Within Language Models
How one token becomes a whole answer
A chatbot answer is assembled step by step as each new token becomes part of the context for the next prediction.
On this page
- The prompt to token prediction loop
- Why answers are generated rather than retrieved whole
- How decoding choices affect fluency and variation
Page outline Jump by section
Introduction
When a chatbot produces a reply, it is not usually retrieving a finished paragraph from storage and displaying it all at once. Instead, it generates text incrementally. The model reads the prompt, predicts a likely next token, adds that token to the growing response, then repeats the process. This cycle continues until it reaches a stopping point, producing what appears to be a complete answer. Modern large language models are therefore often described as autoregressive systems: each newly generated token becomes part of the context used to predict the next one. [Hugging Face+2Hugging Face]huggingface.coHugging FaceGeneration with LLMsSince they predict one token at a time, you need to do something more elaborate to generate new sentences…
 Understanding this generation loop is important because many characteristics of AI chatbots—including fluency, variation, creativity, occasional mistakes, and response speed—emerge directly from the way text is assembled one token at a time. [Hugging Face]huggingface.coHugging FaceGeneration with LLMsSince they predict one token at a time, you need to do something more elaborate to generate new sentences…
Understanding this generation loop is important because many characteristics of AI chatbots—including fluency, variation, creativity, occasional mistakes, and response speed—emerge directly from the way text is assembled one token at a time. [Hugging Face]huggingface.coHugging FaceGeneration with LLMsSince they predict one token at a time, you need to do something more elaborate to generate new sentences…
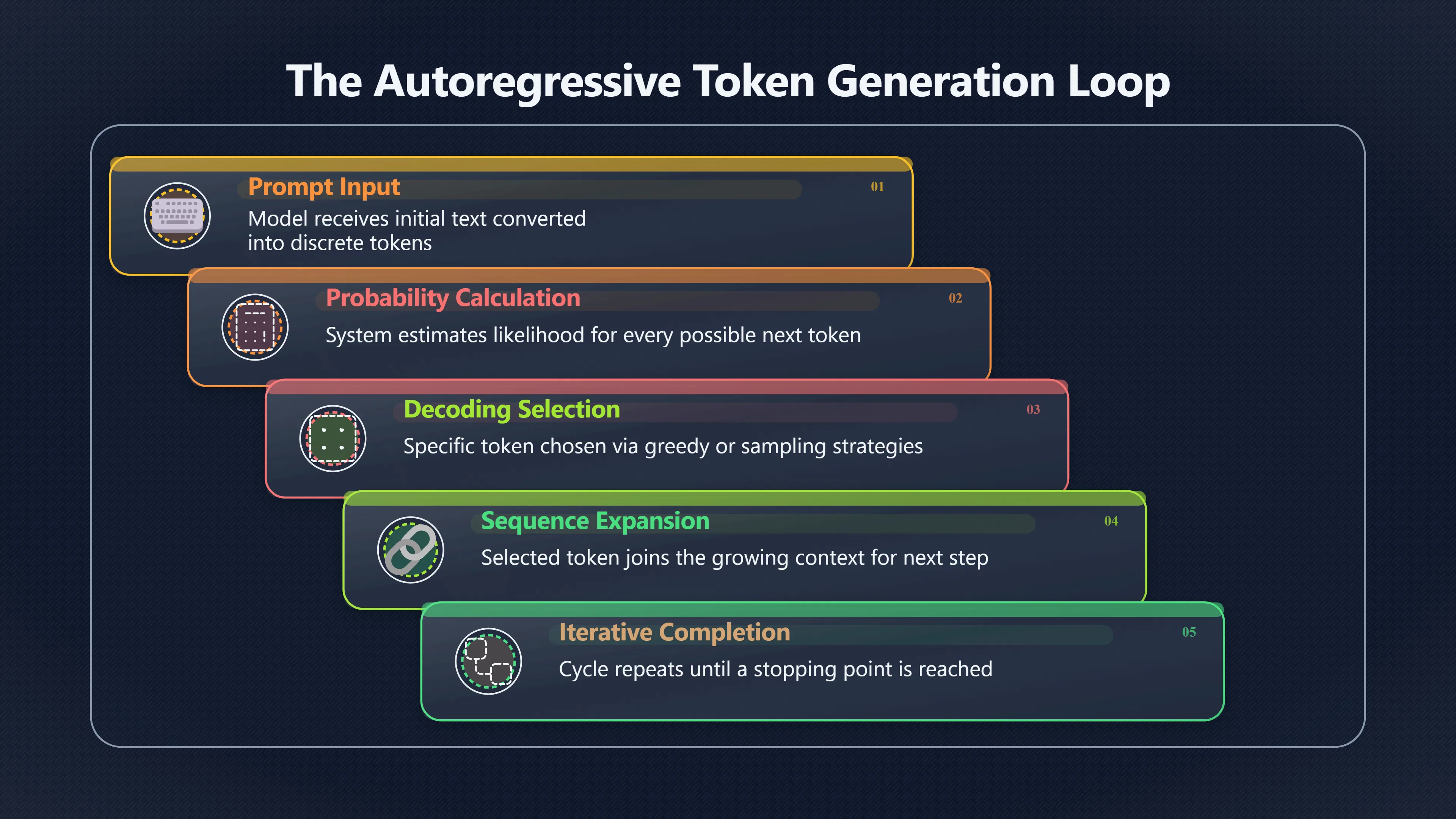
The prompt-to-token prediction loop
