Within Transformer shift
How parallel training unlocked bigger models
The Transformer mattered because it made massive training runs far easier to spread across modern hardware.
On this page
- Why recurrent training bottlenecked scale
- What parallel token processing changed
- Why scale made prediction more useful
Page outline Jump by section
Introduction
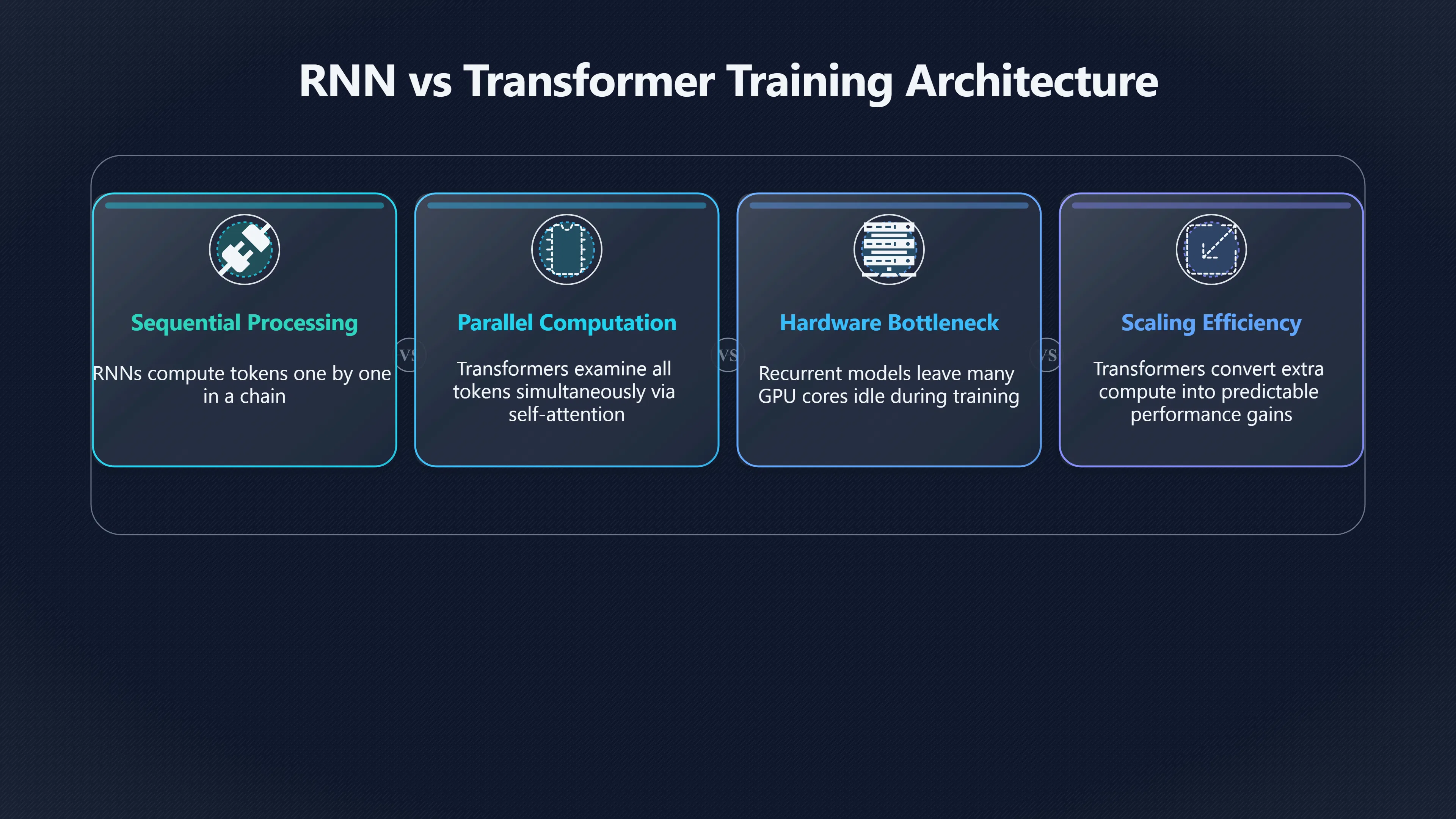
One of the most important consequences of the Transformer architecture was not simply that it improved language modelling. It made large-scale training practical. Before Transformers, many language models relied on recurrent neural networks (RNNs) and Long Short-Term Memory (LSTM) networks, which processed text one token at a time. That sequential design created a bottleneck: even with powerful hardware, much of the work had to wait for previous steps to finish. The Transformer removed that dependency and allowed far more computation to happen simultaneously. As a result, researchers could spread training across GPUs and later across enormous computing clusters, making today’s large language models economically and technically feasible. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
 The significance of this change is difficult to overstate. Modern AI systems depend not only on clever algorithms but also on whether those algorithms can efficiently use thousands of processors at once. The Transformer’s parallelism turned scaling from a severe obstacle into a practical engineering challenge. [arXiv+2JAX ML]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
The significance of this change is difficult to overstate. Modern AI systems depend not only on clever algorithms but also on whether those algorithms can efficiently use thousands of processors at once. The Transformer’s parallelism turned scaling from a severe obstacle into a practical engineering challenge. [arXiv+2JAX ML]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
Why recurrent training bottlenecked scale
Recurrent models process sequences step by step. To calculate the representation for token 100, the network must first compute token 99, which depends on token 98, and so on. This creates a chain of dependencies running through the entire sequence. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
That design caused two related problems:
- Training could not fully exploit parallel hardware because many operations had to occur in order.
