Within Parallel scale
Why faster training still hit a length limit
Parallel training made Transformers scalable, but self-attention still becomes costly as sequences grow longer.
On this page
- Why attention cost grows with sequence length
- Memory pressure in long input Transformer training
- How newer parallelism and efficient attention try to help
Page outline Jump by section
Introduction
Parallel training was the breakthrough that made Transformers practical to scale, but it did not eliminate every computational bottleneck. The same self-attention mechanism that allows a Transformer to process an entire sequence simultaneously also creates a growing cost as sequences become longer. A model can analyse thousands of words, lines of code, or conversation turns in parallel, yet the amount of work required by attention rises much faster than the length of the input. This is why extending context windows from a few thousand tokens to hundreds of thousands or even millions remains one of the most challenging engineering problems in modern AI. [arXiv]arxiv.orgarXiv[1706.03762] Attention Is All You NeedJune 12, 2017 — Jun 12, 2017 — We propose a new simple network architecture, the Transformer…
 The result is a central trade-off in Transformer design: the architecture scales exceptionally well across hardware, but long contexts place increasing pressure on computation, memory, and training budgets. Understanding this limitation helps explain why so much recent AI research focuses on efficient attention methods rather than simply making models larger. [hazyresearch.stanford.edu]hazyresearch.stanford.edu2023 01 12 flashattention long sequencesFast Transformer Training with Long SequencesJan 13, 2023 — FlashAttention is a new algorithm to speed up attention and reduce its memory…
The result is a central trade-off in Transformer design: the architecture scales exceptionally well across hardware, but long contexts place increasing pressure on computation, memory, and training budgets. Understanding this limitation helps explain why so much recent AI research focuses on efficient attention methods rather than simply making models larger. [hazyresearch.stanford.edu]hazyresearch.stanford.edu2023 01 12 flashattention long sequencesFast Transformer Training with Long SequencesJan 13, 2023 — FlashAttention is a new algorithm to speed up attention and reduce its memory…
Why attention cost grows with sequence length
The core issue comes from how self-attention works. Each token compares itself with every other token in the sequence to determine which pieces of information matter most. If a sequence contains 100 tokens, there are roughly 10,000 pairwise relationships. If the sequence grows to 1,000 tokens, the number of potential interactions rises to about one million. The growth is quadratic: doubling the sequence length roughly quadruples the amount of attention computation. [Shreyansh Singh+2aiplanet.com]shreyansh26.github.ioShreyansh SinghPaper Summary #7 - Efficient Transformers: A Survey10 Oct 2022 — This is a survey paper on the various memory-efficiency…
This behaviour differs from the scaling story that made Transformers attractive in the first place. Training can be distributed across many GPUs because attention calculations are highly parallelisable matrix operations. However, parallel hardware does not change the underlying mathematics. Longer sequences still create many more token-to-token comparisons that must be computed somewhere. [arXiv]arxiv.orgarXiv[1706.03762] Attention Is All You NeedJune 12, 2017 — Jun 12, 2017 — We propose a new simple network architecture, the Transformer…
A useful way to think about the problem is that attention treats a document as a dense network of relationships. Every new token potentially connects to all previous tokens. As context windows expand from 4,000 tokens to 32,000, 128,000, or beyond, the number of possible relationships explodes much faster than the visible increase in text length. [Shreyansh Singh]shreyansh26.github.ioShreyansh SinghPaper Summary #7 - Efficient Transformers: A Survey10 Oct 2022 — This is a survey paper on the various memory-efficiency…
Why longer prompts become disproportionately expensive
Many readers assume that processing a prompt twice as long should require roughly twice as much work. With standard self-attention, that intuition is wrong.
For attention-heavy workloads:
- Doubling sequence length can roughly quadruple attention operations.
- Four times the sequence length can require around sixteen times the attention work.