At the start of generation, the model receives a prompt that has already been converted into tokens. It then calculates a probability distribution over every token in its vocabulary, estimating how likely each candidate is to come next given the current context. [ApX Machine Learning]apxml.comAt each step, it calculates the probability of every possible next token. Parameters…Read more…
The generation loop can be summarised as:
- Read the prompt and previous tokens.
- Calculate probabilities for possible next tokens.
- Select one token using a decoding strategy.
- Append the selected token to the sequence.
- Repeat the process using the expanded sequence as context.
Because the model continually feeds its own output back into the prediction process, a long answer is built from thousands of small decisions. A sentence, paragraph, or page is not planned as a fully formed object and then revealed. It emerges through repeated next-token predictions. [Hugging Face+2Hugging Face]huggingface.coHugging FaceGeneration with LLMsSince they predict one token at a time, you need to do something more elaborate to generate new sentences…
A simple example helps illustrate the mechanism. Suppose the current text is:
The capital of France is
The model may assign very high probability to the token representing “Paris”. Once “Paris” is chosen, the context changes to:
The capital of France is Paris
The next prediction is no longer about country names. It may now favour punctuation, an explanatory phrase, or the start of another sentence. Each prediction depends on the entire sequence generated so far. [arXiv]arxiv.orgOpen source on arxiv.org.
Why answers are generated rather than retrieved whole
A common misconception is that a chatbot searches its training data for a matching answer and then copies it. In reality, text generation systems are designed to produce continuations token by token rather than retrieve complete passages. Decoder-style transformer models generate text by predicting one token at a time based on previous tokens. [Hugging Face]huggingface.coHugging FaceTransformer ArchitecturesThese models are best suited for tasks involving text generation. Decoder models like GPT are design…
This distinction explains several familiar behaviours.
