Within Forecasting gap
Can future questions expose real AI skill?
Unresolved forecasting questions reduce memorisation shortcuts and reveal whether models can reason under genuine uncertainty.
On this page
- Why unresolved events reduce contamination
- What forecasting benchmarks measure
- Limits of benchmark scores for real decisions
Page outline Jump by section
Introduction
Many AI benchmarks test systems on questions that already have known answers. That creates a persistent problem: a model may appear intelligent because it has seen similar material during training, because benchmark questions have leaked into public datasets, or because it can exploit subtle patterns in the test itself. Future-event benchmarks take a different approach. They ask questions whose answers do not yet exist when the prediction is made. As a result, they offer a cleaner way to evaluate whether an AI system can reason under uncertainty rather than merely retrieve information. Forecasting benchmarks have become an important tool for understanding artificial intelligence because they reduce opportunities for memorisation and force models to reveal how well they handle genuinely unknown outcomes. [arXiv]arxiv.orgarXiv Forecast Bench: A Dynamic Benchmark of AI Forecasting CapabilitiesForecastBench: A Dynamic Benchmark of AI Forecasting CapabilitiesSeptember 30, 2024…

Why unresolved events reduce contamination
The central advantage of future-event benchmarks is simple: the correct answer is unavailable at evaluation time.
In a traditional benchmark, researchers know the answer before testing begins. Even when benchmark designers are careful, there is always a risk that parts of the test entered the model’s training data, appeared in online discussions, or became embedded in publicly available solutions. This phenomenon, often called benchmark contamination or data leakage, can make performance look better than it really is.
Forecasting benchmarks are designed to avoid this problem. ForecastBench, one of the best-known examples, uses only questions about future events whose outcomes are unknown when forecasts are submitted. The benchmark was explicitly created to eliminate the possibility that a model could have memorised the answer in advance. Questions are continuously refreshed, creating a moving target rather than a fixed exam that can gradually become familiar to AI systems. [arXiv+2arXiv]arxiv.orgarXiv Forecast Bench: A Dynamic Benchmark of AI Forecasting CapabilitiesForecastBench: A Dynamic Benchmark of AI Forecasting CapabilitiesSeptember 30, 2024…
