Within Model Cards
Does the training data fit real users?
A model can fail after launch when its training data represents different people, places, languages, or conditions than the real deployment setting.
On this page
- What dataset composition reveals before launch
- How hidden gaps become deployment failures
- Questions reviewers should ask about target users
Page outline Jump by section
Introduction
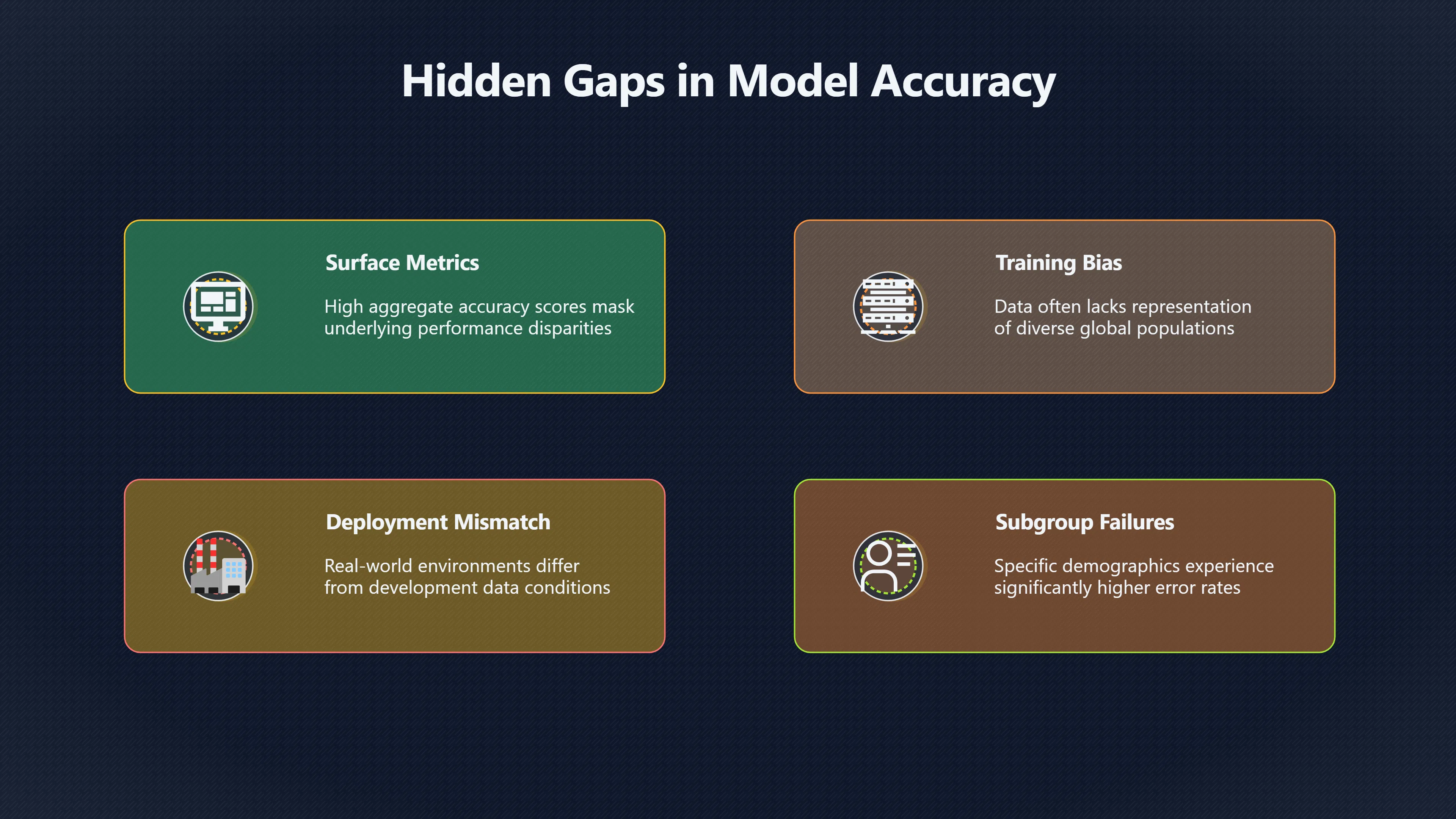
A model can appear accurate during development and still fail after deployment if the people, places, languages, or conditions represented in its training data differ from those encountered in the real world. This problem is often called a population mismatch or data-fit problem. It is one of the main reasons why dataset documentation matters before launch: a system can only learn patterns that are present in the data used to build and test it. When the training population does not resemble the deployment population, performance, fairness, and reliability can deteriorate in ways that are difficult to detect after the system is already affecting users. Documentation such as dataset datasheets and model cards helps reviewers identify these risks before deployment by revealing who and what the data actually represents. [arXiv+2Microsoft]arxiv.orgDatasheets for DatasetsDecember 3, 2021 — by T Gebru · 2018 · Cited by 4596 — Every machine learning model is trained and evaluated…

Does the training data fit real users?
