Within Transformers
How does attention find the right context?
Self-attention gives a model a direct way to link words, image patches, or other tokens that are far apart but meaningfully related.
On this page
- Queries, keys, and values in plain language
- Why distant relationships matter for meaning
- Where attention helps and where it falls short
Page outline Jump by section
Introduction
Self-attention gives modern AI systems a direct way to connect pieces of information that may be far apart in a sequence. Instead of processing text, image patches, or other tokens only through a chain of neighbouring steps, self-attention allows every token to compare itself with every other token and decide which ones matter most. This ability is one of the main reasons Transformer-based models can understand relationships that span long distances, such as linking a pronoun to a noun mentioned many words earlier or connecting related regions of an image. The mechanism was introduced as a core part of the Transformer architecture in the landmark paper Attention Is All You Need and remains central to today’s large language models. [NeurIPS Papers]papers.neurips.cc7181 attention is all you needNeurIPS PapersAttention is All you Needby A Vaswani · Cited by 246782 — An attention function can be described as mapping a query and a s…

Queries, keys, and values in plain language
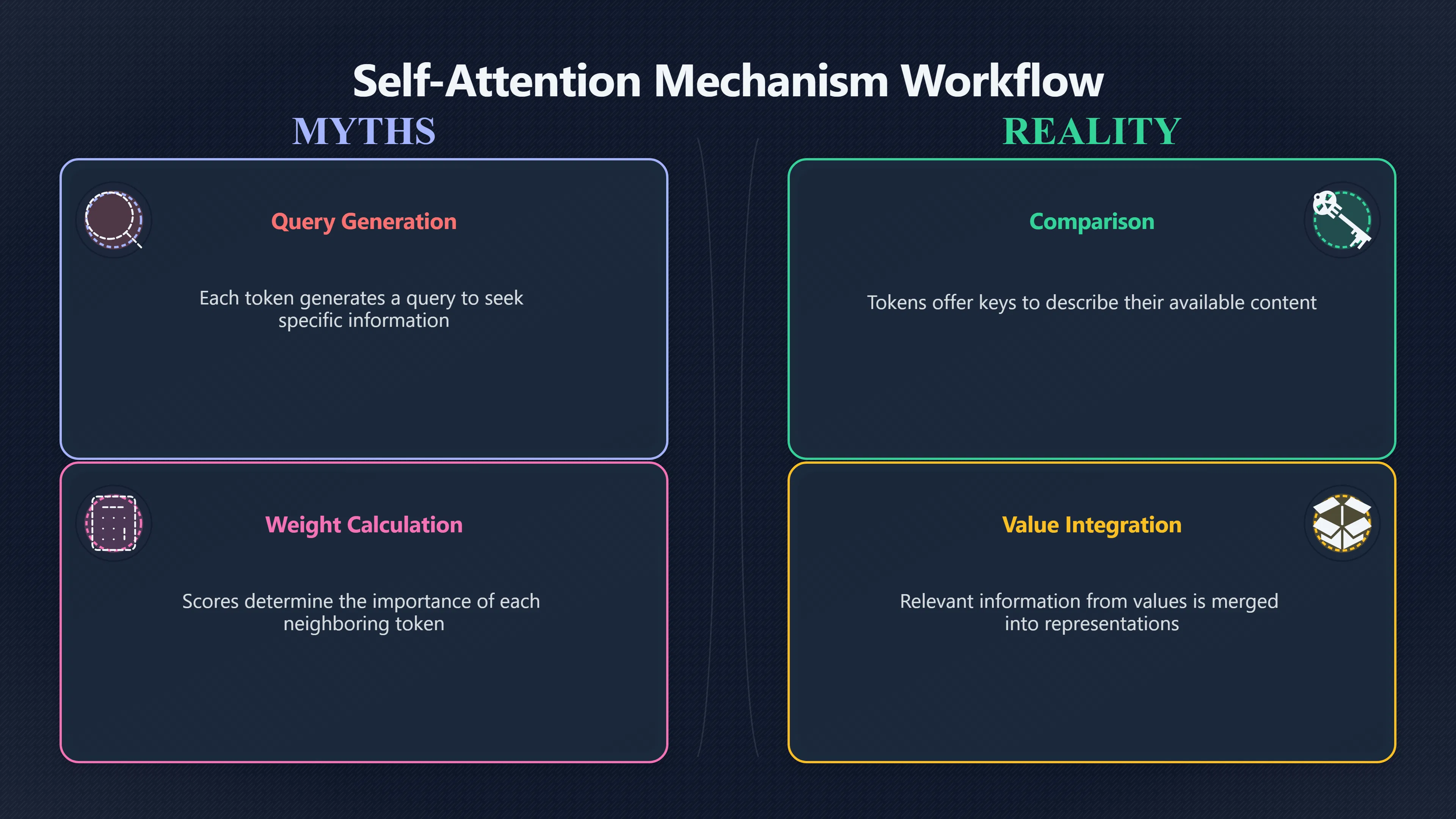
Self-attention works through three learned representations attached to every token: a query, a key, and a value. The original Transformer paper describes attention as a process that maps a query and a set of key–value pairs into an output. [NeurIPS Papers]papers.neurips.cc7181 attention is all you needNeurIPS PapersAttention is All you Needby A Vaswani · Cited by 246782 — An attention function can be described as mapping a query and a s…
A useful way to think about them is:
- Query: What information is this token looking for?
