Within Data Readiness
Why AI search breaks after the pilot
Retrieval systems can miss the best evidence when company documents are messy, duplicated, incomplete or poorly structured.
On this page
- How clean pilot datasets hide real retrieval problems
- Tables, PDFs and legacy formats that lose context
- Metadata and ranking choices that improve enterprise answers
Page outline Jump by section
Introduction
Many enterprise AI applications depend on retrieval before generation. The model does not answer directly from training data; it first searches company documents, policies, contracts, reports or knowledge bases and then generates a response from the retrieved material. This means that even a powerful language model can produce poor answers when retrieval fails.
 The difficulty is that retrieval systems are often tested on clean pilot datasets but deployed into environments filled with scanned PDFs, duplicated documents, inconsistent naming conventions, outdated files, spreadsheets, email archives and decades of legacy content. In production, the challenge is rarely finding a document. It is finding the right evidence among thousands of imperfect sources. Research and industry experience increasingly show that retrieval quality is shaped by document structure, metadata, extraction quality and ranking choices long before the language model becomes involved. [Buzzi.ai+2arXiv]buzzi.aiA I Document Search Enterprise: Practical RAG Design GuideAI Document Search Enterprise: Practical RAG Design GuideJanuary 1, 2026…
The difficulty is that retrieval systems are often tested on clean pilot datasets but deployed into environments filled with scanned PDFs, duplicated documents, inconsistent naming conventions, outdated files, spreadsheets, email archives and decades of legacy content. In production, the challenge is rarely finding a document. It is finding the right evidence among thousands of imperfect sources. Research and industry experience increasingly show that retrieval quality is shaped by document structure, metadata, extraction quality and ranking choices long before the language model becomes involved. [Buzzi.ai+2arXiv]buzzi.aiA I Document Search Enterprise: Practical RAG Design GuideAI Document Search Enterprise: Practical RAG Design GuideJanuary 1, 2026…
How clean pilot datasets hide real retrieval problems
Pilot projects often create a misleading impression of retrieval performance. Teams typically test with curated documents that have been cleaned, reviewed and organised specifically for the experiment. Questions are known in advance, document ownership is clear and duplicate content has often been removed.
Real business environments look very different. Large organisations accumulate content from mergers, departmental systems, shared drives and legacy applications. The same policy may exist in multiple versions. Product names may change over time. Different departments may describe the same process using different terminology. Important knowledge may exist only inside archived reports or email threads. Around 80% of enterprise information is estimated to be unstructured, including contracts, PDFs, transcripts and documents that are difficult to search consistently. [Business Insider]businessinsider.comBusiness Insider The most valuable data in your company isn't missingIt's disconnected.Many enterprises possess the data needed to make AI systems effective, but around 80% of this data is unstructured (e.g…
This creates a common failure pattern. Retrieval returns documents that appear relevant according to keywords or semantic similarity, yet misses the authoritative source. The language model then generates an answer from incomplete evidence. Users often blame the model when the root problem is that the best document never reached the model in the first place. [Buzzi.ai]buzzi.aiA I Document Search Enterprise: Practical RAG Design GuideAI Document Search Enterprise: Practical RAG Design GuideJanuary 1, 2026…
A further complication is that retrieval failures are often invisible. The system still returns an answer, creating the impression that it understood the question. In reality, it may have retrieved only a partial document, an outdated version or a neighbouring section that looks similar but lacks the critical detail needed for an accurate response. [ArchCrux]archcrux.comArch Crux RAG in Production Is Mostly Not About Retrieval | Arch CruxRAG in Production Is Mostly Not About Retrieval | ArchCruxApril 28, 2026…
Tables, PDFs and legacy formats that lose context
Many enterprise retrieval systems are designed around plain text. Real business content is not.
Contracts contain signatures, appendices and complex layouts. Financial reports contain tables spread across pages. Operational manuals include diagrams, charts and structured specifications. Legacy documents may exist only as scanned images. When these formats are converted into searchable text, important relationships can disappear. [Tensoria+2aakashx]tensoria.frMultimodal RAG: Retrieving from Images, PDFs, and Tables | TensoriaMultimodal RAG: Retrieving from Images, PDFs, and Tables | TensoriaMay 15, 2026…
Why tables are especially difficult
Tables communicate meaning through structure. Rows, columns, headers and units define relationships between values. When a retrieval pipeline flattens a table into ordinary text, those relationships can be lost.