First, the same prompt can produce slightly different answers on different runs. If the system were retrieving a stored response, identical outputs would be expected much more often. Instead, generation involves selecting among multiple plausible next tokens. [Hugging Face]huggingface.coHugging FaceGeneration strategiesThis guide will help you understand the different decoding strategies available in Transformers and how…
Second, models can create combinations of ideas they have never seen in exactly the same form before. The response is assembled dynamically from learned patterns rather than copied as a fixed document. [Hugging Face]huggingface.coHugging FaceGeneration with LLMsSince they predict one token at a time, you need to do something more elaborate to generate new sentences…
Third, mistakes can arise even when the generated text sounds convincing. Because the model’s objective is to continue text plausibly, not to verify every statement against an external source, a sequence of locally reasonable token choices can still lead to factual errors. Researchers studying hallucinations note that these systems often generate plausible guesses when uncertainty is high. [OpenAI CDN+2arXiv]cdn.openai.comwhy language models hallucinateOpenAI CDNWhy Language Models Hallucinateby AT Kalai · 2025 · Cited by 255 — Abstract. Like students facing hard exam questions, large la…

How decoding choices affect fluency and variation
After the model calculates probabilities for possible next tokens, it must decide which token to output. That decision process is called decoding. Different decoding strategies can produce noticeably different responses even when the underlying model remains unchanged. [Hugging Face+2Hugging Face]huggingface.coHugging FaceGeneration strategiesThis guide will help you understand the different decoding strategies available in Transformers and how…
One straightforward approach is greedy decoding, which always selects the highest-probability token. This often produces predictable and consistent outputs, but it can also make text repetitive or less creative. [Hugging Face]huggingface.coHugging FaceText generationThe default decoding strategy in generate is greedy search, which selects the next most likely token, unless…
Many chatbot systems instead use sampling methods that introduce controlled randomness. Common controls include:
- Temperature: Adjusts how strongly the model favours high-probability tokens. Lower values make outputs more deterministic, while higher values increase variation. [OpenAI Developer Community+2machinelearningplus]community.openai.comtemperature top p and top k for chatbot responses· Lower top-p values reduce diversity and focus on more probable tokens. · Lower top…Read more…
- Top-p (nucleus sampling): Restricts selection to the smallest group of tokens whose combined probability exceeds a chosen threshold, then samples from that group. [OpenAI Developer Community+2OpenAI Developer Community]community.openai.comOpen AI Developer Community A better explanation of "Top P"?OpenAI Developer CommunityA better explanation of "Top P"? - Prompting12 May 2021 — In Top-p sampling chooses from the smallest possible…
- Other sampling controls: Systems may apply additional constraints to reduce repetition, encourage diversity, or control stopping behaviour. [Hugging Face]huggingface.coHugging FaceGeneration · Hugging FaceTo learn more about decoding strategies refer to the text generation strategies guide. A large numbe…
These choices influence whether a chatbot sounds cautious, creative, repetitive, or surprising. The underlying prediction engine may be identical, but different decoding settings can make the resulting conversation feel very different. [Hugging Face+2machinelearningplus]huggingface.coHugging FaceGeneration strategiesThis guide will help you understand the different decoding strategies available in Transformers and how…
Why generation sometimes feels instantaneous
Users often experience chatbot responses as if they were created all at once. In reality, the model repeatedly performs the generation loop, often many hundreds or thousands of times during a single answer. The apparent smoothness comes from modern hardware and optimisation techniques that make each prediction extremely fast. [Hugging Face]huggingface.coHugging FaceOptimizing inferenceOn top of the memory requirements, inference is slow because LLMs are called repeatedly to generate the n…
The token-by-token approach also explains why longer responses take longer to produce. Every newly generated token requires another prediction step. As generation continues, the sequence grows, and the model must repeatedly process an expanding context. Researchers and engineers devote substantial effort to making this iterative process more efficient because text generation fundamentally depends on repeated next-token prediction. [Hugging Face]huggingface.coHugging FaceOptimizing inferenceOn top of the memory requirements, inference is slow because LLMs are called repeatedly to generate the n…
From one token to a complete answer
The most important insight is that a chatbot’s reply is not created in a single act. It emerges through a chain of predictions. Each token slightly reshapes the context, influencing every token that follows. A greeting, explanation, code example, or essay is therefore the accumulated result of many sequential decisions rather than a retrieved block of text. [Hugging Face+2Hugging Face]huggingface.coHugging FaceGeneration with LLMsSince they predict one token at a time, you need to do something more elaborate to generate new sentences…
This generation loop may appear simple, but it is the mechanism that turns next-token prediction into conversations, articles, translations, summaries, and many other language tasks. The whole answer exists only because one token became the context for the next, over and over again. [Medium+2Hugging Face]medium.comNext-Token Prediction Explained: How LLMs Generate TextNext-token prediction means the model looks at a sequence of tokens and esti…

Amazon book picks
Further Reading
Books and field guides related to How one token becomes a whole answer. Use these as the next step if you want deeper reading beyond the article.