- Key: What information does this token offer?
- Value: What information can be passed along if the token is considered relevant?
Imagine the sentence:
“Sarah put the book on the shelf because it was full.”
When the model reaches the word “it”, its query is compared with the keys of all other words in the sentence. If the learned patterns suggest that “full” is more likely to describe “shelf” than “book”, the attention score between “it” and “shelf” becomes stronger. Information from the value associated with “shelf” is then incorporated into the representation of “it”.
The important point is that the model does not have to travel word by word through the sentence to discover this relationship. It can create a direct connection between the two tokens regardless of the number of words between them. Self-attention therefore allows each position in a sequence to attend to every other position. [DeepLearning.AI]community.deeplearning.aiis all you need - GenAI with LLMs ResourcesJul 27, 2023 — Self-attention layers allow each position in the sequence to attend to all othe…
Why distant relationships matter for meaning
Human language is full of long-range dependencies. A name may appear at the start of a paragraph and be referenced much later. A condition stated in one clause may completely change the meaning of another clause dozens of words away.
Older recurrent neural networks (RNNs) and long short-term memory (LSTM) networks could, in principle, carry information across long sequences, but information often had to pass through many intermediate steps. This made distant relationships harder to learn and maintain. Transformers changed that by creating direct links between positions. [Medium+2Medium]medium.comAttention Is All You Need, explained like you're smart and…Long-range dependencies are hard because information has to travel th…
A common description of the advantage is that self-attention reduces the number of computational steps needed for one token to influence another. Rather than passing information through a long chain, the model can compare the two positions immediately. This makes long-range dependencies easier to learn during training. [Medium]sh-tsang.medium.comReview — Attention Is All You Need (Transformer)A self-attention layer connects all positions with a constant number of sequentiall…
Consider several examples:
- Pronoun resolution: Determining who “she”, “he”, or “they” refers to.
- Translation: Connecting a word in one language with a related phrase that appears much later in another language.
- Question answering: Matching a question with a relevant fact buried deep in a passage.
- Image understanding: Relating distant image patches that belong to the same object.
In all of these cases, the crucial information may not be nearby. Self-attention provides a mechanism for bringing the relevant pieces together. [DataCamp+2PatSnap Eureka]datacamp.comSelf-Attention Explained: The Mechanism Powering…2 Mar 2026 — Transformer models excel at capturing long-range dependencies th…

How attention chooses the right context
Self-attention does not simply connect everything equally. It calculates a score between the query of one token and the keys of all other tokens. Those scores are converted into weights that determine how much influence each value should have on the final representation. [NeurIPS Papers+2arXiv]papers.neurips.cc7181 attention is all you needNeurIPS PapersAttention is All you Needby A Vaswani · Cited by 246782 — An attention function can be described as mapping a query and a s…
As a result, a token receives a customised view of the sequence.
The word “bank”, for example, might attend strongly to “river” in one sentence and to “loan” in another. The surrounding context changes which tokens receive the highest attention weights. This dynamic behaviour allows the same word to take on different meanings depending on its context.
