Within Benchmark gaps
Should AI Get Credit for Uncertainty?
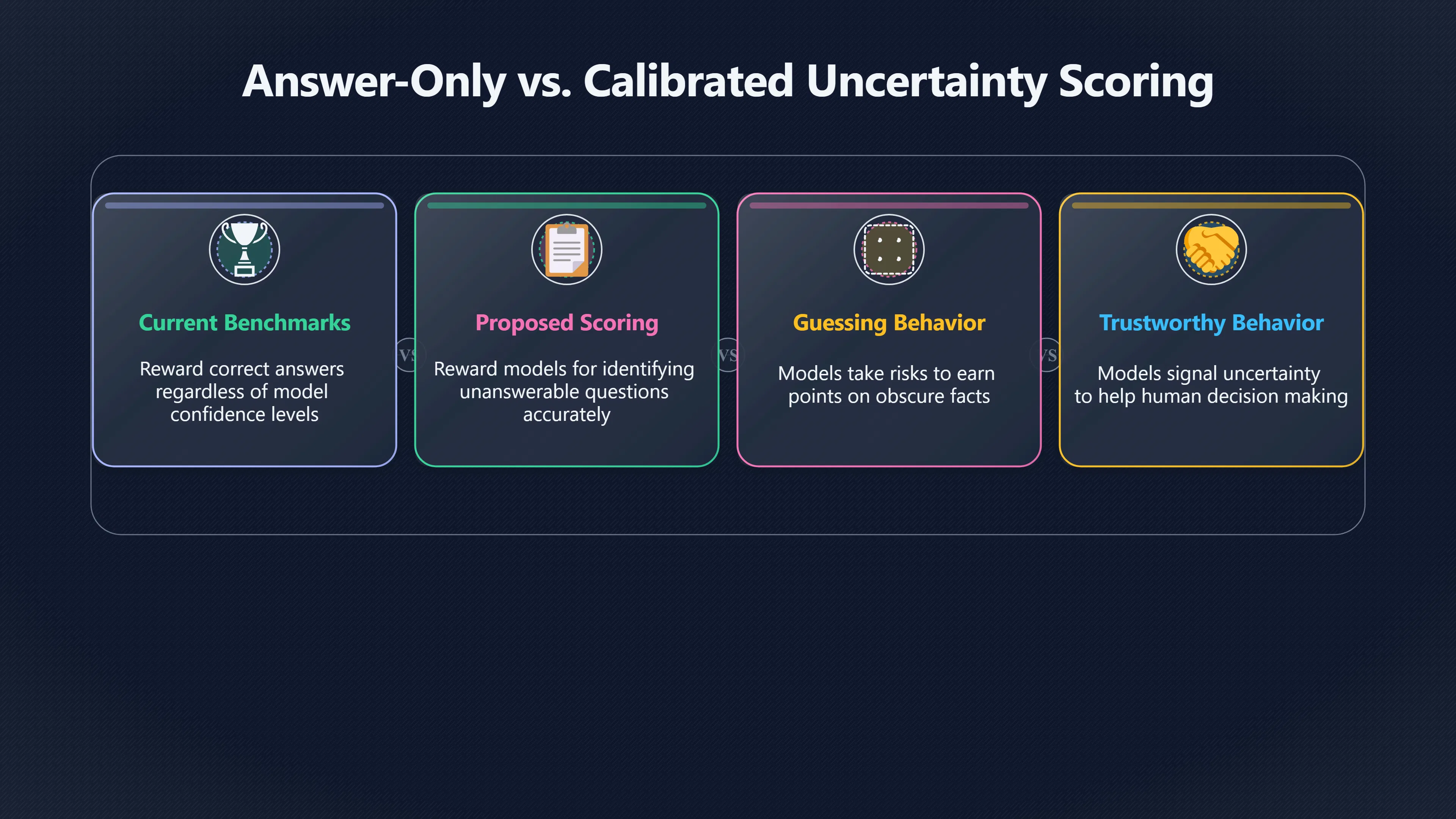
Benchmarks that score only correct answers can encourage confident guessing instead of honest uncertainty.