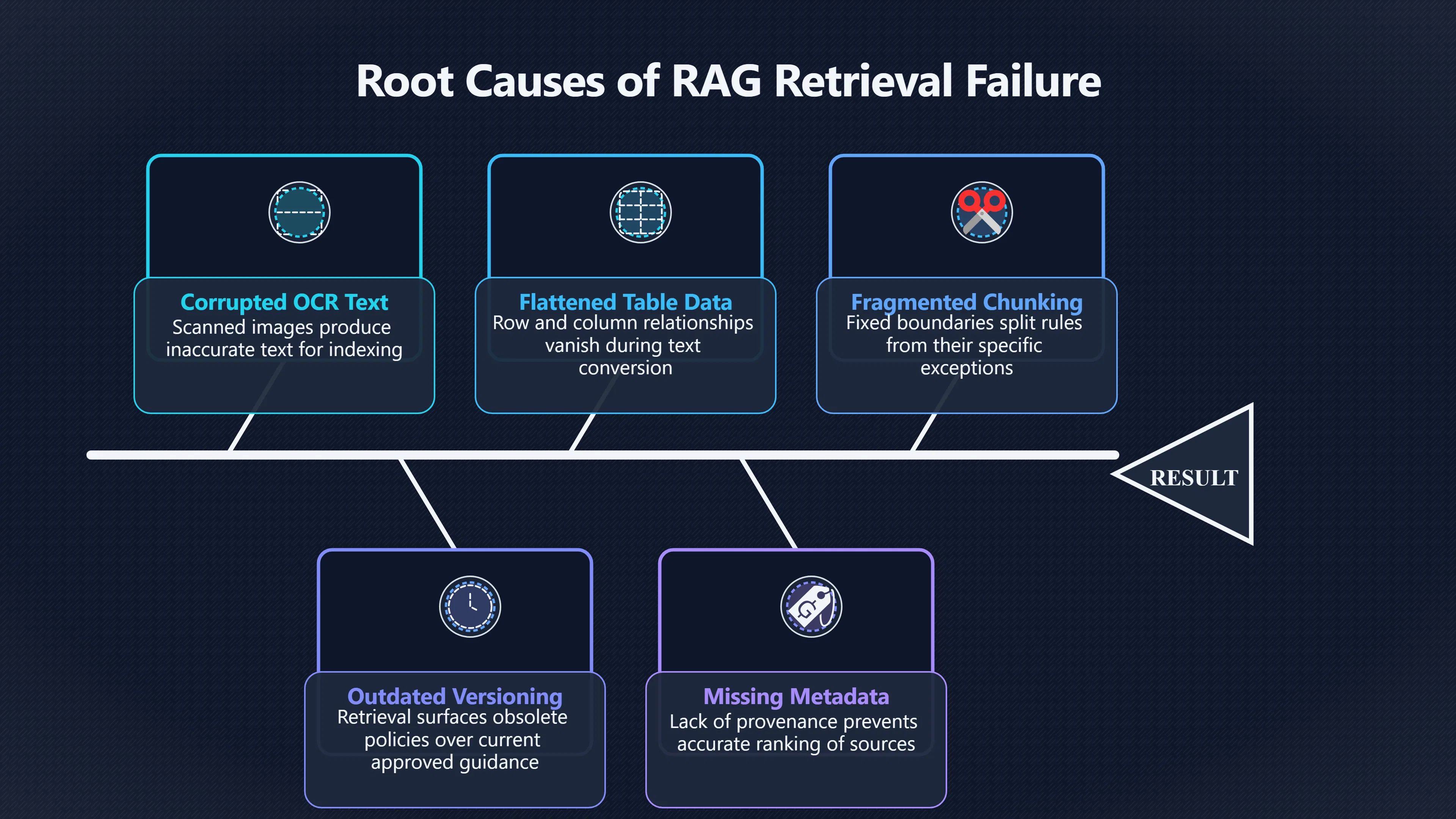
For example, a compliance threshold may sit under a particular column heading. If extraction removes the heading or breaks row alignment, retrieval may find the number but not its meaning. A user asking for a regulatory limit could receive the wrong value because the connection between data and context disappeared during ingestion. Researchers and practitioners have repeatedly identified table extraction and ranking as a specialised retrieval problem rather than a simple text-search problem. [OptyxStack+2Penn State]optyxstack.comWhy Your RAG Fails on PDF Tables: OCR, Header Loss, and Row-Boundary Fixes | OptyxStackMarch 22, 2026…
PDFs are built for people, not retrieval systems
PDF files preserve visual appearance rather than semantic structure. As a result, extraction tools often struggle with:
- Multi-column layouts
- Footnotes and references
- Page breaks through tables
- Merged cells
- Scanned images requiring optical character recognition (OCR)
- Embedded charts and diagrams
If OCR introduces errors or a parser incorrectly reconstructs document structure, retrieval indexes corrupted information. Later searches can only retrieve what was successfully extracted. The retrieval system cannot recover context that disappeared during ingestion. Studies evaluating PDF parsing and retrieval pipelines consistently show that extraction and chunking choices significantly affect downstream answer quality. [OptyxStack+2arXiv]optyxstack.comWhy Your RAG Fails on PDF Tables: OCR, Header Loss, and Row-Boundary Fixes | OptyxStackMarch 22, 2026…
Legacy content creates hidden blind spots
Many organisations still depend on historical documents created long before modern AI systems existed. These records may use obsolete terminology, unusual formatting or proprietary file types.