This design changes what is being measured. Instead of asking, “Does the model know the answer?”, the benchmark asks, “Can the model form a well-calibrated belief about an uncertain event?” That distinction makes forecasting a closer test of judgement than of recall.
A useful comparison comes from newer “live” forecasting benchmarks such as FutureX and Prophet Arena, which likewise focus on unresolved real-world events. Their designers argue that continuously updating future questions are necessary because static datasets eventually become vulnerable to contamination as models absorb more internet content over time. [arXiv]arxiv.orgFutureX: An Advanced Live Benchmark for LLM Agents in…August 16, 2025 — by Z Zeng · 2025 · Cited by 21 — While ForecastBench [15]…
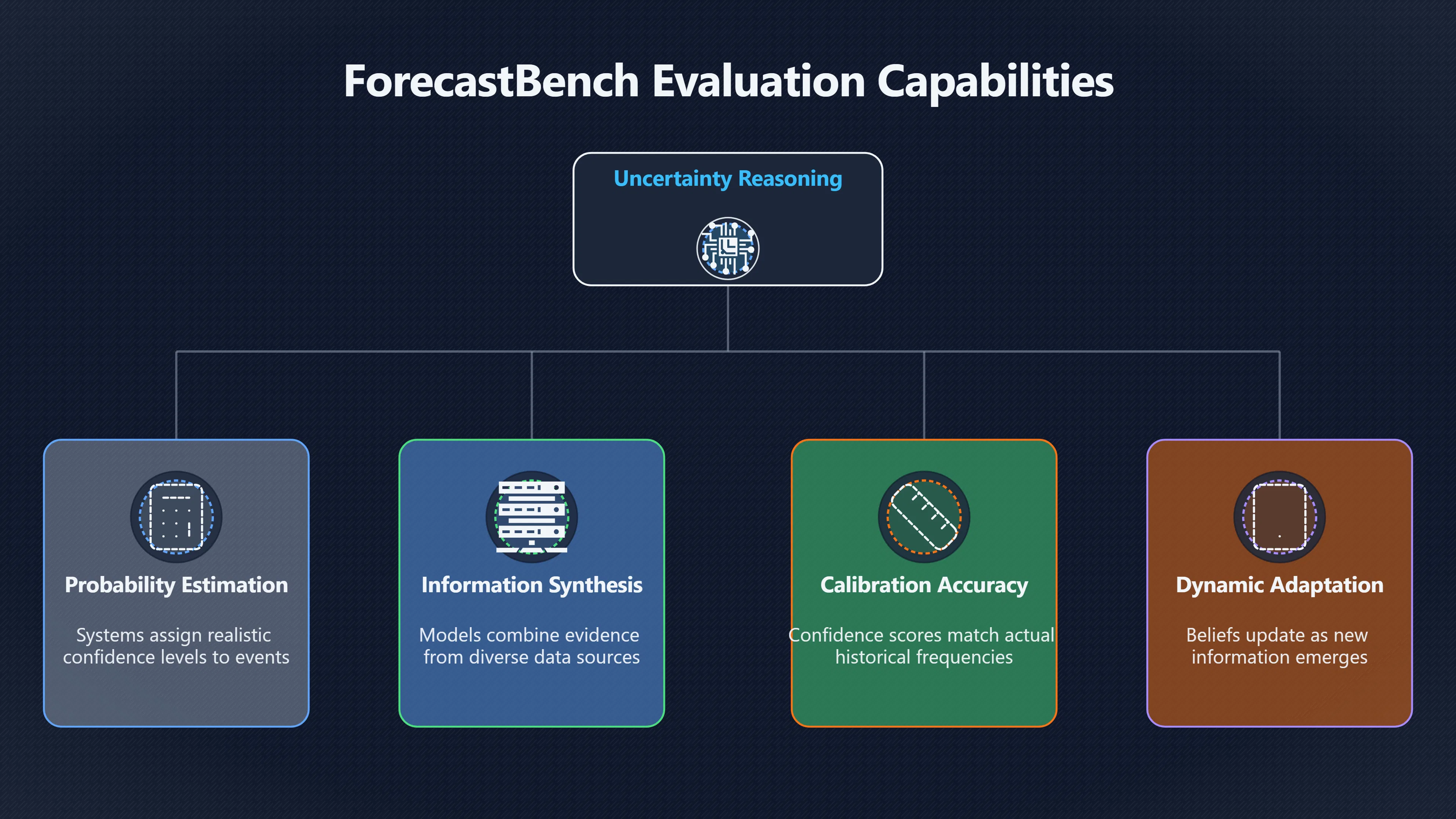
What forecasting benchmarks measure
Because future-event benchmarks remove answer memorisation as a shortcut, they highlight several capabilities that are often harder to observe in conventional tests.
These benchmarks typically evaluate:
- Reasoning under uncertainty: identifying which factors matter and how strongly they should influence a prediction.
- Probability estimation: assigning realistic confidence levels rather than simply choosing an outcome.
- Information synthesis: combining evidence from different domains and sources.
- Calibration: matching confidence to reality over many predictions.
- Adaptation to changing conditions: updating beliefs as new information appears. [arXiv+2arXiv]arxiv.orgA Dynamic Benchmark of AI Forecasting CapabilitiesA forecasting question asks for a probabilistic prediction of a future event. A fo…
ForecastBench illustrates this shift. Rather than scoring a model on right-or-wrong answers alone, it evaluates probabilistic forecasts using forecasting metrics such as Brier scores, which reward accurate confidence estimates and penalise overconfidence. A model that predicts a 90% chance for many events that do not occur will perform poorly even if its explanations sound convincing. [ForecastBench]forecastbench.orgDocsThe repository contains the full pipeline for generating forecasting questions from time-series data, evaluating LLM and…
This emphasis is important because real-world decisions rarely involve certainty. Governments, businesses, investors, and researchers often need estimates of likelihood rather than definitive answers. A benchmark that measures uncertainty handling therefore captures a skill that many practical applications require.