- Memory requirements often grow alongside computation because attention scores and intermediate states must be stored during training. [arXiv+2Shreyansh Singh]arxiv.orgFull Attention Transformer with Sparse Computation Costby H Ren · 2021 · Cited by 112 — PDF of the paper titled ・ the key limitation…
This scaling behaviour explains why extending context windows is not merely a matter of buying proportionally more hardware. The costs can accelerate much faster than the apparent increase in usable context. [Michael Brenndoerfer]mbrenndoerfer.comquadratic attention bottleneck transformers long sequencesMichael BrenndoerferQuadratic Attention Bottleneck: Why Transformers Struggle…19 Jun 2025 — Understand why self-attention has O(n²) co…

Memory pressure in long-input Transformer training
Computation is only part of the challenge. Training large Transformer models also requires storing activations, gradients, and attention-related intermediate values. As sequence length grows, memory consumption can become the limiting factor before raw processing speed does. [arXiv]arxiv.orgFast and Memory-Efficient Exact Attention with IO-Awarenessby T Dao · 2022 · Cited by 5165 — We propose FlashAttention, an IO-aware…
This memory pressure creates several practical constraints:
- Smaller batch sizes may be required to fit long sequences into GPU memory.
- Training throughput often falls because hardware spends more time moving data.
- Additional GPUs may be needed simply to hold model state and attention information rather than perform new computation. [hazyresearch.stanford.edu]hazyresearch.stanford.edu2023 01 12 flashattention long sequencesFast Transformer Training with Long SequencesJan 13, 2023 — FlashAttention is a new algorithm to speed up attention and reduce its memory…
Researchers working on long-context language models frequently report that memory becomes a dominant engineering concern. Even when sufficient computing power exists, storing the information required by attention can prevent straightforward scaling to longer documents. [arXiv]arxiv.orgDISTFLASHATTN: Distributed Memory-efficient Attention for Long-context LLMs TrainingOctober 5, 2023…
The distinction matters because parallel training solved a different problem. Transformers removed the sequential dependency chain that limited recurrent neural networks. They did not remove the need to represent interactions across an entire context window. As contexts become larger, that interaction structure itself becomes expensive. [arXiv]arxiv.orgarXiv[1706.03762] Attention Is All You NeedJune 12, 2017 — Jun 12, 2017 — We propose a new simple network architecture, the Transformer…