The central question is simple: are the people represented in the training data similar to the people who will use or be affected by the system?
A mismatch can occur in many ways:
- A language model trained mostly on one variety of English may be deployed to speakers who use different dialects.
- A medical model developed from patients at one hospital may be used in a different region with different demographics, health conditions, or treatment practices.
- A computer-vision system trained on images from a limited set of countries may be deployed globally.
- A speech-recognition system trained primarily on adult voices may be expected to work equally well for children.
None of these situations necessarily indicates poor engineering. The problem is that machine-learning systems often assume that future users resemble the populations represented during development. When that assumption fails, accuracy measurements from development can become misleading. [arXiv+2JMIR]arxiv.orgRISED: A Pre-Deployment Evaluation Framework for High-…30 May 2026 — The resulting metrics answer whether the model ranks patient…
Dataset documentation is valuable because it makes those assumptions visible. A datasheet that clearly describes geographic coverage, demographic composition, collection conditions, and intended uses gives reviewers evidence to judge whether the deployment population is adequately represented. [arXiv+2AI Now Institute]arxiv.orgDatasheets for DatasetsDecember 3, 2021 — by T Gebru · 2018 · Cited by 4596 — Every machine learning model is trained and evaluated…
What dataset composition reveals before launch
Documentation about dataset composition is often the first warning sign that a model may not generalise well.
A dataset can look large and sophisticated while still containing important gaps. For example, millions of examples collected from a handful of countries may still fail to represent users elsewhere. Likewise, balanced overall statistics can conceal under-representation of specific groups that matter in deployment.
Datasheets were proposed partly to address this issue. Rather than treating datasets as neutral resources, they encourage developers to record who is represented, how examples were collected, and what limitations are known. This information allows deployment teams to evaluate fitness for purpose rather than relying only on headline accuracy scores. [arXiv+2Microsoft]arxiv.orgDatasheets for DatasetsDecember 3, 2021 — by T Gebru · 2018 · Cited by 4596 — Every machine learning model is trained and evaluated…
The most useful composition details often include:
- Demographic representation.
- Geographic coverage.
- Languages and dialects included.
- Time period of collection.
- Environmental conditions such as lighting, noise, weather, or equipment differences.
- Known exclusions and missing groups.
These details help answer a practical question: does the dataset resemble the world in which the model will operate?
How hidden gaps become deployment failures
The consequences of population mismatch are often invisible during testing because test datasets are frequently drawn from the same sources as training datasets.
A model may therefore perform well in development while failing when exposed to a different population. Researchers have repeatedly observed this problem in healthcare, where prediction models developed on one patient population can lose performance when transferred to hospitals with different patient characteristics, workflows, or data systems. High scores on an internal test set do not guarantee success in a new setting. [JMIR]jmir.orgEvaluation Study of Multiple Use Cases Across Different…by P Cabanillas Silva · 2024 · Cited by 16 — This study aimed to assess th…
The same pattern appears in other domains. A system trained in urban environments may struggle in rural ones. A model built using data from wealthier regions may not perform equally well in lower-income areas. A language system trained on standard forms of communication may misunderstand users who employ regional expressions or different linguistic conventions.
The key lesson is that deployment failure is often not caused by the model suddenly becoming worse. Instead, the environment changes relative to the data that shaped the model’s behaviour.