Build a Large Language Model (From Scratch)
Covers generation loops and transformer mechanics.
Natural Language Processing with Transformers
Provides detailed coverage of autoregressive generation.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.



Endnotes
-
Source: arxiv.org
Link: https://arxiv.org/abs/2505.11183 -
Source: medium.com
Link: https://medium.com/%40QuarkAndCode/next-token-prediction-explained-how-llms-generate-text-2851c5f71575Source snippet
Next-Token Prediction Explained: How LLMs Generate TextNext-token prediction means the model looks at a sequence of tokens and esti...
-
Source: cdn.openai.com
Title: why language models hallucinate
Link: https://cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdfSource snippet
OpenAI CDNWhy Language Models Hallucinateby AT Kalai · 2025 · Cited by 255 — Abstract. Like students facing hard exam questions, large la...
-
Source: arxiv.org
Title: arXiv Why Language Models Hallucinate
Link: https://arxiv.org/abs/2509.04664 -
Source: OpenAI
Title: why language models hallucinate
Link: https://openai.com/index/why-language-models-hallucinate/Source snippet
comWhy language models hallucinateSep 5, 2025 — OpenAI's new research explains why language models hallucinate. The findings show how imp...
-
Source: community.openai.com
Title: temperature top p and top k for chatbot responses
Link: https://community.openai.com/t/temperature-top-p-and-top-k-for-chatbot-responses/295542Source snippet
· Lower top-p values reduce diversity and focus on more probable tokens. · Lower top...Read more...
-
Source: machinelearningplus.com
Link: https://machinelearningplus.com/gen-ai/llm-temperature-top-p-top-k-explained/Source snippet
Temperature, top-p, top-k — these control how your model picks the next token. Set them wrong, and your...Read more...
-
Source: community.openai.com
Title: Open AI Developer Community A better explanation of “Top P”?
Link: https://community.openai.com/t/a-better-explanation-of-top-p/2426Source snippet
OpenAI Developer CommunityA better explanation of "Top P"? - Prompting12 May 2021 — In Top-p sampling chooses from the smallest possible...
Published: May 2021
-
Source: community.openai.com
Title: Open AI Developer Community Mastering Temperature and Top_p in Chat GPT API
Link: https://community.openai.com/t/cheat-sheet-mastering-temperature-and-top-p-in-chatgpt-api/172683Source snippet
OpenAI Developer CommunityMastering Temperature and Top_p in ChatGPT API - APIApr 22, 2023 — For example, if top_p is set to 0.1, GPT-3 w...
-
Source: OpenAI
Link: https://openai.com/Source snippet
comOpenAI | OpenAIWe believe our research will eventually lead to artificial general intelligence, a system that can solve human-level pr...
-
Source: OpenAI
Link: https://openai.com/[businessSource snippet
comHugging FaceConnect to the Hugging Face Hub in ChatGPT to explore models, datasets, and metadata and inspect options without manual br...
-
Source: arxiv.org
Link: https://arxiv.org/pdf/2509.04664Source snippet
Why Language Models Hallucinateby AT Kalai · 2025 · Cited by 255 — Despite significant progress, hallucinations continue to plague the fi...
-
Source: arxiv.org
Link: https://arxiv.org/html/2507.05362v2Source snippet
On the Bias of Next-Token Predictors Toward...1 Nov 2025 — We leverage the controlled nature of our problem setting to define a random g...
-
Source: aviralrma.medium.com
Title: understanding llm parameters c2db4b07f0ee
Link: https://aviralrma.medium.com/understanding-llm-parameters-c2db4b07f0eeSource snippet
temperature, top_p, top_k, logit_bias in LLM...The top_p controls the model output by augmenting the vocabulary size as only those token...
