — AppendixThis appendix contains layers 3a through 5b of GoogLeNet. Below, you can click on the layer names to see...
-
Source: jov.arvojournals.org
Link: https://jov.arvojournals.org/article.aspx?articleid=2700226Source snippet
Visual Representations of Neural Networks via...by B Zhou · 2018 · Cited by 3 — In this work, we describe Network Dissection, a method t...
-
Source: openaccess.thecvf.com
Title: 256 images). We do not
Link: https://openaccess.thecvf.com/content_cvpr_2017/papers/Bau_Network_Dissection_Quantifying_CVPR_2017_paper.pdfSource snippet
CVF Open AccessQuantifying Interpretability of Deep Visual Representationsby D Bau · 2017 · Cited by 2331 — We can see that object detect...
-
Source: dictionary.cambridge.org
Link: https://dictionary.cambridge.org/dictionary/english/objectSource snippet
English meaning - Cambridge Dictionary6 days ago — a thing that you can see or touch but that is not usually a living animal, plant, or...
-
Source: Wikipedia
Link: https://en.wikipedia.org/wiki/ObjectSource snippet
ObjectGeneral meanings · Object (philosophy), a thing, being, item, or concept. Object (abstract), an object which does not exist at a...
-
Source: en.wiktionary.org
Link: https://en.wiktionary.org/wiki/objectSource snippet
page was last edited on 2 June 2026, at 07:31. Definitions and other content are available under CC BY-SA 4.0 unless otherwise noted.Read...
Published: June 2026
Additional References
-
Source: medium.com
Link: https://medium.com/data-science-collective/nn-15-neural-networks-decoded-concepts-over-code-d4cfc88774f0Source snippet
NN#15 — Detecting Objects In An Image With CNNsAnother fascinating area is “Object Detection”. In this article we'll see what it is and h...
-
Source: instagram.com
Link: https://www.instagram.com/object/?hl=enSource snippet
OBJECT (@object) • Instagram photos and videosDanish design brand, made by people for people. Follow. Message. At the height of summer wh...
-
Source: merriam-webster.com
Link: https://www.merriam-webster.com/dictionary/objectSource snippet
OBJECT Definition & Meaning3 days ago — The meaning of OBJECT is something material that may be perceived by the senses. How to use objec...
-
Source: researchgate.net
Title: 321095695 Interpreting Deep Visual Representations via Network Dissection
Link: https://www.researchgate.net/publication/321095695_Interpreting_Deep_Visual_Representations_via_Network_DissectionSource snippet
Interpreting Deep Visual Representations via Network...21 Nov 2017 — In this work, we describe Network Dissection, a method that interpr...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=zfiSAzpy9NMSource snippet
Network dissection feature visualization neural network object parts But what is a neural network? | [Deep learning]({{ 'deep-learning/' | relative_url }}) chapter 1 3Blue1Brown...
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/320915709_Feature_VisualizationSource snippet
tal library and information-intensive applications.Read more...
-
Source: pubmed.ncbi.nlm.nih.gov
Title: The proposed method
Link: https://pubmed.ncbi.nlm.nih.gov/30040625/Source snippet
Interpreting Deep Visual Representations via Network...by B Zhou · 2019 · Cited by 455 — In this work, we describe Network Dissect...
-
Source: reddit.com
Link: https://www.reddit.com/r/EnglishLearning/comments/1ig68i6/what_does_object_mean_in_grammatical_terms/Source snippet
t. So this means there will be this verb and what would...
-
Source: youtube.com
Title: Network Dissection: Quantifying Interpretability of Deep Visual Representations
Link: https://www.youtube.com/watch?v=Xy6RcjXMa2cSource snippet
What Does a Neural Network Actually See? (Every Layer Visualized)...
-
Source: youtube.com
Title: What are Convolutional Neural Networks (CNNs)?
Link: https://www.youtube.com/watch?v=QzY57FaENXgSource snippet
Simple explanation of convolutional neural network | Deep Learning Tutorial 23 (Tensorflow & Python)...
Topic Tree