Within Speech cues
Why Hearing More Noise Can Improve Accuracy
Exposure to many noisy recordings helps speech models focus on speech cues that remain useful across changing environments.
On this page
- What multi condition training adds
- Data augmentation with noise and reverberation
- Performance on unseen environments
Page outline Jump by section
Introduction
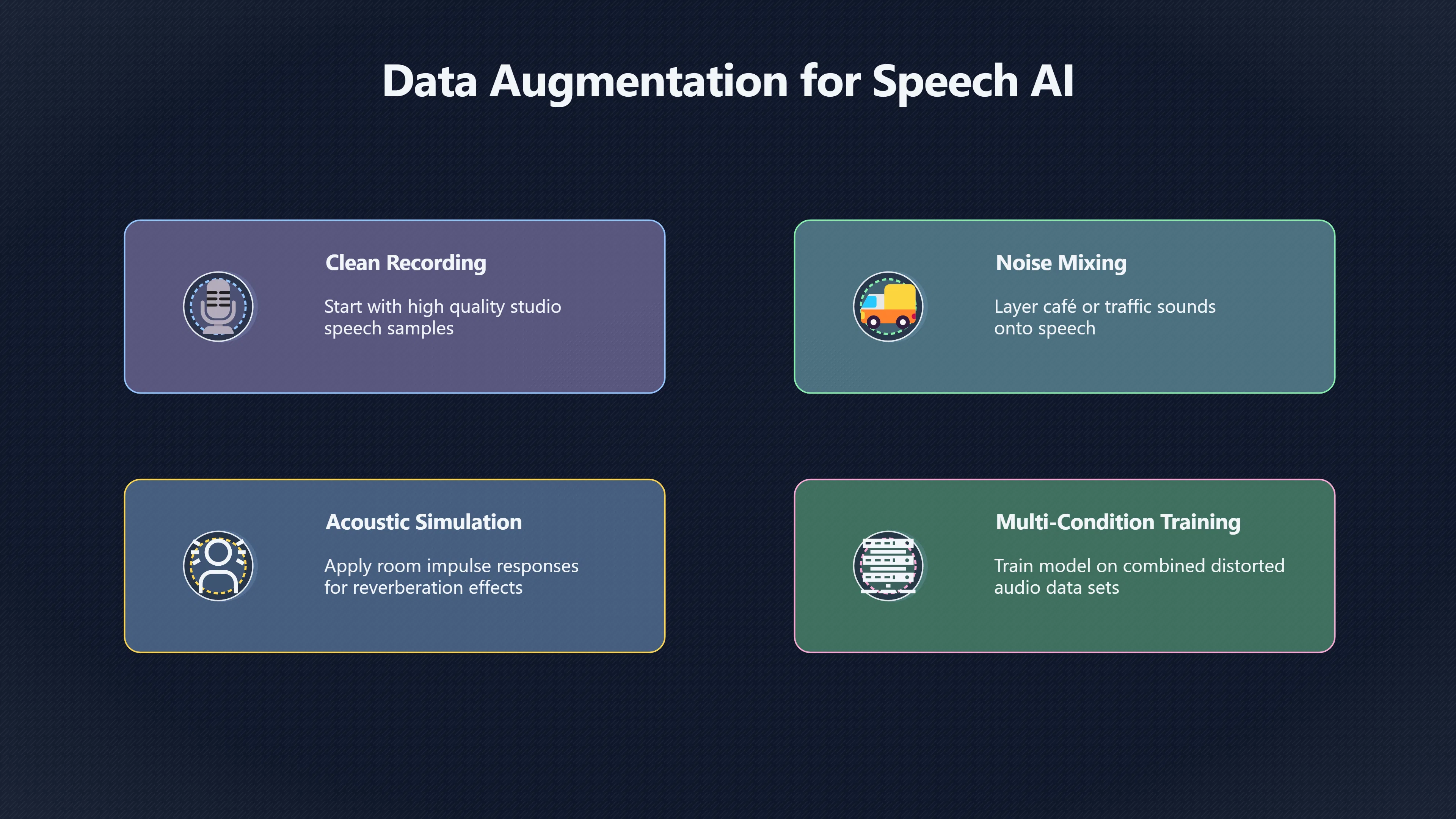
Modern speech-recognition systems are rarely trained only on clean recordings. Instead, they are often exposed to thousands of deliberately distorted examples containing traffic noise, crowd chatter, office sounds, wind, reverberation, microphone differences and other real-world variations. This strategy, known as multi-condition training, is one of the most effective ways to improve recognition accuracy when a system encounters noise it has never heard before. Rather than teaching a model to memorise specific background sounds, the goal is to help it learn which speech cues remain reliable across many acoustic conditions. Research over multiple generations of speech-recognition systems has shown that training on diverse noisy and reverberant audio consistently improves robustness and reduces the performance drop caused by mismatches between training and deployment environments. [danielpovey.com+2ResearchGate]danielpovey.coma study on data augmentation of reverberant speech for robustThe environmental robustness of DNN-based acous- tic models can be significantly improved by using multi- condition training data.Read more…

What Multi-Condition Training Adds
The central problem in noisy speech recognition is not simply noise itself but acoustic mismatch. A model trained on clean studio recordings may perform well in the laboratory yet struggle when deployed in a car, factory, meeting room or busy street. Even modern deep-learning systems can lose accuracy when evaluation conditions differ substantially from the data used during training. [SRI]sri.comFor mismatched conditions, data-adaptation.Read more…
Multi-condition training addresses this by presenting the same linguistic content under many acoustic conditions. During training, a spoken sentence might appear repeatedly with different distortions:
- Background conversations
- Traffic and transport noise
- Household sounds
- Different microphone characteristics
- Room reverberation
- Varying signal-to-noise ratios
Because the spoken words remain constant while the environment changes, the model is encouraged to focus on speech characteristics that are stable across conditions and to treat many environmental variations as irrelevant. Over time, the network learns representations that are less tied to any particular recording situation. [ResearchGate]researchgate.netOn Practical Aspects of Multi-condition Training Based…Multi-condition training achieved through data augmentation belongs…