- Longer sequences meant longer computation chains, reducing efficiency as datasets grew. [DEV Community]dev.toattention is all you need full paper breakdown 2kf3DEV CommunityAttention Is All You Need — Full Paper BreakdownMar 7, 2026 — No parallelization — each step depends on the previous hidden…
GPUs are designed to perform thousands of similar mathematical operations simultaneously. Recurrent architectures struggled to take advantage of that capability because each token’s computation depended on the result of the previous token. Adding more hardware helped somewhat through larger batches, but the core sequence processing remained sequential. [Artificial Intelligence Stack Exchange]ai.stackexchange.comwhy people always say the transformer is parallelizable while the self attentionArtificial Intelligence Stack ExchangeWhy people always say the Transformer is parallelizable…Jul 29, 2021 — The reason transformers a…
As model sizes and datasets expanded, this limitation became increasingly costly. Researchers could build larger recurrent models, but training time and hardware utilisation became major constraints. The architecture itself limited how efficiently additional computing resources could be used. [DEV Community]dev.toattention is all you need full paper breakdown 2kf3DEV CommunityAttention Is All You Need — Full Paper BreakdownMar 7, 2026 — No parallelization — each step depends on the previous hidden…
What parallel token processing changed
The Transformer replaced recurrence with self-attention. During training, the model can examine relationships among all tokens in a sequence simultaneously rather than advancing through them one by one. The mathematical operations involved are largely matrix multiplications, which GPUs and specialised AI accelerators handle extremely well. [arXiv+2Artificial Intelligence Stack Exchange]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
This does not mean the model ignores word order. Positional information is added separately. The crucial difference is that the network no longer needs to wait for a hidden state to propagate through every token in sequence. Many computations can occur at the same time. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
The original Transformer paper highlighted this advantage directly, describing the architecture as more parallelisable and requiring significantly less training time than leading recurrent approaches. On major machine translation benchmarks, the authors reported state-of-the-art performance while training on eight GPUs for a fraction of the cost of previous systems. [arXiv+2NeurIPS Papers]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
In practical terms, the shift meant that:
- More training examples could be processed per unit time.
- Larger batches could be distributed across multiple devices.
- Hardware utilisation improved substantially.
- Increasing computational resources produced more predictable speed gains. [arXiv+2LinkedIn]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
These advantages made the architecture far more compatible with modern computing infrastructure.

How parallelism enabled giant training runs
The Transformer’s parallel-friendly structure arrived just as large GPU and TPU clusters were becoming available. This combination proved decisive.
Once computations could be expressed as large matrix operations, researchers gained the ability to split work across many processors. Data parallelism distributed training examples across devices. Model parallelism divided enormous neural networks across multiple GPUs. Pipeline approaches distributed different layers across different machines. Together, these methods allowed training runs to grow from millions of parameters to billions and eventually hundreds of billions. [arXiv+2JAX ML]arxiv.orgOpen source on arxiv.org.
A useful illustration comes from Megatron-LM, a system developed to train multi-billion-parameter Transformer models. Researchers demonstrated efficient training of models with billions of parameters across hundreds of GPUs while maintaining high scaling efficiency. Such systems relied heavily on the Transformer’s structure because its computations can be partitioned and coordinated more effectively than recurrent architectures. [arXiv]arxiv.orgOpen source on arxiv.org.