-
Source: medium.com
Link: https://medium.com/%40kavierim/transformers-unleashed-part-6-generating-text-with-language-models-39840662d509Source snippet
Dive deep into manual generation using model.generate. Explore different decoding...Read more...
-
Source: medium.com
Link: https://medium.com/%40AIchats/why-language-models-hallucinate-1292f8184981Source snippet
e next token given a context. That is...
-
Source: huggingface.co
Link: https://huggingface.co/docs/transformers/v4.48.0/llm_tutorialSource snippet
Hugging FaceGeneration with LLMsSince they predict one token at a time, you need to do something more elaborate to generate new sentences...
-
Source: huggingface.co
Link: https://huggingface.co/docs/transformers/llm_tutorialSource snippet
Text generationText generation is the most popular application for large language models... Decoder-only models returns the initial prom...
-
Source: huggingface.co
Link: https://huggingface.co/learn/llm-course/en/chapter1/6Source snippet
Hugging FaceTransformer ArchitecturesThese models are best suited for tasks involving text generation. Decoder models like GPT are design...
-
Source: huggingface.co
Link: https://huggingface.co/docs/transformers/generation_strategiesSource snippet
Hugging FaceGeneration strategiesThis guide will help you understand the different decoding strategies available in Transformers and how...
-
Source: apxml.com
Link: https://apxml.com/courses/prompt-engineering-llm-application-development/chapter-1-foundations-prompt-engineering/llm-temperature-parametersSource snippet
At each step, it calculates the probability of every possible next token. Parameters...Read more...
-
Source: huggingface.co
Link: https://huggingface.co/docs/transformers/v4.49.0/generation_strategiesSource snippet
Text generation strategiesThe process of selecting output tokens to generate text is known as decoding, and you can customize the decodin...
-
Source: huggingface.co
Link: https://huggingface.co/docs/transformers/en/generation_strategiesSource snippet
Generation strategiesThis guide will help you understand the different decoding strategies available in Transformers and how and when to...
-
Source: huggingface.co
Link: https://huggingface.co/docs/transformers/en/llm_tutorialSource snippet
Hugging FaceText generationThe default decoding strategy in generate is greedy search, which selects the next most likely token, unless...
-
Source: huggingface.co
Link: https://huggingface.co/docs/transformers/main_classes/text_generationSource snippet
Hugging FaceGeneration · Hugging FaceTo learn more about decoding strategies refer to the text generation strategies guide. A large numbe...
-
Source: huggingface.co
Link: https://huggingface.co/docs/transformers/v4.53.2/llm_optimsSource snippet
Hugging FaceOptimizing inferenceOn top of the memory requirements, [inference]({{ 'inference-test/' | relative_url }}) is slow because LLMs are called repeatedly to generate the n...
-
Source: huggingface.co
Link: https://huggingface.co/papers/2604.07023Source snippet
Enabling Autoregressive Models Multi-Token GenerationApr 7, 2026 — Autoregressive (AR) language models generate text one token at a time...
-
Source: huggingface.co
Link: https://huggingface.co/Source snippet
The platform where the machine learning community collaborates on models, datasets, and applications. Explore AI Apps...
-
Source: huggingface.co
Title: how to generate
Link: https://huggingface.co/blog/how-to-generateSource snippet
text: using different decoding methods for...Mar 1, 2020 — This blog post gives a brief overview of different decoding strategies and mo...
-
Source: huggingface.co
Title: A R LLM Demo
Link: https://huggingface.co/spaces/yasserrmd/AR-LLM-DemoSource snippet
You can control the generation process with various...
-
Source: huggingface.co
Link: https://huggingface.co/docs/transformers/en/main_classes/text_generationSource snippet
GenerationA class containing all functions for auto-regressive text generation, to be used as a mixin in model classes. Inheriting from t...