A concrete example: facial-analysis systems
One of the best-known demonstrations of training-data mismatch comes from research on commercial facial-analysis systems.
The Gender Shades study examined gender-classification systems from major technology companies and found substantial differences in performance across demographic groups. The researchers observed that commonly used face datasets were heavily skewed toward lighter-skinned individuals. When evaluated using a more balanced benchmark, darker-skinned women experienced dramatically higher error rates than lighter-skinned men. In some systems, darker-skinned women were misclassified more than one-third of the time, while error rates for lighter-skinned men were below 1%. Proceedings of Machine Learning Research+2Proceedings of Machine Learning Research [proceedings.mlr.press]proceedings.mlr.pressProceedings of Machine Learning ResearchGender Shades: Intersectional Accuracy Disparities in…by J Buolamwini · 2018 · Cited by 10693…
The importance of this case is not merely that the systems made mistakes. The deeper lesson is that aggregate accuracy figures masked unequal performance across groups. A deployment team reviewing only overall results might have concluded that the systems were sufficiently accurate. Detailed information about dataset composition and subgroup testing would have revealed the risk before deployment. Proceedings of Machine Learning Research+2Gender Shades [proceedings.mlr.press]proceedings.mlr.pressProceedings of Machine Learning ResearchGender Shades: Intersectional Accuracy Disparities in…by J Buolamwini · 2018 · Cited by 10693…
This example became influential because it demonstrated how a mismatch between training data and real users can translate directly into unequal outcomes for different populations. [Ars Electronica]ars.electronica.artGender Shades – Out of the BoxThe study reveals that popular applications that are already part of the programming display…
Why overall accuracy is often the wrong question
When evaluating whether training data fits real users, average performance can be deceptive.
Suppose a model achieves 95% accuracy overall. That number says little about whether every relevant group receives similar performance. If some groups are over-represented in the data, they may dominate the average result while smaller groups experience substantially worse outcomes.
For this reason, documentation and evaluation practices increasingly emphasise disaggregated testing—measuring performance across different populations rather than relying solely on a single aggregate metric. The objective is not merely to know whether a model works, but to understand for whom it works and under what conditions. [Proceedings of Machine Learning Research+2ResearchGate]proceedings.mlr.pressProceedings of Machine Learning ResearchGender Shades: Intersectional Accuracy Disparities in…by J Buolamwini · 2018 · Cited by 10693…
This shift reflects a broader governance lesson: a deployment decision should be based on evidence about the target population, not just evidence about the development dataset.
Questions reviewers should ask about target users
Before deployment, reviewers should use dataset and model documentation to investigate population fit directly.
Key questions include:
- Who is represented in the training data? Which demographic groups, regions, languages, and contexts are included? Which groups are missing or sparsely represented?
- Who are the intended users? Does the deployment population differ from the development population in important ways?
- How was performance evaluated? Were subgroup results reported? Were tests conducted using populations similar to those expected after deployment?
- What environments were represented? Were conditions such as lighting, background noise, equipment, or local practices similar to real deployment conditions?
- What limitations are documented? Do the datasheet or model card identify populations or scenarios where performance may be weaker?
These questions transform documentation from a compliance exercise into a practical risk-assessment tool. Rather than asking whether a model is generally accurate, reviewers can ask whether the evidence supports use with the specific people who will encounter it. [arXiv+2arXiv]arxiv.orgDatasheets for DatasetsDecember 3, 2021 — by T Gebru · 2018 · Cited by 4596 — Every machine learning model is trained and evaluated…

Why data fit is a deployment question, not just a data question
A dataset is never universally representative. Every dataset reflects choices about who was included, where information was collected, and under what conditions. The crucial issue is therefore not whether a dataset is perfect, but whether it is appropriate for a particular deployment setting.
Dataset datasheets and model documentation help organisations make that judgement before launch. By revealing population coverage, known gaps, and evaluation boundaries, they provide evidence about whether training data matches real users. When that fit is poor, the safest response is often additional testing, new data collection, or narrowing the intended use of the system rather than assuming that strong development metrics will automatically transfer to the real world. [NIST+3arXiv+3Microsoft]arxiv.orgDatasheets for DatasetsDecember 3, 2021 — by T Gebru · 2018 · Cited by 4596 — Every machine learning model is trained and evaluated…
Amazon book picks
Further Reading
Books and field guides related to Does the training data fit real users?. Use these as the next step if you want deeper reading beyond the article.