The key insight is that the Transformer did not merely run faster on a single machine. It scaled more gracefully across many machines. That property became increasingly valuable as training budgets grew into the millions and later billions of pounds and dollars. [arXiv]arxiv.orgOpen source on arxiv.org.
Why scale made prediction more useful
Parallel training mattered because larger models consistently became better predictors.
As researchers increased parameter counts, training data, and computing power, they discovered surprisingly regular improvements in performance. Language models learned more facts, handled more complex instructions, generated more coherent text, and developed broader capabilities. Scaling laws later quantified this relationship, showing that performance often improves predictably as model size, data volume, and compute increase together. [ApX Machine Learning+2Ellis Unimore]apxml.comscaling laws transformersApX Machine LearningTransformer Scaling Laws Analysis2001.08361 - This paper introduced empirical scaling laws for language model perform…
Those scaling trends would have been far less useful if training larger systems remained prohibitively slow or inefficient. The Transformer created a path by which additional hardware could be converted into larger training runs. In effect, it transformed compute power into improved next-token prediction. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
This helps explain why modern AI progress is often described as a combination of three ingredients:

- Larger models. [ellis.unimore.it]ellis.unimore.itarXiv preprint. arXiv:2001.08361. Page 11. Scaling Laws apply to computer vision too. Increase in performance is…Read more…
- More data.
- More compute. [apxml.com]apxml.comscaling laws transformersApX Machine LearningTransformer Scaling Laws Analysis2001.08361 - This paper introduced empirical scaling laws for language model perform…
The Transformer’s contribution was making the third ingredient practical to apply at unprecedented scale. Without efficient parallel training, the other two would have delivered far smaller gains. [JAX ML+2ApX Machine Learning]jax-ml.github.ioscaling bookJAX MLHow To Scale Your Model4 Feb 2025 — This book aims to demystify the science of scaling language models: how TPUs (and GPUs) work an…
The lasting significance of parallel scale
The Transformer is often remembered for introducing self-attention, but from an implementation perspective its most transformative effect was enabling large-scale parallel computation. By removing the sequential bottlenecks that constrained recurrent models, it aligned language modelling with the strengths of modern hardware. [arXiv+2Introl]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
That alignment made it feasible to train increasingly large next-token predictors on vast datasets and distributed computing clusters. The resulting jump in scale was not a side effect of the Transformer revolution; it was one of the central reasons the revolution happened at all. [arXiv+2arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
Amazon book picks
Further Reading
Books and field guides related to How parallel training unlocked bigger models. Use these as the next step if you want deeper reading beyond the article.
Build a Large Language Model (From Scratch)
Explains transformer training, scaling, and computational efficiency.
Hands-On Large Language Models
Discusses transformer scaling, training infrastructure, and model growth.
Natural Language Processing with Transformers
Shows how transformer architectures exploit parallel computation.
Designing Machine Learning Systems
Explains scaling, infrastructure, and engineering constraints behind large AI systems.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: arxiv.org
Title: arXiv Attention Is All You Need
Link: https://arxiv.org/abs/1706.03762Source snippet
Attention Is All You NeedJune 12, 2017...
Published: June 12, 2017
-
Source: papers.neurips.cc
Title: 7181 attention is all you need
Link: https://papers.neurips.cc/paper/7181-attention-is-all-you-need.pdfSource snippet
NeurIPS PapersAttention is All you Needby A Vaswani · Cited by 247770 — Experiments on two machine translation tasks show these models to...
-
Source: jax-ml.github.io
Title: scaling book
Link: https://jax-ml.github.io/scaling-book/Source snippet
JAX MLHow To Scale Your Model4 Feb 2025 — This book aims to demystify the science of scaling language models: how TPUs (and GPUs) work an...
-
Source: arxiv.org
Link: https://arxiv.org/abs/1909.08053 -
Source: dev.to
Title: attention is all you need full paper breakdown 2kf3
Link: https://dev.to/seahjs/attention-is-all-you-need-full-paper-breakdown-2kf3Source snippet
DEV CommunityAttention Is All You Need — Full Paper BreakdownMar 7, 2026 — No parallelization — each step depends on the previous hidden...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/why-attention-all-you-need-deep-dive-transformer-model-padhy-cijwcSource snippet
Why 'Attention is All You Need': A Deep Dive into the...Advantages of Transformers Over RNNs/LSTMs · Faster Training: Parallel p...