A retrieval engine may technically index such content while failing to represent it meaningfully. Critical information becomes effectively invisible even though it remains stored in the repository. This is one reason enterprise users frequently report situations where they know a document exists but cannot get the AI system to find it reliably. [Reddit]reddit.comWhy is there no successful RAG-based service that processes local documents?Why is there no successful RAG-based service that processes local documents?August 20, 2025…

Chunking can destroy the evidence users actually need
Most retrieval systems divide documents into smaller pieces, known as chunks, before indexing them. Chunking is necessary because language models and embedding systems have context limits. However, poor chunking can break the connection between related facts.
Consider a policy document where a rule appears on one page and its exceptions appear on the next. If chunk boundaries split these sections apart, retrieval may return the rule without the exception. The resulting answer appears confident but is incomplete. [Buzzi.ai]buzzi.aiA I Document Search Enterprise: Practical RAG Design GuideAI Document Search Enterprise: Practical RAG Design GuideJanuary 1, 2026…
This problem becomes worse with enterprise content because business documents are rarely organised as continuous prose. They contain:
- References to other sections
- Cross-linked procedures
- Tables and appendices
- Legal clauses
- Version histories
- Product specifications
Research on enterprise retrieval has found that structure-aware chunking often performs better than generic fixed-size approaches because it preserves document organisation and contextual relationships. Yet even improved chunking strategies struggle with highly visual or diagram-heavy content. [arXiv+2Buzzi.ai]arxiv.orgEvaluating Chunking Strategies For Retrieval-Augmented Generation in Oil and Gas Enterprise DocumentsMarch 25, 2026…
A common misconception is that there is one ideal chunk size. In practice, different questions favour different retrieval units. Small chunks can improve precision for narrow questions, while broader questions often require larger sections to preserve context. Production systems must balance both requirements simultaneously. [Reddit]reddit.comRAG retrieval issue: why fixed chunking is starting to look like the real problem…
Metadata and ranking choices that improve enterprise answers
Retrieval quality depends not only on document content but also on the information surrounding it.
Metadata can include:
- Document owner
- Publication date
- Department
- Product line
- Regulatory region
- Version number
- Approval status
- Source system
Without this context, retrieval may treat an obsolete document and an approved policy as equally relevant. The language model then receives competing evidence without knowing which source should take priority. [Buzzi.ai]buzzi.aiA I Document Search Enterprise: Practical RAG Design GuideAI Document Search Enterprise: Practical RAG Design GuideJanuary 1, 2026…
Strong enterprise retrieval systems therefore enrich content before indexing. Rather than storing documents as anonymous text blocks, they preserve provenance information such as section titles, page numbers and document hierarchy. This makes ranking more reliable and helps users verify where answers originated. [Buzzi.ai]buzzi.aiA I Document Search Enterprise: Practical RAG Design GuideAI Document Search Enterprise: Practical RAG Design GuideJanuary 1, 2026…
Ranking also matters. Many systems rely heavily on semantic similarity, which can surface documents that are linguistically related but operationally irrelevant. Hybrid approaches that combine semantic search with structured filters, metadata constraints and reranking often perform better because they incorporate business context rather than relying solely on language patterns. [aakashx]aakashx.comRAG in Production: What Breaks at Enterprise Scale | aakashxRAG in Production: What Breaks at Enterprise Scale | aakashx…

Why retrieval failures matter more than model failures
When enterprise users encounter an incorrect answer, they often assume the language model hallucinated. Sometimes it did. But many production failures begin much earlier.