Invisible Women
A powerful illustration of how unrepresentative data creates real-world failures.
Atlas of AI
Examines datasets, data collection practices, and representation issues in AI systems.
Unmasking AI
Focuses on demographic performance gaps caused by training-data limitations.
AI Snake Oil
Explains evaluation pitfalls and why benchmark success may not reflect real users.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: arxiv.org
Link: https://arxiv.org/pdf/1803.09010Source snippet
Datasheets for DatasetsDecember 3, 2021 — by T Gebru · 2018 · Cited by 4596 — Every machine learning model is trained and evaluated...
Published: December 3, 2021
-
Source: microsoft.com
Link: https://www.microsoft.com/en-us/research/wp-content/uploads/2019/01/1803.09010.pdfSource snippet
Datasheets for Datasetsby T Gebru · Cited by 4580 — By analogy, we rec- ommend that every dataset be accompanied with a datasheet documen...
-
Source: arxiv.org
Link: https://arxiv.org/abs/1803.09010Source snippet
[1803.09010] Datasheets for Datasetsby T Gebru · 2018 · Cited by 4596 — We propose that every dataset be accompanied with a datasheet tha...
-
Source: arxiv.org
Link: https://arxiv.org/html/2605.12895v2Source snippet
RISED: A Pre-Deployment Evaluation Framework for High-...30 May 2026 — The resulting metrics answer whether the model ranks patient...
Published: May 2026
-
Source: jmir.org
Link: https://www.jmir.org/2024/1/e51409/Source snippet
Evaluation Study of Multiple [Use Cases]({{ 'use-cases/' | relative_url }}) Across Different...by P Cabanillas Silva · 2024 · Cited by 16 — This study aimed to assess th...
-
Source: nist.gov
Link: https://www.nist.gov/itl/ai-risk-management-frameworkSource snippet
iated with artificial intelligence (AI).Read more...
-
Source: ars.electronica.art
Link: https://ars.electronica.art/outofthebox/en/gender-shades/Source snippet
Gender Shades – Out of the BoxThe study reveals that popular applications that are already part of the programming display...
-
Source: researchgate.net
Title: 364429807 The unseen Black faces of AI algorithms
Link: https://www.researchgate.net/publication/364429807_The_unseen_Black_faces_of_AI_algorithmsSource snippet
The unseen Black faces of AI algorithmsOther work by Birhane (2022) found that commercial facial analysis AI tools misclassified dark-ski...
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/323722163_Gender_shades_intersectional_phenotypic_and_demographic_evaluation_of_face_datasets_and_gender_classifiersSource snippet
Gender shades: intersectional phenotypic and...For example, Buolamwini (2017) found that facial recognition technology is more likely t...
-
Source: researchgate.net
Title: 324055506 Datasheets for Datasets
Link: https://www.researchgate.net/publication/324055506_Datasheets_for_DatasetsSource snippet
Datasheets for Datasets3 May 2026 — We propose the concept of a datasheet for datasets, a short document to accompany public datasets, co...
Published: May 2026
-
Source: ainowinstitute.org
Title: datasheets for datasets
Link: https://ainowinstitute.org/publications/datasheets-for-datasetsSource snippet
22 Feb 2023 — Datasheets for datasets will facilitate better communication between dataset creators and dataset consumers, and encourage...
-
Source: proceedings.mlr.press
Link: https://proceedings.mlr.press/v81/buolamwini18a.htmlSource snippet
Proceedings of Machine Learning ResearchGender Shades: Intersectional Accuracy Disparities in...by J Buolamwini · 2018 · Cited by 10693...
-
Source: proceedings.mlr.press
Title: Darker females have the highest error rates for all gender.Read more
Link: https://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdfSource snippet
Proceedings of Machine Learning ResearchGender Shades: Intersectional Accuracy Disparities in...by J Buolamwini · 2018 · Cited by 10693...