A concrete example: ForecastBench
ForecastBench provides a useful case study because its entire structure is built around contamination-resistant evaluation.
The benchmark maintains a large and regularly updated pool of forecasting questions covering future developments. Researchers compare forecasts from language models, members of the public, and expert forecasters using the same questions and scoring methods. Because outcomes are unresolved when predictions are generated, every participant faces the same uncertainty. [arXiv]arxiv.orgarXiv Forecast Bench: A Dynamic Benchmark of AI Forecasting CapabilitiesForecastBench: A Dynamic Benchmark of AI Forecasting CapabilitiesSeptember 30, 2024…
One notable result is that expert human forecasters have outperformed the strongest language models on benchmark evaluations. This finding is striking because many standard AI benchmarks show frontier models matching or exceeding human performance. Forecasting exposes weaknesses that are less visible on tests with known answers, suggesting that prediction under uncertainty remains a challenging frontier. [arXiv+2Wharton Faculty Platform]arxiv.orgarXiv Forecast Bench: A Dynamic Benchmark of AI Forecasting CapabilitiesForecastBench: A Dynamic Benchmark of AI Forecasting CapabilitiesSeptember 30, 2024…
The benchmark’s creators describe it as a contamination-free measure of forecasting accuracy and a potential proxy for broader intelligence because success requires combining knowledge, judgement, and uncertainty estimation rather than relying on stored answers. [ForecastBench]forecastbench.orgForecastBenchA dynamic, contamination-free benchmark of LLM forecasting accuracy with human comparison groups, serving as a…
Why cleaner benchmarks matter for understanding AI
A benchmark is valuable only if its scores reflect genuine capability.
When benchmark contamination occurs, improvements in scores may partly reflect exposure to answers rather than advances in reasoning. Future-event evaluations reduce that ambiguity. If a model consistently produces better forecasts before outcomes are known, the improvement is more likely to represent a real increase in predictive ability.
This does not mean forecasting is the only useful benchmark type. Mathematics, coding, and factual reasoning tests still reveal important capabilities. However, future-event benchmarks occupy a distinctive role because they remove one of the most persistent concerns in AI evaluation: whether the system is succeeding by remembering rather than thinking.
For researchers trying to understand the true strengths and weaknesses of artificial intelligence, that cleaner signal is valuable. It helps separate fluency from judgement, confidence from calibration, and knowledge retrieval from the harder task of making sense of an uncertain future. [arXiv+2OpenReview]arxiv.orgarXiv Forecast Bench: A Dynamic Benchmark of AI Forecasting CapabilitiesForecastBench: A Dynamic Benchmark of AI Forecasting CapabilitiesSeptember 30, 2024…

Limits of benchmark scores for real decisions
Even contamination-resistant benchmarks are not perfect measures of real-world intelligence.
First, forecasting questions capture only part of what people mean by reasoning. A model could become highly skilled at producing probability estimates yet still struggle with other tasks such as long-term planning, scientific discovery, or social interaction.
Second, benchmark designers must decide which future events to include. Different question sets may favour different strengths. Economic indicators, elections, technological developments, and geopolitical events all involve distinct forms of uncertainty. [arXiv]arxiv.orgFutureX: An Advanced Live Benchmark for LLM Agents in…August 16, 2025 — by Z Zeng · 2025 · Cited by 21 — While ForecastBench [15]…
Third, benchmark scores do not automatically translate into decision quality. A model may achieve strong forecasting performance while still producing explanations that contain errors or omit important context. Conversely, a useful decision-support system may combine forecasting with other capabilities not measured by a forecasting benchmark.
For these reasons, future-event benchmarks should be viewed as a powerful evaluation tool rather than a complete definition of intelligence. Their main contribution is narrower but highly valuable: they provide one of the clearest available tests of whether an AI system can operate when neither it nor its evaluators yet know the answer. [arXiv+2ForecastBench]arxiv.orgarXiv Forecast Bench: A Dynamic Benchmark of AI Forecasting CapabilitiesForecastBench: A Dynamic Benchmark of AI Forecasting CapabilitiesSeptember 30, 2024…
Amazon book picks
Further Reading
Books and field guides related to Can future questions expose real AI skill?. Use these as the next step if you want deeper reading beyond the article.