Modern Transformers also use multi-head attention, where several attention mechanisms operate in parallel. Different heads can specialise in different patterns. One head might focus on grammatical relationships, another on semantic similarity, and another on long-distance references. Together they provide multiple pathways for information to move across a sequence. [Wikipedia]WikipediaAttention Is All You NeedAttention Is All You Need
Where attention helps and where it falls short
Self-attention is powerful, but it is not magic.
One limitation is computational cost. Because every token can potentially compare itself with every other token, the amount of work grows rapidly as sequences become longer. This challenge has motivated research into more efficient attention mechanisms for very large contexts. [Medium]sh-tsang.medium.comReview — Attention Is All You Need (Transformer)A self-attention layer connects all positions with a constant number of sequentiall…
Another limitation is that attention does not guarantee true understanding. The mechanism helps the model connect relevant information, but it still learns statistical patterns from data rather than reasoning in a human sense.
There is also an important interpretability issue. Attention weights are often visualised as heat maps showing which tokens appear important. However, research has shown that attention weights should not automatically be treated as explanations for a model’s decisions. Different attention patterns can sometimes produce similar outputs, and attention scores do not always align with other measures of feature importance. [arXiv+2ACL Anthology]arxiv.orgarXiv Attention is not ExplanationAttention is not ExplanationFebruary 26, 2019…
For that reason, attention is best understood as a routing mechanism: it helps information flow between distant parts of an input, but it is not a complete explanation of how a model arrives at a conclusion.

The key idea to remember
The central achievement of self-attention is simple but profound: it allows any token to directly examine and incorporate information from any other token in the same sequence. By using queries, keys, and values to decide which relationships matter, the mechanism can connect clues that are separated by many words, image regions, or data elements. This ability to model long-range dependencies efficiently is one of the defining features that made Transformer-based AI systems so effective across language, vision, and many other domains. [Dlvr Rantai+3NeurIPS Papers+3arXiv]papers.neurips.cc7181 attention is all you needNeurIPS PapersAttention is All you Needby A Vaswani · Cited by 246782 — An attention function can be described as mapping a query and a s…
Amazon book picks
Further Reading
Books and field guides related to How does attention find the right context?. Use these as the next step if you want deeper reading beyond the article.
Hands-On Large Language Models
Provides intuitive explanations of attention and context.
Natural Language Processing with Transformers
Covers self-attention in practical NLP systems.
Deep Learning
Rating: 3.5/5 from 6 Google Books ratings
Provides the neural-network foundations behind modern architectures, including attention-era systems.
Transformers for Machine Learning
Explains queries, keys, values, and attention mechanisms.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.


Endnotes
-
Source: papers.neurips.cc
Title: 7181 attention is all you need
Link: https://papers.neurips.cc/paper/7181-attention-is-all-you-need.pdfSource snippet
NeurIPS PapersAttention is All you Needby A Vaswani · Cited by 246782 — An attention function can be described as mapping a query and a s...
-
Source: arxiv.org
Link: https://arxiv.org/abs/1706.03762Source snippet
[1706.03762] Attention Is All You Need12 Jun 2017 — We propose a new simple network architecture, the Transformer, based solely on attent...
-
Source: community.deeplearning.ai
Link: https://community.deeplearning.ai/t/attention-is-all-you-need/399044Source snippet
is all you need - GenAI with LLMs ResourcesJul 27, 2023 — Self-attention layers allow each position in the sequence to attend to all othe...
-
Source: medium.com
Link: https://medium.com/%40adnanmasood/attention-is-all-you-need-explained-like-youre-smart-and-busy-2a3d7436144fSource snippet
Attention Is All You Need, explained like you're smart and...Long-range dependencies are hard because information has to travel th...
-
Source: sh-tsang.medium.com
Link: https://sh-tsang.medium.com/review-attention-is-all-you-need-transformer-96c787ecdec1Source snippet
Review — Attention Is All You Need (Transformer)A self-attention layer connects all positions with a constant number of sequentiall...
-
Source: dlvr.rantai.dev
Link: https://dlvr.rantai.dev/docs/part-ii/chapter-9/Source snippet
Chapter 9This enables self-attention mechanisms to capture long-range dependencies much more effectively, without being constr...
-
Source: datacamp.com
Link: https://www.datacamp.com/blog/self-attentionSource snippet
Self-Attention Explained: The Mechanism Powering...2 Mar 2026 — Transformer models excel at capturing long-range dependencies th...