How newer parallelism and efficient attention try to help
The industry’s response has largely been to make attention more efficient rather than abandon the Transformer entirely.
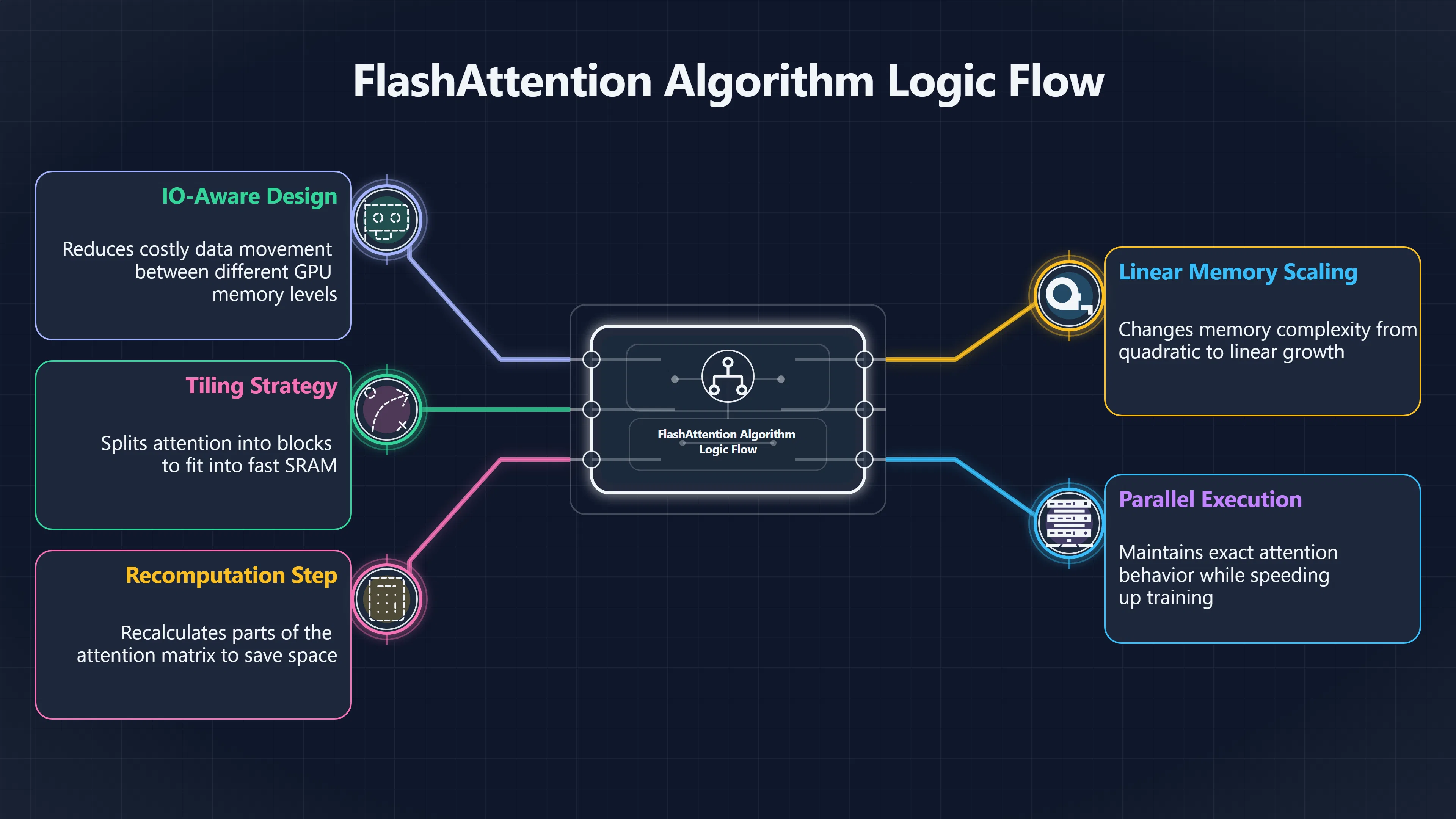
One influential example is FlashAttention, which reorganises attention computations to reduce costly memory transfers between different levels of GPU memory. The key insight is that modern accelerators often spend significant time moving data rather than performing arithmetic. By restructuring the computation, FlashAttention can reduce memory usage and accelerate training while preserving exact attention behaviour. [arXiv+2OpenReview]arxiv.orgFast and Memory-Efficient Exact Attention with IO-Awarenessby T Dao · 2022 · Cited by 5165 — We propose FlashAttention, an IO-aware…
Researchers have also explored distributed attention systems that spread long-context processing across multiple devices. Methods such as DistFlashAttn aim to support sequence lengths far beyond what a single GPU could comfortably handle. [arXiv]arxiv.orgDISTFLASHATTN: Distributed Memory-efficient Attention for Long-context LLMs TrainingOctober 5, 2023…
Another major research direction is reducing the number of token interactions that must be calculated at all. Common approaches include:
- Sparse attention, where tokens attend only to selected parts of the sequence.
- Linear attention variants, which replace full pairwise comparison with more efficient approximations.
- Memory and retrieval mechanisms, which try to access only relevant information from very long histories. [Medium+2Medium]medium.com69. Making Transformers Efficient for Long Sequences:…By attending to a subset of tokens, attention cost drops from quadratic to…
These approaches attempt to move beyond the quadratic scaling of standard attention, although they often introduce trade-offs involving accuracy, implementation complexity, or the ability to capture long-range relationships. [arXiv]arxiv.orgFull Attention Transformer with Sparse Computation Costby H Ren · 2021 · Cited by 112 — PDF of the paper titled ・ the key limitation…

The continuing trade-off behind long-context AI
Long-context models can read books, analyse large codebases, process lengthy conversations, and combine information spread across vast documents. Yet the cost of doing so remains one of the defining limitations of Transformer-based AI.