Forecasting: principles and practice
Provides structured approaches to forecasting and evaluation.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: arxiv.org
Title: arXiv Forecast Bench: A Dynamic Benchmark of AI Forecasting Capabilities
Link: https://arxiv.org/abs/2409.19839Source snippet
ForecastBench: A Dynamic Benchmark of AI Forecasting CapabilitiesSeptember 30, 2024...
Published: September 30, 2024
-
Source: openreview.net
Link: https://openreview.net/forum?id=lfPkGWXLLfSource snippet
ForecastBench: A Dynamic Benchmark of AI Forecasting...by E Karger · Cited by 48 — To avoid any possibility of data leakage, F...
-
Source: arxiv.org
Link: https://arxiv.org/pdf/2409.19839Source snippet
2409.19839v5 [cs.LG] 28 Feb 2025by E Karger · 2024 · Cited by 48 — To address these drawbacks, we introduce ForecastBench, a dynami...
-
Source: forecastbench.org
Link: https://www.forecastbench.org/about/Source snippet
AboutForecastBench is a dynamic, continuously-updated benchmark designed to measure the accuracy of ML systems on a constantly changing s...
-
Source: arxiv.org
Link: https://arxiv.org/pdf/2508.11987Source snippet
FutureX: An Advanced Live Benchmark for LLM Agents in...August 16, 2025 — by Z Zeng · 2025 · Cited by 21 — While ForecastBench [15]...
Published: August 16, 2025
-
Source: arxiv.org
Link: https://arxiv.org/html/2409.19839v5Source snippet
A Dynamic Benchmark of AI Forecasting CapabilitiesA forecasting question asks for a probabilistic prediction of a future event. A fo...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2502.19676Source snippet
[2502.19676] FOReCAst: The Future Outcome Reasoning...by Z Yuan · 2025 · Cited by 3 — We introduce FOReCAst (Future Outcome Reasoning an...
-
Source: forecastbench.org
Link: https://www.forecastbench.org/docs/Source snippet
DocsThe repository contains the full pipeline for generating forecasting questions from time-series data, evaluating LLM and...
-
Source: forecastbench.org
Link: https://www.forecastbench.org/Source snippet
ForecastBenchA dynamic, contamination-free benchmark of LLM forecasting accuracy with human comparison groups, serving as a...
-
Source: arxiv.org
Link: https://arxiv.org/html/2507.04562v2Source snippet
Evaluating LLMs on Real-World Forecasting Against...Aug 1, 2025 — This paper proposes a new form of benchmark: beating human foreca...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2506.21558Source snippet
A Pastcasting Benchmark for Forecasting Agentsby J Wildman · 2025 · Cited by 8 — We introduce Bench To the Future (BTF), a pastcasting be...
-
Source: arxiv.org
Link: https://arxiv.org/pdf/2507.19477Source snippet
Advancing Event Forecasting through Massive Training of...by SW Lee · 2025 · Cited by 1 — The ForecastBench paper (Karger et al., 2025)...
-
Source: arxiv.org
Link: https://arxiv.org/html/2604.15859v1Source snippet
Yet existing evaluations of large language models remain limited...Read more...
-
Source: faculty.wharton.upenn.edu
Link: https://faculty.wharton.upenn.edu/wp-content/uploads/2026/02/ForecastBench_A_Dynamic_.pdfSource snippet
Wharton Faculty PlatformFORECASTBENCH:ADYNAMIC BENCHMARK OF AI...by E Karger · Cited by 57 — While LLMs have achieved super-human perfor...
-
Source: huggingface.co
Link: https://huggingface.co/papers/2409.19839Source snippet
ForecastBench: A Dynamic Benchmark of AI Forecasting...Sep 29, 2024 — ForecastBench evaluates ML systems' forecasting accuracy through a...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/forecasting-research-institute_forecastbench-activity-7381675405897932800-pA4PSource snippet
ForecastBench update: LLMs vs SuperforecastersThe Superforecasters' Brier score on ForecastBench is 0.081, outperforming by 20% the best...