This differs from traditional approaches that attempted to remove noise before recognition. Multi-condition training instead teaches the recogniser itself to operate under uncertainty, making robustness part of the learned model rather than an external correction stage. [Microsoft]microsoft.comAN INVESTIGATION OF DEEP NEURAL NETWORKS FOR…April 29, 2013 — by ML Seltzer · Cited by 850 — In this paper, we investigate th…
Data Augmentation with Noise and Reverberation
A major implementation challenge is obtaining enough real recordings from every possible environment. Collecting speech in thousands of rooms and noise conditions would be expensive and impractical. As a result, most modern systems create additional training examples through data augmentation. [danielpovey.com]danielpovey.coma study on data augmentation of reverberant speech for robustThe environmental robustness of DNN-based acous- tic models can be significantly improved by using multi- condition training data.Read more…
The process typically starts with clean speech recordings. Artificial distortions are then added:
Adding Background Noise
Recorded noise samples such as cafés, offices, vehicles or public spaces are mixed with clean speech at different intensity levels. The same sentence can therefore appear in many noisy forms. This exposes the model to a wide range of signal-to-noise conditions without requiring new speech recordings. [ResearchGate]researchgate.netData Augmentation for Training of Noise Robust Acoustic…February 1, 2017 — In this paper we analyse ways to improve the ac…
Simulating Room Acoustics
Speech behaves differently in a small office, lecture hall or living room because sound reflects from walls and surfaces. Researchers often use room impulse responses (RIRs) to simulate these effects and generate far-field recordings from close-microphone speech. Studies have shown that such simulated reverberation can substantially improve environmental robustness when incorporated into training. [danielpovey.com]danielpovey.coma study on data augmentation of reverberant speech for robustThe environmental robustness of DNN-based acous- tic models can be significantly improved by using multi- condition training data.Read more…

Combining Multiple Distortions
Many real environments contain several challenges simultaneously. Multi-condition training therefore often combines reverberation, noise and microphone variation within the same augmented dataset. This creates more realistic training conditions and helps models avoid becoming specialised for only one type of distortion. [ResearchGate]researchgate.netOn Practical Aspects of Multi-condition Training Based…Multi-condition training achieved through data augmentation belongs…
Why Exposure to Many Noises Helps with New Noises
A common misunderstanding is that a speech model must encounter every future noise during training. In practice, that is impossible. New environments constantly appear.