-
Source: introl.com
Title: the transformer revolution how attention is all you need reshaped modern ai
Link: https://introl.com/blog/the-transformer-revolution-how-attention-is-all-you-need-reshaped-modern-aiSource snippet
Transformer Architecture: How Attention Changed AI | Introl Blog2 May 2025 — The 2017 Attention Is All You Need paper sparked an AI revol...
Published: May 2025
-
Source: ellis.unimore.it
Link: https://www.ellis.unimore.it/media/lecture_files/ELLIS_Modena_2023_-_Fiameni.pdfSource snippet
arXiv preprint. arXiv:2001.08361. Page 11. Scaling Laws apply to computer vision too. Increase in performance is...Read more...
-
Source: arxiv.org
Link: https://arxiv.org/html/2602.06057v1Source snippet
[Inference]({{ 'inference-test/' | relative_url }})-time Scaling Laws for Heterogeneous ComputingWe introduce a unified heterogeneous computing framework with MLIR-based compilati...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/understanding-groundbreaking-attention-all-you-need-research-disansa-becncSource snippet
ly on an attention mechanism to draw global dependencies (...Read more...
-
Source: ai.stackexchange.com
Title: why people always say the transformer is parallelizable while the self attention
Link: https://ai.stackexchange.com/questions/29903/why-people-always-say-the-transformer-is-parallelizable-while-the-self-attentionSource snippet
Artificial Intelligence Stack ExchangeWhy people always say the Transformer is parallelizable...Jul 29, 2021 — The reason transformers a...
-
Source: apxml.com
Title: scaling laws transformers
Link: https://apxml.com/courses/foundations-transformers-architecture/chapter-6-advanced-architectural-variants-analysis/scaling-laws-transformersSource snippet
ApX Machine LearningTransformer Scaling Laws Analysis2001.08361 - This paper introduced empirical scaling laws for language model perform...
Additional References
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/394854371_Revolutionizing_Vision_A_Deep_Dive_into_Attention_Is_All_You_Need_and_Its_Impact_on_AI_and_Machine_LearningSource snippet
A Deep Dive into "Attention Is All You Need" and Its Impact...Aug 23, 2025 — This research paper discusses in depth the transformer mode...
-
Source: medium.com
Link: https://medium.com/%40weidagang/coffee-time-papers-attention-is-all-you-need-3c7d6bc75eabSource snippet
Coffee Time Papers: Attention Is All You NeedEfficiency: The model achieves superior results while being more parallelizable and requirin...
-
Source: brandonrohrer.com
Link: https://brandonrohrer.com/transformers.htmlSource snippet
Transformers from ScratchA model that works with an embedding learns patterns in the embedded space. That means that whatever it learns t...
-
Source: se.com
Link: https://www.se.com/us/en/work/featured-articles/what-is-a-transformer/Source snippet
What is a TransformerA transformer is an electrical device that transfers energy from one electric circuit to another using the process o...
-
Source: medium.com
Link: https://medium.com/%40Elongated_musk/attention-is-all-you-need-until-you-need-memory-0450aa84af3f -
Source: towardsai.net
Link: https://towardsai.net/p/[machine-learningSource snippet
A Deep Dive into the Revolutionary Transformer Architecture10 Apr 2025 — The Transformer architecture, introduced in the seminal paper “A...
-
Source: levelup.gitconnected.com
Title: attention is all you need understanding the transformer model 10519074916f
Link: https://levelup.gitconnected.com/attention-is-all-you-need-understanding-the-transformer-model-10519074916fSource snippet
Is All You Need — Understanding the Transformer...2 Nov 2025 — Because sine and cosine functions are continuous and periodic, the model...
-
Source: waylandz.com
Link: https://waylandz.com/llm-transformer-book-en/appendix-a-scaling-laws-compute/Source snippet
summary: Scaling laws reveal that language model loss falls predictably as a power function of model size, dataset size, and compute — wh...
-
Source: medium.com
Link: https://medium.com/%40chilldenaya/transformer-attention-is-all-you-need-a-paper-summary-d5fa82ff65deSource snippet
on an attention mechanism to draw global dependencies between input and...Read more...
-
Source: medium.com
Link: https://medium.com/%40adnanmasood/attention-is-all-you-need-explained-like-youre-smart-and-busy-2a3d7436144fSource snippet
sier to learn and training far more parallelizable, it delivered...Read more...
Topic Tree