The retrieval layer may have:
- Missed the authoritative document.
- Retrieved only part of the relevant evidence.
- Lost structure during extraction.
- Indexed corrupted OCR text.
- Ranked outdated information above current guidance.
- Failed to connect related records across systems.
In each case, the model can only reason over the information it receives. If retrieval delivers weak evidence, generation quality declines regardless of model sophistication. Recent research into data quality for retrieval-augmented generation systems highlights that many quality problems originate in extraction, transformation and search stages before any response is generated. [arXiv]arxiv.orgarXiv Data Quality Challenges in Retrieval-Augmented GenerationarXiv Data Quality Challenges in Retrieval-Augmented Generation
For organisations moving from pilots to production, this shifts the focus of AI readiness. The question is not only whether a model can answer a business question. It is whether the retrieval system can consistently find, preserve and rank the best evidence hidden inside the organisation’s real content. When retrieval succeeds, enterprise AI becomes substantially more trustworthy. When it fails, even advanced models inherit the weaknesses of the underlying information environment. [Buzzi.ai+2Business Insider]buzzi.aiA I Document Search Enterprise: Practical RAG Design GuideAI Document Search Enterprise: Practical RAG Design GuideJanuary 1, 2026…
Amazon book picks
Further Reading
Books and field guides related to Why AI search breaks after the pilot. Use these as the next step if you want deeper reading beyond the article.
Designing Data-intensive Applications
Explains production-scale data retrieval, reliability and information architecture.
Competing in the Age of AI
Explains enterprise-scale AI operating models beyond pilots.
Data Management for Researchers
Covers metadata, organisation and information quality issues.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: buzzi.ai
Title: A I Document Search Enterprise: Practical RAG Design Guide
Link: https://www.buzzi.ai/insights/ai-enterprise-document-search-rag-design-guideSource snippet
AI Document Search Enterprise: Practical RAG Design GuideJanuary 1, 2026...
Published: January 1, 2026
-
Source: arxiv.org
Title: arXiv Data Quality Challenges in Retrieval-Augmented Generation
Link: https://arxiv.org/abs/2510.00552 -
Source: archcrux.com
Title: Arch Crux RAG in Production Is Mostly Not About Retrieval | Arch Crux
Link: https://www.archcrux.com/articles/rag-in-production-is-mostly-not-about-retrievalSource snippet
RAG in Production Is Mostly Not About Retrieval | ArchCruxApril 28, 2026...
Published: April 28, 2026
-
Source: tensoria.fr
Title: Multimodal RAG: Retrieving from Images, PDFs, and Tables | Tensoria
Link: https://tensoria.fr/en/blog/multimodal-rag-images-pdfs-tablesSource snippet
Multimodal RAG: Retrieving from Images, PDFs, and Tables | TensoriaMay 15, 2026...
Published: May 15, 2026
-
Source: aakashx.com
Title: RAG in Production: What Breaks at Enterprise Scale | aakashx
Link: https://www.aakashx.com/blog/rag-in-production-enterprise-scale/Source snippet
RAG in Production: What Breaks at Enterprise Scale | aakashx...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2604.12047 -
Source: optyxstack.com
Link: https://optyxstack.com/rag-reliability/why-your-rag-fails-on-pdf-tables-ocr-header-loss-row-boundary-fixesSource snippet
Why Your RAG Fails on PDF Tables: OCR, Header Loss, and Row-Boundary Fixes | OptyxStackMarch 22, 2026...
Published: March 22, 2026
-
Source: reddit.com
Title: Why RAG Fails on Tables, Graphs, and Structured Data
Link: https://www.reddit.com/r/Rag/comments/1pfuxis/why_rag_fails_on_tables_graphs_and_structured_data/Source snippet
Why RAG Fails on Tables, Graphs, and Structured Data...
-
Source: reddit.com
Title: Why is there no successful RAG-based service that processes local documents?