-
Source: eureka.patsnap.com
Title: how do transformers handle long range dependencies
Link: https://eureka.patsnap.com/article/how-do-transformers-handle-long-range-dependenciesSource snippet
PatSnap EurekaHow Do Transformers Handle Long-Range Dependencies?Jun 26, 2025 — Self-attention computes a representation of each word by...
-
Source: Wikipedia
Title: Attention Is All You Need
Link: https://en.wikipedia.org/wiki/Attention_Is_All_You_Need -
Source: medium.com
Link: https://medium.com/data-science-collective/transformers-the-game-changer-how-attention-is-all-you-need-architecture-changed-ai-forever-81a43344ce63Source snippet
nts)... Step 3.1: Create Query, Key, and Value (Q, K, V).Read more...
-
Source: arxiv.org
Title: arXiv Attention is not Explanation
Link: https://arxiv.org/abs/1902.10186Source snippet
Attention is not ExplanationFebruary 26, 2019...
Published: February 26, 2019
-
Source: kumarshivam-66534.medium.com
Link: https://kumarshivam-66534.medium.com/mastering-attention-mechanisms-how-transformers-understand-context-in-[generative-aiSource snippet
Attention Mechanisms: How Transformers...This addresses two major problems: Long-range dependencies: Connecting distant elements (e.g...
-
Source: medium.com
Link: https://medium.com/%40kdk199604/kdks-review-attention-is-all-you-need-what-makes-the-transformer-so-revolutionary-c91f135583b0Source snippet
, enabling the model to capture contextual relationships...Read more...
-
Source: medium.com
Link: https://medium.com/%40byron.wallace/thoughts-on-attention-is-not-not-explanation-b7799c4c3b24Source snippet
s (e.g., leave-one-out scores)? And, (2) do different...Read more...
-
Source: medium.com
Title: transformers explained why attention is truly all you need 2e3669242965
Link: https://medium.com/%40lmpo/transformers-explained-why-attention-is-truly-all-you-need-2e3669242965Source snippet
Transformers Explained: Why Attention Is Truly All You NeedIn 2017, “Attention Is All You Need” introduced the Transformer architecture t...
-
Source: medium.com
Link: https://medium.com/%40marvelous_catawba_otter_200/attention-is-all-you-need-f9fe38d6e2fcSource snippet
Attention Is All You Need | by Xupeng WangSelf-Attention Layer: This is the key mechanism that allows each word to focus on other words i...
-
Source: medium.com
Title: Is Attention Explanation?
Link: https://medium.com/data-science/is-attention-explanation-b609a7b0925cSource snippet
by Denis VorotyntsevThe paper assesses the claim that we can use attention weights as models' explanations.... Attention is not not Expl...
-
Source: medium.com
Link: https://medium.com/%40weidagang/coffee-time-papers-attention-is-all-you-need-3c7d6bc75eabSource snippet
Coffee Time Papers: Attention Is All You NeedSelf-Attention Mechanism: The model uses self-attention mechanisms to draw global dependenci...
-
Source: medium.com
Link: https://medium.com/%40yuvalpinter/attention-is-not-not-explanation-dbc25b534017Source snippet
Attention is not not ExplanationThis post is intended for an NLP practitioner audience, and assumes its readers know what attention modul...
-
Source: arxiv.org
Link: https://arxiv.org/html/1706.03762v7 -
Source: arxiv.org
Title: We challenge many of the assumptions underlying this work.Read more
Link: https://arxiv.org/abs/1908.04626Source snippet
[1908.04626] Attention is not not Explanationby S Wiegreffe · 2019 · Cited by 1715 — A recent paper claims that `Attention is not Explana...
-
Source: Wikipedia
Title: Attention ([machine learning]({{ ‘machine-learning/’ | relative_url }}))
Link: https://en.wikipedia.org/wiki/Attention_%28machine_learning%29Source snippet
Attention (machine learning)In machine learning, attention is a method that determines the importance of each component in a sequence...
-
Source: attention.com
Title: Our AI agents that learn from that data and automates busywork
Link: https://www.attention.com/Source snippet
AI agents that learn from your best sales...Attention records your sales touchpoints across meetings, emails, calls, CRMs an...
-
Source: huggingface.co
Title: attention is all you need
Link: https://huggingface.co/blog/Esmail-AGumaan/attention-is-all-you-needSource snippet
Transformers2 Jul 2024 — The Transformer architecture is based on the concept of attention, enabling it to capture long-range dependencie...