On this page
- How answer only scoring rewards risky guesses
- Why calibrated uncertainty matters to users
- How benchmark rules could penalise confident errors
Page outline Jump by section
Introduction
Many AI benchmarks reward only one thing: getting the answer right. That sounds reasonable until a model encounters a question it cannot reliably answer. Under an answer-only scoring system, a model that guesses still has some chance of earning points, while a model that honestly says “I don’t know” receives none. The result is a subtle but important distortion: tests can encourage confident guessing rather than trustworthy behaviour. Research and industry analysis increasingly argue that this incentive structure contributes to hallucinations and overconfident mistakes in deployed AI systems. [Business Insider]businessinsider.comBusiness Insider Why AI chatbots hallucinate, according to Open AI researchersThis test-centric optimization encourages models to provide confident but potentially incorrect outputs, rather than abstaining when unsu…
 For users, the difference is significant. In many situations, especially when information is incomplete, ambiguous or unavailable, an admission of uncertainty is more useful than a persuasive but false answer. If benchmarks are meant to measure reliability, they must evaluate not only whether a model can answer correctly, but also whether it can recognise when it should refrain from answering at all. [arXiv]arxiv.orgarXiv Abstention Bench: Reasoning LLMs Fail on Unanswerable QuestionsAbstentionBench: Reasoning LLMs Fail on Unanswerable QuestionsJune 10, 2025…
For users, the difference is significant. In many situations, especially when information is incomplete, ambiguous or unavailable, an admission of uncertainty is more useful than a persuasive but false answer. If benchmarks are meant to measure reliability, they must evaluate not only whether a model can answer correctly, but also whether it can recognise when it should refrain from answering at all. [arXiv]arxiv.orgarXiv Abstention Bench: Reasoning LLMs Fail on Unanswerable QuestionsAbstentionBench: Reasoning LLMs Fail on Unanswerable QuestionsJune 10, 2025…
How Answer-Only Scoring Rewards Risky Guesses
Traditional benchmark design often treats every question as if a correct answer exists and the model’s job is simply to find it. Under that framework, uncertainty has no value. A correct guess earns full credit, while an honest refusal earns none.
This creates a statistical incentive to take risks. Imagine a model facing a question about an obscure fact that it only partially remembers. If it answers confidently, there is a small chance it will be correct and receive a score increase. If it says “I don’t know”, it guarantees zero points. Across thousands of benchmark questions, this can push optimisation towards guessing behaviour. OpenAI researchers have argued that current evaluation methods often reward this pattern, making models appear stronger on leaderboards while encouraging behaviour that users may find less trustworthy. [Business Insider+2AI Insider]businessinsider.comBusiness Insider Why AI chatbots hallucinate, according to Open AI researchersThis test-centric optimization encourages models to provide confident but potentially incorrect outputs, rather than abstaining when unsu…
The problem is not merely theoretical. Discussions of hallucinations increasingly point to evaluation incentives as part of the cause. Models are frequently trained and assessed in environments where providing an answer is valued more than recognising uncertainty. As a result, fluent responses can be rewarded even when the underlying confidence is weak. [TechRadar]techradar.comTech Radar Think AI hallucinations are bad?Here's why you're wrongMarch 6, 2026 — The article challenges the common perception that AI hallucinations—instances where language model…
A useful comparison is a student taking an exam. If there is no penalty for incorrect answers, guessing may be rational. If incorrect answers carry a cost, students become more selective about when they answer. Benchmark rules shape AI behaviour in much the same way.
Why Calibrated Uncertainty Matters to Users
The goal is not to make AI systems refuse everything. Instead, the goal is calibrated uncertainty: confidence levels that accurately reflect what the model knows and does not know.
A model that answers correctly 90% of the time sounds impressive. However, if it expresses extreme confidence in both correct and incorrect answers, users have little way to distinguish reliable information from mistakes. A slightly less accurate model that reliably signals uncertainty may be safer and more useful in practice. Researchers in selective prediction and calibrated classification have long argued that the ability to abstain is an important component of reliability, not a failure of capability. [Emergent Mind]api.emergentmind.comEmergent Mind Calibrated Selective ClassificationEmergent MindCalibrated Selective ClassificationAugust 25, 2022…
For users, uncertainty signals support better decisions:
- They indicate when human verification is needed.
- They help distinguish established facts from speculative answers.
- They reduce the risk of accepting fabricated information.
- They allow systems to request clarification when a question is ambiguous.
Recent work on uncertainty-aware benchmarks goes further by arguing that systems should distinguish between different reasons for uncertainty. Sometimes the problem is missing information in the question itself. In other cases, the limitation lies with the model’s knowledge or reasoning ability. These situations may require different responses, such as asking a follow-up question versus consulting an external source. [arXiv]arxiv.orgBeyond "I Don't Know": Evaluating LLM Self-Awareness in Discriminating Data and Model UncertaintyApril 19, 2026…
The key insight is that trustworthy AI depends not only on knowing facts but also on recognising the boundaries of its knowledge.