-
Source: gendershades.org
Link: https://gendershades.org/overview.htmlSource snippet
Gender ShadesError analysis reveals 93.6% of faces misgendered by Microsoft were those of darker subjects. An internal evaluation of the...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=TWWsW1w-BVoSource snippet
Gender ShadesThe Gender Shades Project pilots an intersectional approach to inclusive product testing for AI. Gender Shades is a prelimin...
-
Source: digitalgovernmenthub.org
Link: https://digitalgovernmenthub.org/library/gender-shades-intersectional-accuracy-disparities-in-commercial-gender-classification/Source snippet
7%), while lighter-skinned males have much lower error rates (as low as 0.8%).Read more...
Additional References
-
Source: medium.com
Link: https://medium.com/%40akankshasinha247/model-cards-datasheets-governance-frameworks-0cda9605c94eSource snippet
Model Cards, Datasheets & Governance FrameworksThis blog explores how to instill responsibility into GenAI systems through Model Cards, D...
-
Source: rrapp.spia.princeton.edu
Link: https://rrapp.spia.princeton.edu/algorithmic-bias-in-facial-recognition-technology-on-the-basis-of-gender-and-skin-tone/Source snippet
13 Oct 2020 — Researchers identify discrepancies in classification of gender and skin tone by facial recognition technology indicati...
-
Source: news.mit.edu
Title: study finds gender skin type bias artificial intelligence systems 0212
Link: https://news.mit.edu/2018/study-finds-gender-skin-type-bias-artificial-intelligence-systems-0212Source snippet
MIT NewsStudy finds gender and skin-type bias in commercial...11 Feb 2018 — For darker-skinned women — those assigned scores of IV, V, o...
-
Source: klover.ai
Title: dr timnit gebru translating gender shades into corporate governance
Link: https://www.klover.ai/dr-timnit-gebru-translating-gender-shades-into-corporate-governance/Source snippet
Timnit Gebru: Translating 'Gender Shades' into...23 Jun 2025 — The media seized on the report's central figure: a 34.7% error rate for d...
-
Source: content.naic.org
Link: https://content.naic.org/sites/default/files/inline-files/NAIC%20AI%20Health%20Survey%20Report%20.pdfSource snippet
Then, we evaluate model performance across different demographic groups using metrics like...Read more...
-
Source: wgbh.org
Title: addressing gender and racial bias in facial recognition technology
Link: https://www.wgbh.org/news/national/2018-03-21/addressing-gender-and-racial-bias-in-facial-recognition-technologySource snippet
Addressing Gender And Racial Bias In Facial Recognition...Mar 21, 2018 — “Lighter male faces were the easiest to guess the gender on, an...
-
Source: aclu-mn.org
Title: biased technology [automated]({{ ‘decisions/’ | relative_url }}) discrimination facial recognition
Link: https://www.aclu-mn.org/news/biased-technology-automated-discrimination-facial-recognition/Source snippet
Biased Technology: The Automated Discrimination...29 Feb 2024 — The error rate for light-skinned men is 0.8%, compared to 34.7% for dark...
-
Source: censinet.com
Title: nist ai rmf adoption hospitals governance framework
Link: https://censinet.com/perspectives/nist-ai-rmf-adoption-hospitals-governance-frameworkSource snippet
NIST AI RMF Adoption Still Nascent: Just 12% of Hospitals...23 Oct 2025 — The NIST AI RMF is a voluntary framework designed to help orga...
-
Source: cogentinfo.com
Link: https://cogentinfo.com/resources/addressing-gender-bias-in-facial-recognition-technology-an-urgent-need-for-fairness-and-inclusionSource snippet
Addressing Gender Bias in Facial Recognition TechnologyApr 14, 2025 — For darker-skinned females, the error rate rose to 34.7%...
-
Source: holisticai.gitbook.io
Link: https://holisticai.gitbook.io/roadmaps-for-risk-mitigation/mitigation-roadmaps/documentation-for-improved-explainability-of-machine-learning-models/step-1-datasheets-for-datasetsSource snippet
1: Datasheets for Datasets | Roadmaps for risk...25 Apr 2022 — Datasheets aim to document important information regarding a specific dat...
Topic Tree