-
Source: pub.towardsai.net
Title: attention mechanism 5c0f9476d772
Link: https://pub.towardsai.net/attention-mechanism-5c0f9476d772Source snippet
Mechanism | by Dr Barak Or2 Feb 2024 — The attention mechanism operates on the principle of mapping a query alongside a series of key-val...
-
Source: aclanthology.org
Link: https://aclanthology.org/N19-1357/Source snippet
Attention is not Explanationby S Jain · 2019 · Cited by 2494 — Our findings show that standard attention modules do not provide meaningfu...
-
Source: aclanthology.org
Link: https://aclanthology.org/N19-1357.pdfSource snippet
ACL AnthologyAttention is not Explanationby S Jain · 2019 · Cited by 2461 — (i) Attention weights should correlate with feature importanc...
-
Source: aclanthology.org
Title: We challenge many of the assumptions underlying this work.Read more
Link: https://aclanthology.org/D19-1002/Source snippet
Attention is not not Explanationby S Wiegreffe · 2019 · Cited by 1696 — A recent paper claims that 'Attention is not Explanation' (Jain a...
-
Source: jaketae.github.io
Link: https://jaketae.github.io/study/transformer/Source snippet
Attention is All You Need20 Jan 2021 — Today, we are finally going to take a look at transformers, the mother of most, if not all current...
-
Source: github.com
Link: https://github.com/sarahwie/attentionSource snippet
Code for EMNLP 2019 paper "Attention is not...We've based our repository on the code provided by Sarthak Jain & Byron Wallace for their...
-
Source: kaggle.com
Link: https://www.kaggle.com/code/seki32/attention-is-all-you-need-part-iSource snippet
y sees 3 tokens at once. To see 100 tokens apart, you...Read more...
Additional References
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/336999161_Attention_is_not_not_ExplanationSource snippet
(PDF) Attention is not not ExplanationWe propose four alternative tests to determine when/whether attention can be used as explanation: a...
-
Source: merriam-webster.com
Link: https://www.merriam-webster.com/dictionary/attentionSource snippet
ATTENTION Definition & Meaning5 days ago — 1. a: the act or state of applying the mind to something Our attention was on the game. You s...
-
Source: reddit.com
Link: https://www.reddit.com/r/MachineLearning/comments/1003d7w/discussion_is_attention_an_explanation/Source snippet
[Discussion] is attention an explanation?: r/MachineLearningCan we use attention weights from causal models, as explanations or causal a...
-
Source: semanticscholar.org
Link: https://www.semanticscholar.org/paper/Attention-is-not-Explanation-Jain-Wallace/1e83c20def5c84efa6d4a0d80aa3159f55cb9c3fSource snippet
[PDF] Attention is not ExplanationThis paper disputes the claim that attention weights do not correlate with measures of feature importan...
-
Source: velog.io
Link: https://velog.io/%40chaewonkim0425/Why-Attention-was-all-we-neededSource snippet
[Paper review] Why Attention Was All We NeededLong-range dependencies: Self-attention directly connects any two positions in the sequence...
-
Source: pub.towardsai.net
Link: https://pub.towardsai.net/attention-is-all-you-need-a-deep-dive-into-the-revolutionary-transformer-architecture-52734fb355dcSource snippet
Deep Dive into the Revolutionary Transformer Architecture10 Apr 2025 — Captures Long-Range Dependencies: Unlike RNNs, which struggle with...
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/331396991_Attention_is_not_ExplanationSource snippet
materially affect the [prediction]({{ 'error-harms/' | relative_url }}), especially in deep, multi-layer...Read more...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/understanding-groundbreaking-attention-all-you-need-research-disansa-becncSource snippet
o output sequences) model relying entirely on self-attention...Read more...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/why-attention-all-you-need-deep-dive-transformer-model-padhy-cijwcSource snippet
rstand long-range relationships in text. Scalability:...Read more...
-
Source: mbrenndoerfer.com
Title: The Transformer: Attention Is All You Need
Link: https://mbrenndoerfer.com/writing/transformer-attention-is-all-you-needSource snippet
Interactive7 Jun 2025 — A comprehensive guide to the Transformer architecture, including self-attention mechanisms, multi-head attention...
Topic Tree