This creates a subtle but important lesson about the architecture’s success. Transformers became dominant because they aligned well with parallel hardware and large-scale training. However, the same attention mechanism that enabled that success still contains a scaling tension: every increase in context length asks the model to reason over a rapidly growing number of relationships. [arXiv+2hazyresearch.stanford.edu]arxiv.orgarXiv[1706.03762] Attention Is All You NeedJune 12, 2017 — Jun 12, 2017 — We propose a new simple network architecture, the Transformer…
Modern advances have made long contexts increasingly practical, but they mostly reduce, redistribute, or approximate the underlying cost rather than eliminating it entirely. As a result, attention efficiency remains one of the most active areas of research in the effort to build AI systems that can reliably work with ever larger amounts of information. [arXiv+2Machine Learning At Scale]arxiv.orgFast and Memory-Efficient Exact Attention with IO-Awarenessby T Dao · 2022 · Cited by 5165 — We propose FlashAttention, an IO-aware…
Amazon book picks
Further Reading
Books and field guides related to Why faster training still hit a length limit. Use these as the next step if you want deeper reading beyond the article.
Hands-On Large Language Models
Covers context windows, attention limits, and LLM scaling.
Build a Large Language Model (From Scratch)
Explains attention computation and long-context constraints.
Natural Language Processing with Transformers
Provides practical context on transformer performance trade-offs.
Transformers for Machine Learning
Discusses attention complexity and efficiency improvements.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: arxiv.org
Link: https://arxiv.org/abs/1706.03762Source snippet
arXiv[1706.03762] Attention Is All You NeedJune 12, 2017 — Jun 12, 2017 — We propose a new simple network architecture, the Transformer...
Published: June 12, 2017
-
Source: arxiv.org
Link: https://arxiv.org/abs/2107.05768Source snippet
Full Attention Transformer with Sparse Computation Costby H Ren · 2021 · Cited by 112 — PDF of the paper titled ・ the key limitation...
-
Source: hazyresearch.stanford.edu
Title: 2023 01 12 flashattention long sequences
Link: https://hazyresearch.stanford.edu/blog/2023-01-12-flashattention-long-sequencesSource snippet
Fast Transformer Training with Long SequencesJan 13, 2023 — FlashAttention is a new algorithm to speed up attention and reduce its memory...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2205.14135Source snippet
Fast and Memory-Efficient Exact Attention with IO-Awarenessby T Dao · 2022 · Cited by 5165 — We propose FlashAttention, an IO-aware...
-
Source: aiplanet.com
Link: https://aiplanet.com/learn/llm-bootcamp/module-4/2343/transformers-attention-is-all-you-needSource snippet
Transformers- Attention is all you needComputational Complexity: The traditional Attention mechanism involves pairwise comparisons betwee...
-
Source: arxiv.org
Link: https://arxiv.org/html/2310.03294v2Source snippet
DistFlashAttn: Distributed Memory-efficient Attention for...Mar 31, 2024 — FlashAttention (Dao, 2023) effectively reduces the quadratic...
-
Source: openreview.net
Link: https://openreview.net/forum?id=H4DqfPSibmxSource snippet
Fast and Memory-Efficient Exact Attention with IO-Awarenessby T Dao · 2022 · Cited by 5165 — We propose FlashAttention, an IO-aware exact...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2310.03294Source snippet
DISTFLASHATTN: Distributed Memory-efficient Attention for Long-context LLMs TrainingOctober 5, 2023...
Published: October 5, 2023
-
Source: medium.com
Link: https://medium.com/%40kiranvutukuri/69-sparse-attention-making-transformers-efficient-for-long-sequences-859aa03b03f6Source snippet
69. Making Transformers Efficient for Long Sequences:...By attending to a subset of tokens, attention cost drops from quadratic to...
-
Source: medium.com
Link: https://medium.com/%40dr.teck/efficient-alternatives-to-transformer-self-attention-397851f324ab -
Source: arxiv.org
Link: https://arxiv.org/abs/2502.01659Source snippet
Increasing Transformer Context Length with Sparse Graph...by N Tomczak · 2025 · Cited by 2 — In this work, we address this issue by prop...
-
Source: arxiv.org
Link: https://arxiv.org/html/2506.01963v1Source snippet
A Non-Attention LLM for Ultra-Long Context Horizons9 May 2025 — We present a novel non-attention-based architecture for large language mo...