Link: https://www.reddit.com/r/Rag/comments/1mv1oen/why_is_there_no_successful_ragbased_service_that/Source snippet
Why is there no successful RAG-based service that processes local documents?August 20, 2025...
Published: August 20, 2025
-
Source: reddit.com
Title: Honestly, chunking is where most RAG systems quietly go wrong
Link: https://www.reddit.com/r/AI_Agents/comments/1t2q7tt/honestly_chunking_is_where_most_rag_systems/Source snippet
Honestly, chunking is where most RAG systems quietly go wrong...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2603.24556Source snippet
Evaluating Chunking Strategies For Retrieval-Augmented Generation in Oil and Gas Enterprise DocumentsMarch 25, 2026...
Published: March 25, 2026
-
Source: reddit.com
Link: https://www.reddit.com/r/Rag/comments/1sxrp80/rag_retrieval_issue_why_fixed_chunking_is/Source snippet
RAG retrieval issue: why fixed chunking is starting to look like the real problem...
-
Source: businessinsider.com
Title: Business Insider The most valuable data in your company isn’t missing
Link: https://www.businessinsider.com/sc/how-unstructured-enterprise-data-is-limiting-ai-performanceSource snippet
It's disconnected.Many enterprises possess the data needed to make AI systems effective, but around 80% of this data is unstructured (e.g...
-
Source: pure.psu.edu
Link: https://pure.psu.edu/en/publications/tableseer-automatic-table-metadata-extraction-and-searching-in-diSource snippet
Penn StateTableSeer: Automatic table metadata extraction and searching in digital libraries - Penn State...
Additional References
-
Source: research.ibm.com
Link: https://research.ibm.com/publications/is-my-data-in-your-retrieval-database-membership-[inferenceSource snippet
Is My Data in Your Retrieval Database? Membership Inference Attacks Against Retrieval Augmented Generation for ICISSP 2025 - IBM Research...
-
Source: searchplex.net
Link: https://www.searchplex.net/why-rag-fails-in-productionSource snippet
Searchplex | Why RAG Fails in Production — Agentic AI and [Generative AI]({{ 'generative-ai/' | relative_url }}) Retrieval Architecture | Searchplex...
-
Source: sciencedirect.com
Link: https://www.sciencedirect.com/science/article/pii/S0950705118305549Source snippet
www.sciencedirect.comSemIndex+: A semantic indexing scheme for structured, unstructured, and partly structured data - ScienceDirectJanuar...
-
Source: ibm.com
Link: https://www.ibm.com/it-it/think/insights/rag-problems-five-ways-to-fixSource snippet
problemi della RAG persistono. Ecco cinque modi per risolverli | IBM...
-
Source: youtube.com
Title: Building Private RAG: A Blueprint for Share Point & n8n
Link: https://www.youtube.com/watch?v=9Ld_HEW2vE4Source snippet
Advanced RAG: Architecture, Techniques, and Enterprise Applications | Uplatz...
-
Source: birjob.com
Title: www.birjob.com RA G Is Not As Simple As They Tell You
Link: https://www.birjob.com/blog/rag-is-not-as-simple-as-they-tell-youSource snippet
Is Not As Simple As They Tell YouJanuary 15, 2026...
Published: January 15, 2026
-
Source: link.springer.com
Link: https://link.springer.com/article/10.1007/s00799-023-00363-4Source snippet
April 28, 2023...
Published: April 28, 2023
-
Source: youtube.com
Title: Advanced Retrieval Augmented Generation (RAG) Deep Dive
Link: https://www.youtube.com/watch?v=hfx7F7lObdgSource snippet
Building Private RAG: A Blueprint for SharePoint & n8n...
-
Source: youtube.com
Title: Why RAG Fails in Production: The Hidden Problems
Link: https://www.youtube.com/watch?v=qncAHDJ6Ft4Source snippet
The Billion-Vector Problem: HNSW vs. DiskANN in Azure [AI Search]({{ 'ai-search/' | relative_url }})...
-
Source: youtube.com
Title: The Billion-Vector Problem: HNSW vs. Disk ANN in Azure AI Search
Link: https://www.youtube.com/watch?v=XllJzNTW3g0Source snippet
RAG Retrieval Deep Dive: BM25, Embeddings, and the Power of Agentic Search...
Topic Tree