The benefit comes from learning broader statistical regularities. When a model experiences enough diverse distortions, it can identify patterns that consistently correspond to speech regardless of background conditions. Exposure to many examples effectively teaches the network which acoustic variations matter and which can be ignored. [danielpovey.com]danielpovey.coma study on data augmentation of reverberant speech for robustThe environmental robustness of DNN-based acous- tic models can be significantly improved by using multi- condition training data.Read more…
For example, a system trained with crowd noise, office noise and traffic noise may never have encountered a particular airport announcement system. Yet because it has repeatedly learned to separate speech structure from unrelated environmental sounds, it can often generalise better to that unfamiliar situation than a model trained only on clean audio. [SRI]sri.comFor mismatched conditions, data-adaptation.Read more…
This is one reason robust speech-recognition research frequently evaluates systems on unseen conditions rather than merely repeating known ones. Success depends not on memorising specific noises but on developing representations that remain useful when conditions change. [Mitsubishi Electric Labs]merl.comTR2015 138Environments) challenge aims to assess robustness of auto- matic speech recognition (ASR) systems to a…Read more…
Performance on Unseen Environments
Evidence from robust speech-recognition benchmarks consistently shows that models trained across multiple acoustic conditions outperform clean-only systems when noise and reverberation are present. Researchers studying far-field speech recognition, reverberant environments and noisy-channel conditions have repeatedly found that exposing acoustic models to varied distortions during training reduces performance degradation under mismatched testing conditions. [danielpovey.com+2SRI]danielpovey.coma study on data augmentation of reverberant speech for robustThe environmental robustness of DNN-based acous- tic models can be significantly improved by using multi- condition training data.Read more…
The effect is particularly important because real deployments rarely match laboratory conditions. Smart speakers, mobile assistants, vehicle interfaces and meeting-transcription systems all operate in environments that change from moment to moment. A model that has learned from diverse conditions typically experiences a more gradual decline in accuracy rather than a sudden failure when noise increases. [Deepgram]deepgram.comnoise robust speech recognition techniquesNoise-Robust Speech Recognition Techniques10 Mar 2026 — Learn which noise-robust speech recognition techniques survive production…
Research on the ASpIRE challenge, which focused on difficult reverberant and noisy recordings without matched training data, highlighted how severe condition mismatch can be and why robustness techniques are necessary for practical deployment. [Mitsubishi Electric Labs]merl.comTR2015 138Environments) challenge aims to assess robustness of auto- matic speech recognition (ASR) systems to a…Read more…
Beyond Basic Multi-Condition Training
Although standard multi-condition training remains a core technique, newer methods build upon the same principle.
Some approaches generate especially challenging training examples through adversarial augmentation, creating distortions designed to expose weaknesses in the current model. Experiments on benchmark tasks such as Aurora-4 and CHiME-4 showed improved robustness when these examples were added during training. [arXiv]arxiv.orgarXiv:1806.02782v2 [cs.CL] 17 Jun 2018June 19, 2018 — by S Sun · 2018 · Cited by 88 — This paper explores the use of adversarial exa…
Other methods refine the idea by mixing clean and distorted segments within the same utterance. Patched Multi-Condition Training (pMCT), introduced in 2022, demonstrated additional reductions in word error rate in noisy and reverberant conditions while retaining the underlying philosophy of exposing the model to richer acoustic variation. [ISCA Archive+2arXiv]isca-archive.orgpesoparada22 interspeechPatched Multi-Condition Training (pMCT) to improve ASR accuracy, especially for noisy reverberant…Read more…
Researchers have also explored explicit environmental representations, allowing systems to learn information about acoustic conditions alongside speech content. In some evaluations, these approaches outperformed conventional multi-condition training alone, particularly when dealing with highly reverberant or previously unseen noise environments. [arXiv]arxiv.orgarXiv Environmental Noise Embeddings for Robust Speech RecognitionEnvironmental Noise Embeddings for Robust Speech RecognitionJanuary 11, 2016…

Why This Matters for Speech AI
Within the broader story of how speech networks handle noisy voices, multi-condition training is one of the most practical and influential implementation choices. Its success comes from a simple idea: if a model hears speech under many different conditions during training, it becomes less dependent on any single condition. Instead of memorising specific environments, it learns speech cues that survive environmental change.