Published: May 2025
-
Source: arxiv.org
Link: https://arxiv.org/abs/2209.04881Source snippet
On The Computational Complexity of Self-Attentionby FD Keles · 2022 · Cited by 379 — We prove that the time complexity of self-attention...
-
Source: medium.com
Link: https://medium.com/%40mridulrao674385/attention-mechanism-complexity-analysis-7314063459b1Source snippet
Attention Mechanism Complexity Analysis | by Mridul RaoComplexity analysis is about estimating how the time required to execute an algori...
-
Source: [machine-learning]({{ ‘machine-learning/’ | relative_url }})-made-simple.medium.com
Link: https://machine-learning-made-simple.medium.com/transformers-vs-mamba-vs-linear-attention-who-wins-long-context-f1dc8ceb5edeSource snippet
vs Mamba vs Linear Attention: Who Wins Long...Transformer inference today faces a fundamental bottleneck — the quadratic cost of attention...
-
Source: medium.com
Link: https://medium.com/data-science-collective/transformers-the-game-changer-how-attention-is-all-you-need-architecture-changed-ai-forever-81a43344ce63Source snippet
N, you compute N x N attention scores. For GPT-3 with 2048...Read more...
-
Source: medium.com
Link: https://medium.com/%40sailakkshmiallada/the-evolution-of-flash-attention-revolutionizing-transformer-efficiency-8a039918d507Source snippet
ion, enabling longer context windows and faster training.Read more...
-
Source: sulbhajain.medium.com
Link: https://sulbhajain.medium.com/flash-attention-fast-and-memory-efficient-exact-attention-with-io-awareness-paper-review-79639127c5deSource snippet
and Memory-Efficient Exact Attention with IO-Awareness...26 May 2025 — Solution: FlashAttention is an IO-aware exact attention algorithm...
Published: May 2025
-
Source: medium.com
Title: The Quadratic Burden
Link: https://medium.com/%40rajnish_khatri/the-quadratic-burden-45759ec6bd21Source snippet
No recurrence. No convolution. Only attention — each token looking at every other token, weighing, selecting, composing...Read more...
-
Source: ahmdtaha.medium.com
Link: https://ahmdtaha.medium.com/flashattention-fast-and-memory-efficient-exact-attention-with-io-awareness-2a0aec52ed3dSource snippet
medium.comFlashAttention: Fast and Memory-Efficient Exact Attention with...This paper [1] proposes an IO-aware algorithm that computes e...
-
Source: medium.com
Link: https://medium.com/%40kdk199604/kdks-review-attention-is-all-you-need-what-makes-the-transformer-so-revolutionary-c91f135583b0Source snippet
Attention is All You Need: What makes the transformer so...In the Transformer model, the attention layer focuses on the input sequence i...
-
Source: openreview.net
Link: https://openreview.net/forum?id=pUEDkZyPDl&referrer=%5Bthe+profile+of+Dacheng+Li%5D%28%2Fprofile%3Fid%3D~Dacheng_Li1%29Source snippet
DISTFLASHATTN: Distributed Memory-efficient Attention for...Aug 25, 2024 — Abstract: FlashAttention effectively reduces the quadratic pea...
-
Source: openreview.net
Link: https://openreview.net/pdf?id=Eh0Od2BJIM -
Source: shreyansh26.github.io
Link: https://shreyansh26.github.io/post/2022-10-10_efficient_transformers_survey/Source snippet
Shreyansh SinghPaper Summary #7 - Efficient Transformers: A Survey10 Oct 2022 — This is a survey paper on the various memory-efficiency...
-
Source: mbrenndoerfer.com
Title: quadratic attention bottleneck transformers long sequences
Link: https://mbrenndoerfer.com/writing/quadratic-attention-bottleneck-transformers-long-sequencesSource snippet
Michael BrenndoerferQuadratic Attention Bottleneck: Why Transformers Struggle...19 Jun 2025 — Understand why self-attention has O(n²) co...
-
Source: machinelearningatscale.substack.com
Title: Machine Learning At Scale64
Link: https://machinelearningatscale.substack.com/p/64-challenges-and-solutions-of-longSource snippet
substack.com64. Breaking the Attention Barrier: A Deep Dive into Scaling...Flash Attention is an algorithm designed to address the memor...