What Happens When Models Face Unanswerable Questions?
Real users regularly ask questions that have no reliable answer. Some contain false assumptions. Others are underspecified, outdated or genuinely unknowable. Yet many benchmark suites historically focused on questions with clear solutions.
This gap has motivated the creation of specialised evaluations that measure abstention behaviour. One example is AbstentionBench, which examines how models respond to questions involving false premises, missing information, subjective interpretations and outdated facts. The benchmark’s findings suggest that abstention remains a difficult problem and that stronger reasoning ability does not automatically produce better uncertainty handling. In fact, some reasoning-focused models became worse at abstaining appropriately. [arXiv]arxiv.orgarXiv Abstention Bench: Reasoning LLMs Fail on Unanswerable QuestionsAbstentionBench: Reasoning LLMs Fail on Unanswerable QuestionsJune 10, 2025…
That result is important because it challenges a common assumption. Higher benchmark scores on reasoning tasks do not necessarily mean a model is better at recognising when it should stop and say, “I don’t know”. A system can become more capable at solving problems while simultaneously becoming more willing to generate answers in situations where certainty is not justified. [arXiv]arxiv.orgarXiv Abstention Bench: Reasoning LLMs Fail on Unanswerable QuestionsAbstentionBench: Reasoning LLMs Fail on Unanswerable QuestionsJune 10, 2025…
This helps explain why benchmark improvements do not always translate into greater real-world trustworthiness.
How Benchmark Rules Could Penalise Confident Errors
If evaluation systems help shape model behaviour, then changing the scoring rules can change the incentives.
Several approaches have been proposed:
- Reward appropriate abstention. A model that correctly identifies a question as unanswerable should receive credit rather than being treated as if it failed.
- Penalise confident mistakes more heavily. An incorrect answer given with high confidence may deserve a larger penalty than a cautious response.
- Measure calibration, not just accuracy. Evaluation should consider whether confidence estimates match actual performance.
- Include unanswerable and ambiguous questions. Benchmarks should test situations where the best response is uncertainty or clarification. [Emergent Mind+2arXiv]api.emergentmind.comEmergent Mind Calibrated Selective ClassificationEmergent MindCalibrated Selective ClassificationAugust 25, 2022…
These ideas are closely related to the long-standing machine learning concept of the “reject option”, where a model is allowed to decline predictions when uncertainty is high. Research in selective prediction shows that carefully designed abstention mechanisms can improve the reliability of accepted answers, particularly in high-stakes settings. [Hugging Face]huggingface.coHugging Face Paper pageHugging FacePaper page - Conformalized Selective Regression…
The challenge is balancing caution and usefulness. A model that refuses every difficult question would avoid many mistakes but would not be very helpful. Effective benchmark design therefore requires rewarding justified uncertainty while still encouraging correct answers when evidence is sufficient. [Business Insider]businessinsider.comBusiness Insider Why AI chatbots hallucinate, according to Open AI researchersThis test-centric optimization encourages models to provide confident but potentially incorrect outputs, rather than abstaining when unsu…

Why This Matters for Trustworthy AI
When people evaluate AI systems, they often focus on how many questions the model can answer. Yet reliability depends just as much on recognising when an answer should not be given.
Benchmarks that ignore uncertainty risk rewarding the wrong behaviour. They can favour systems that sound authoritative regardless of their actual knowledge, creating a mismatch between leaderboard performance and user trust. By contrast, benchmarks that value calibrated uncertainty encourage models to communicate their limits more honestly. [Business Insider+2AI Insider]businessinsider.comBusiness Insider Why AI chatbots hallucinate, according to Open AI researchersThis test-centric optimization encourages models to provide confident but potentially incorrect outputs, rather than abstaining when unsu…
In the broader effort to understand artificial intelligence, this represents a shift from measuring pure capability to measuring judgement. A trustworthy system is not merely one that knows many answers. It is also one that can recognise the difference between knowledge, uncertainty and ignorance—and communicate that distinction clearly to the people relying on it. [arXiv]arxiv.orgBeyond "I Don't Know": Evaluating LLM Self-Awareness in Discriminating Data and Model UncertaintyApril 19, 2026…
Amazon book picks
Further Reading
Books and field guides related to Should AI Get Credit for Uncertainty?. Use these as the next step if you want deeper reading beyond the article.
Human Compatible
Directly discusses AI systems acting under uncertainty and why uncertainty about objectives should be preserved rather than hidden.