As a result, modern speech-recognition systems are better able to operate outside carefully controlled laboratories, maintaining useful accuracy even when confronted with new microphones, unfamiliar rooms and previously unseen background noise. [danielpovey.com+2ResearchGate]danielpovey.coma study on data augmentation of reverberant speech for robustThe environmental robustness of DNN-based acous- tic models can be significantly improved by using multi- condition training data.Read more…
Amazon book picks
Further Reading
Books and field guides related to Why Hearing More Noise Can Improve Accuracy. Use these as the next step if you want deeper reading beyond the article.
Speech and Language Processing: Pearson New International Edi...
Covers robust speech recognition and handling real-world variability.
Deep Learning
Rating: 3.5/5 from 6 Google Books ratings
Provides the deep learning principles behind data augmentation and robustness.
Hands-on Machine Learning with Scikit-Learn, Keras, and Tenso...
Demonstrates augmentation and generalisation strategies.
Fundamentals of Speech Recognition
Directly relevant to acoustic mismatch and noisy environments.
Endnotes
-
Source: danielpovey.com
Title: a study on data augmentation of reverberant speech for robust
Link: https://danielpovey.com/files/2017_icassp_reverberation.pdfSource snippet
The environmental robustness of DNN-based acous- tic models can be significantly improved by using multi- condition training data.Read more...
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/335554317_On_Practical_Aspects_of_Multi-condition_Training_Based_on_Augmentation_for_Reverberation-Noise-Robust_Speech_RecognitionSource snippet
On Practical Aspects of Multi-condition Training Based...Multi-condition training achieved through data augmentation belongs...
-
Source: sri.com
Link: https://www.sri.com/wp-content/uploads/2021/12/speech_recognition_in_unseen_and_noisy_channel_conditions.pdfSource snippet
For mismatched conditions, data-adaptation.Read more...
-
Source: microsoft.com
Link: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/0007398.pdfSource snippet
AN INVESTIGATION OF DEEP NEURAL NETWORKS FOR...April 29, 2013 — by ML Seltzer · Cited by 850 — In this paper, we investigate th...
Published: April 29, 2013
-
Source: deepgram.com
Title: noise robust speech recognition techniques
Link: https://deepgram.com/learn/noise-robust-speech-recognition-techniquesSource snippet
Noise-Robust Speech Recognition Techniques10 Mar 2026 — Learn which noise-robust speech recognition techniques survive [production]({{ 'retrieval-failures/' | relative_url }})...
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/313803208_Data_Augmentation_for_Training_of_Noise_Robust_Acoustic_ModelsSource snippet
Data Augmentation for Training of Noise Robust Acoustic...February 1, 2017 — In this paper we analyse ways to improve the ac...
Published: February 1, 2017
-
Source: isca-archive.org
Title: pesoparada22 interspeech
Link: https://www.isca-archive.org/interspeech_2022/pesoparada22_interspeech.pdfSource snippet
Patched Multi-Condition Training (pMCT) to improve ASR accuracy, especially for noisy reverberant...Read more...
-
Source: arxiv.org
Link: https://arxiv.org/pdf/1806.02782Source snippet
arXiv:1806.02782v2 [cs.CL] 17 Jun 2018June 19, 2018 — by S Sun · 2018 · Cited by 88 — This paper explores the use of adversarial exa...