-
Source: forum.effectivealtruism.org
Title: announcing forecastbench a new benchmark for ai and human
Link: https://forum.effectivealtruism.org/posts/zwzgR8iuFEcJms3Hu/announcing-forecastbench-a-new-benchmark-for-ai-and-humanSource snippet
ForecastBench, a new benchmark for AI and...Oct 1, 2024 — ForecastBench is a new dynamic benchmark for evaluating AI and human forecasti...
-
Source: liner.com
Title: forecastbench a dynamic benchmark of ai forecasting capabilities
Link: https://liner.com/review/forecastbench-a-dynamic-benchmark-of-ai-forecasting-capabilitiesSource snippet
ForecastBench: A Dynamic Benchmark of AI Forecasting...30 Sept 2024 — ForecastBench evaluates LLMs against human forecasters, showing th...
-
Source: emergentmind.com
Link: https://www.emergentmind.com/topics/forecastbenchSource snippet
Superforecasters significantly outperform both LLMs and the public (p < 0.001 p<0.001 p<0.001). On...Read more...
Additional References
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/nicholas-stetler_forecastbench-activity-7381826956960522240-BF6XSource snippet
AI surpasses humans in predicting the futureThe Superforecasters' Brier score on ForecastBench is 0.081, outperforming by 20% the best of...
-
Source: huggingface.co
Link: https://huggingface.co/papers?q=sales+forecastingSource snippet
Daily PapersIn addition to reporting on ForecastBench, we also introduce a more challenging forecasting benchmark sourced from liquid pre...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/stevenjose_llm-promptengineering-compressedintelligence-activity-7347112013367603201-frJoSource snippet
Steven Joseph's PostThe Superforecasters' Brier score on ForecastBench is 0.081, outperforming by 20% the best of the LLMs at 0.101, seem...
-
Source: proceedings.iclr.cc
Link: https://proceedings.iclr.cc/paper_files/paper/2025/hash/ea74e45a229dac70b5b63b28d8934db6-Abstract-Conference.htmlSource snippet
Dynamic Benchmark of AI Forecasting CapabilitiesWe quantify the capabilities of current ML systems by collecting forecasts from expert (h...
-
Source: researchgate.net
Title: 394539483 FutureX An Advanced Live Benchmark for LLM Agents in Future Prediction
Link: https://www.researchgate.net/publication/394539483_FutureX_An_Advanced_Live_Benchmark_for_LLM_Agents_in_Future_PredictionSource snippet
FutureX: An Advanced Live Benchmark for LLM Agents in...Aug 19, 2025 — PDF | Future prediction is a complex task for LLM agents, requiri...
-
Source: tldr.takara.ai
Link: https://tldr.takara.ai/p/2506.21558Source snippet
to the Future: A Pastcasting Benchmark for Forecasting AgentsForecastBench: A Dynamic Benchmark of AI Forecasting Capabilities...
-
Source: researchgate.net
Title: 384502750 ForecastBench A Dynamic Benchmark of AI Forecasting Capabilities
Link: https://www.researchgate.net/publication/384502750_ForecastBench_A_Dynamic_Benchmark_of_AI_Forecasting_CapabilitiesSource snippet
A Dynamic Benchmark of AI Forecasting Capabilities30 Sept 2024 — While LLMs have achieved super-human performance on many benchmarks, the...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=1Hw7U4gAZwISource snippet
"Get the full story on all of this and much more - read the full edition of today's Century Report here: [https://sharedsapience.com/the-ce..."](https://sharedsapience.com/the-ce...")...
-
Source: youtu.be
Link: https://youtu.be/IOIM-APSCokSource snippet
👉In this video, we break down target leakage, temporal leakage, and train-test contamination with clear examples and practical prevention...
-
Source: youtu.be
Link: https://youtu.be/BanqTNbTotUSource snippet
"The Good Future (2021) [https://www.thegoodfuturefilm.com](https://www.thegoodfuturefilm.com) or [https://youtu.be/yHC5n7G5SeI](https://youtu.be/yHC5n7G5SeI) The future of work: [http://www.howthefutureworks..."](http://www.howthefuture...
Topic Tree