-
Source: attention-survey.github.io
Link: https://attention-survey.github.io/files/Attention_Survey.pdfSource snippet
ntion heads, and d = 128 head dimensionality in a 48-layer Transformer with MHA, the KV.Read more...
-
Source: mbrenndoerfer.com
Title: attention complexity quadratic scaling memory efficient transformers
Link: https://mbrenndoerfer.com/writing/attention-complexity-quadratic-scaling-memory-efficient-transformersSource snippet
Attention Complexity: Quadratic Scaling, Memory Limits &...26 May 2025 — For autoregressive generation where the full context is reproce...
Published: May 2025
-
Source: mbrenndoerfer.com
Title: flashattention io aware exact attention long context language models
Link: https://mbrenndoerfer.com/writing/flashattention-io-aware-exact-attention-long-context-language-modelsSource snippet
FlashAttention: IO-Aware Exact Attention for Long-Context...Jul 11, 2025 — This approach reduced memory complexity from quadratic to lin...
-
Source: mbrenndoerfer.com
Title: The Transformer: Attention Is All You Need
Link: https://mbrenndoerfer.com/writing/transformer-attention-is-all-you-needSource snippet
InteractiveJun 7, 2025 — A comprehensive guide to the Transformer architecture, including self-attention mechanisms, [multi-head]({{ 'multi-heads/' | relative_url }}) attention...
-
Source: github.com
Link: https://github.com/dao-ailab/flash-attentionSource snippet
s memory quadratic in sequence length, whereas FlashAttention has memory linear...
Additional References
-
Source: aussieai.com
Link: https://www.aussieai.com/research/attentionSource snippet
Attention OptimizationMemory-efficient attention algorithms are an inference optimization method that improves the QKV matrix computation...
-
Source: bentoml.com
Link: https://bentoml.com/llm/kernel-optimization/flashattentionSource snippet
FlashAttention | LLM Inference HandbookFlashAttention is a fast, memory-efficient attention algorithm for Transformers that accelerates L...
-
Source: nvidia.com
Link: https://www.nvidia.com/en-us/on-demand/session/gtc24-s62546/Source snippet
FlashAttention: Fast and Memory-Efficient Exact Attention...We propose FlashAttention, an IO-aware exact attention algorithm that uses t...
-
Source: reddit.com
Link: https://www.reddit.com/r/LocalLLaMA/comments/17rme8v/regarding_long_context_and_quadratic_attention/Source snippet
Regarding long context and quadratic attentionQuadratic scaling of attention is a problem, but not something any of the currently trained...
-
Source: stackoverflow.com
Link: https://stackoverflow.com/questions/65703260/computational-complexity-of-self-attention-in-the-transformer-modelSource snippet
Computational Complexity of Self-Attention in the...I recently went through the Transformer paper from Google Research describing how se...
-
Source: velog.io
Link: https://velog.io/%40chaewonkim0425/Why-Attention-was-all-we-neededSource snippet
[Paper review] Why Attention Was All We NeededThe self-attention mechanism compares every token with every other token, causing quadratic...
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/398527678_Efficient_Attention_and_Beyond_A_Survey_of_Advances_in_Optimizing_Transformer_InferenceSource snippet
A Survey of Advances in Optimizing Transformer Inference12 Dec 2025 — Efficient Attention and Beyond: A Survey of Advances in Optimizing...
-
Source: apxml.com
Link: https://apxml.com/courses/foundations-transformers-architecture/chapter-6-advanced-architectural-variants-analysis/self-attention-complexity -
Source: wandb.ai
Link: https://wandb.ai/wandb_fc/tips/reports/The-Problem-with-Quadratic-Attention-in-Transformer-Architectures–Vmlldzo3MDE0MzczSource snippet
The Problem with Quadratic Attention in Transformer...Mar 4, 2024 — This report provides a brief overview of the problem with vanilla se...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=eMlx5fFNoYcSource snippet
"Kurt, W. (2024, August 12). Say what you mean: A response to 'Let Me Speak Freely'. Count Bayesie. [https://www.countbayesie.com/blog/2024..."](https://www.countbayesie.com/blog/2024...")...
Topic Tree