Published: June 19, 2018
-
Source: arxiv.org
Link: https://arxiv.org/abs/2207.04949Source snippet
pMCT: Patched Multi-Condition Training for Robust...by PP Parada · 2022 · Cited by 14 — Training using patch-modified signals impro...
-
Source: arxiv.org
Title: arXiv Environmental Noise Embeddings for Robust Speech Recognition
Link: https://arxiv.org/abs/1601.02553Source snippet
Environmental Noise Embeddings for Robust Speech RecognitionJanuary 11, 2016...
Published: January 11, 2016
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/267727068_Multi-condition_Training_and_Adaptation_for_Noise_Robust_Speech_RecognitionSource snippet
multiple noise conditions, and its application to the new speaker and environment...Read more...
-
Source: arxiv.org
Link: https://arxiv.org/html/2407.17716v2Source snippet
more...
-
Source: isca-archive.org
Link: https://www.isca-archive.org/interspeech_2013/liu13c_interspeech.pdfSource snippet
Robust Speech Enhancement Techniques for ASR in Non-...by G Liu · 2013 · Cited by 9 — In this paper, we propose a cascaded system for sp...
-
Source: merl.com
Title: TR2015 138
Link: https://merl.com/publications/docs/TR2015-138.pdfSource snippet
Environments) challenge aims to assess robustness of auto- matic speech recognition (ASR) systems to a...Read more...
Additional References
-
Source: dspace.tul.cz
Link: https://dspace.tul.cz/items/ad95dbcb-c97e-40c6-b031-6109533ff9f3Source snippet
Practical Aspects of Multi-condition Training Based...Multi-condition training achieved through data augmentation belongs to the most su...
-
Source: semanticscholar.org
Link: https://www.semanticscholar.org/paper/a91820efd1d73f642214bdde8e3920aa62973635Source snippet
successful techniques for noise/reverberation-robust automatic speech...
-
Source: patents.google.com
Link: https://patents.google.com/patent/US20240013775A1/enSource snippet
Google PatentsPatched multi-condition training for robust speech recognitionThe present [disclosure]({{ 'disclosure/' | relative_url }}) presents pMCT, a data augmentation app...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=Lj1noABUYH8Source snippet
Whisper Explained | Robust Speech Recognition at Internet Scale (Full Audiobook)...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=X9e5Tto-IukSource snippet
Whisper Explained | Robust Speech Recognition at Internet Scale (Full Audiobook) Whisper Explained | Robust Speech Recognition at Interne...
-
Source: ee.ucla.edu
Link: https://www.ee.ucla.edu/~spapl/paper/cui_icslp02.pdfSource snippet
of Noise Robust Features on the Aurora...by X Cui · Cited by 22 — In this paper, we evaluate our noise robust feature extraction al- gor...
-
Source: youtube.com
Title: Audio Data Augmentation Is All You Need
Link: https://www.youtube.com/watch?v=HH_h52I_QegSource snippet
Automatic Speech Recognition (ASR): Acoustic vs [Language Models]({{ 'language-models/' | relative_url }}) and Why Transcription Errors Happen...
-
Source: mediatum.ub.tum.de
Link: https://mediatum.ub.tum.de/doc/1625437/4kiwe41yxsl9c6c3eao7jvg3h.Lujun_Li_Dissertation_070620221947.pdfSource snippet
and End-to-End Approaches for Noise Robust...by L Li · 2022 — While recent breakthroughs have tremendously improved ASR performance, the...
-
Source: www-i6.informatik.rwth-aachen.de
Title: Keynote Chin Hui Lee
Link: https://www-i6.informatik.rwth-aachen.de/web/Listen/PDFs/Keynote-Chin-Hui-Lee.pdfSource snippet
Better enhancement put clean model on top? -46.48% baseline single-channel. 20. 40. 60.Read more...
-
Source: home.ustc.edu.cn
Link: https://home.ustc.edu.cn/~xiaosong/paper/INTERSPEECH2014.pdfSource snippet
Speech Recognition with Speech Enhanced Deep...by J Du · 2014 · Cited by 171 — These observa- tions confirm that using multiple noise ty...
Topic Tree