The Alignment Problem
Explores how AI systems make mistakes, misgeneralize and require better alignment with human goals.
Thinking in Bets
Provides a practical framework for reasoning under uncertainty instead of rewarding overconfident answers.
The Signal and the Noise
Explains calibration, forecasting and the limits of confident predictions.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: arxiv.org
Title: arXiv Abstention Bench: Reasoning LLMs Fail on Unanswerable Questions
Link: https://arxiv.org/abs/2506.09038Source snippet
AbstentionBench: Reasoning LLMs Fail on Unanswerable QuestionsJune 10, 2025...
Published: June 10, 2025
-
Source: techradar.com
Title: Tech Radar Think AI hallucinations are bad?
Link: https://www.techradar.com/pro/think-ai-hallucinations-are-bad-heres-why-youre-wrongSource snippet
Here's why you're wrongMarch 6, 2026 — The article challenges the common perception that AI hallucinations—instances where language model...
Published: March 6, 2026
-
Source: arxiv.org
Link: https://arxiv.org/abs/2604.17293Source snippet
Beyond "I Don't Know": Evaluating LLM Self-Awareness in Discriminating Data and Model UncertaintyApril 19, 2026...
Published: April 19, 2026
-
Source: businessinsider.com
Title: [Business]({{ ‘business-adoption/’ | relative_url }}) Insider Why AI chatbots hallucinate, according to Open AI researchers
Link: https://www.businessinsider.com/why-ai-chatbots-hallucinate-openai-chatgpt-anthropic-claude-2025-9Source snippet
This test-centric optimization encourages models to provide confident but potentially incorrect outputs, rather than abstaining when unsu...
-
Source: theaiinsider.tech
Link: https://theaiinsider.tech/2025/09/06/why-do-language-models-hallucinate-openai-scientists-say-llms-rewarded-for-being-too-cocky/ -
Source: huggingface.co
Title: Hugging Face Paper page
Link: https://huggingface.co/papers/2506.09038Source snippet
Hugging FacePaper page - AbstentionBench: Reasoning LLMs Fail on Unanswerable Questions...
-
Source: api.emergentmind.com
Title: Emergent Mind Calibrated Selective Classification
Link: https://api.emergentmind.com/papers/2208.12084Source snippet
Emergent MindCalibrated Selective ClassificationAugust 25, 2022...
Published: August 25, 2022
-
Source: huggingface.co
Title: Hugging Face Paper page
Link: https://huggingface.co/papers/2402.16300Source snippet
Hugging FacePaper page - Conformalized Selective Regression...
-
Source: huggingface.co
Title: Hugging Face Paper page
Link: https://huggingface.co/papers/2604.17073Source snippet
Hugging FacePaper page - Abstain-R1: Calibrated Abstention and Post-Refusal Clarification via Verifiable RL...
Additional References
-
Source: reddit.com
Title: Really good read if you have time, answered a lot of my questions
Link: https://www.reddit.com/r/nocode/comments/1nbotraSource snippet
released an article talking about why models hallucinate, here is the TLDR (done by Manus just being transparent) linked article at the b...
-
Source: reddit.com
Link: https://www.reddit.com/r/AgentsOfAI/comments/1q19yo9/why_do_llms_hallucinate_so_confidently_instead_of/Source snippet
do LLMs hallucinate so confidently instead of saying “I don’t know”?January 1, 2026...
Published: January 1, 2026
-
Source: youtube.com
Title: Hallucination Rate Explained in AI Testing | LLM Evaluation Metrics
Link: https://www.youtube.com/watch?v=nWJC6a72uHgSource snippet
Why AI Should Say “I Don't Know” More Often (with Matt Glickman) - YouTube Why AI Should Say “I Don't Know” More Often (with Matt Glickma...
-
Source: youtube.com
Title: Why AI Should Say “I Don’t Know” More Often (with Matt Glickman)
Link: https://www.youtube.com/watch?v=ZvXJN1SndNYSource snippet
LLM confidence calibration. Confidence Gap in high stakes decision making...
-
Source: youtube.com
Title: The Bullshit Benchmark: AI Can’t Say No
Link: https://www.youtube.com/watch?v=frKeo3dd4zMSource snippet
Hallucination Rate Explained in AI Testing | LLM Evaluation Metrics...
-
Source: aicommission.org
Link: https://aicommission.org/2025/09/openai-explains-why-language-models-hallucinate-evaluation-incentives-reward-guessing-over-uncertainty/
Topic Tree