-
Source: huggingface.co
Link: https://huggingface.co/docs/transformers/v4.47.1/generation_strategiesSource snippet
Text generation strategiesInternally, the main model input tokens are re-encoded into assistant model tokens, then candidate tokens are g...
-
Source: huggingface.co
Title: Unit 3
Link: https://huggingface.co/learn/audio-course/en/chapter3/introductionSource snippet
Transformer architectures for audioThe decoder uses the encoder's representation (the features) along with other inputs (the previously p...
-
Source: huggingface.co
Link: https://huggingface.co/learn/llm-course/chapter1/5Source snippet
How 🤗 Transformers solve tasksIt's a standard Transformer decoder trained to predict the next text token given the previous tokens and th...
-
Source: huggingface.co
Title: decoding strategies
Link: https://huggingface.co/blog/mlabonne/decoding-strategiesSource snippet
in Large Language ModelsOct 29, 2024 — In this article, we will explore how LLMs generate text by looking into the mechanics of greedy se...
-
Source: Wikipedia
Title: Open AI
Link: https://en.wikipedia.org/wiki/OpenAISource snippet
OpenAIOpenAI Global, LLC is an American artificial intelligence (AI) research organization consisting of a for-profit public benefit c...
-
Source: linkedin.com
Link: https://www.linkedin.com/company/openaiSource snippet
OpenAIOpenAI is an AI research and deployment company dedicated to ensuring that general-purpose artificial intelligence benefits all of...
-
Source: vellum.ai
Link: https://www.vellum.ai/llm-parameters/temperatureSource snippet
LLM Parameter Guide - VellumThe temperature parameter controls the randomness of the generated text. Adjusting the temperature changes ho...
Additional References
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/satyamallick_ai-hallucinations-why-language-models-sometimes-activity-7437540136567005185-DO2-Source snippet
AI Hallucinations: Language Models' Factual FlawsToday, we are cracking the code on why language models hallucinate, and the answer is su...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/arun-nandewal_just-read-the-latest-release-from-openai-activity-7370846974587068416-fiGuSource snippet
Why do language models hallucinate? | Arun NandewalEven if we had perfectly clean training data, models would still guess. Why? Because p...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/risman-adnan-bb726b5_why-language-models-hallucinatepdf-activity-7371852543506829312-_toXSource snippet
OpenAI paper reveals why LLMs hallucinate, urging a shift...The tl;dr for the conclusion is that language models hallucinate because of...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/jamesduez_why-language-models-hallucinate-activity-7375098888090832896-ZSLU -
Source: ai.stackexchange.com
Title: has anyone tried to train a gpt model predicting the next n tokens instead of th
Link: https://ai.stackexchange.com/questions/40086/has-anyone-tried-to-train-a-gpt-model-predicting-the-next-n-tokens-instead-of-thSource snippet
anyone tried to train a GPT model predicting the next...Apr 16, 2023 — I have been thinking about how learning via text works on humans...
-
Source: linkedin.com
Title: smsubham big update from openai research theyve activity 7370346336581373953 wcQ
Link: https://www.linkedin.com/posts/smsubham_big-update-from-openai-research-theyve-activity-7370346336581373953-wcQ_Source snippet
OpenAI research reveals why large language models...OpenAI's recent research confirmed that this problem is deeply tied to how next-toke...
-
Source: reddit.com
Title: I understand that both are related to sampling, but why are there two parameters
Link: https://www.reddit.com/r/GPT3/comments/qujerp/what_is_the_difference_between_temperature_and/Source snippet
What is the difference between temperature and top p...Hi, I'm interested in hearing how you interpret these model parameters...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/akshit-madan_day-1-of-mastering-[generative-aiSource snippet
Mastering Generative AI: temperature, top_k, top_p in LLMsTemperature controls how "adventurous" the model gets when selecting tokens...
-
Source: pryon.com
Title: Reasoning Models Hallucinate More — Marking Trouble
Link: https://www.pryon.com/resource/reasoning-models-hallucinate-more—-marking-trouble-for-ai-agent-adoptionSource snippet
May 16, 2025 — Reasoning models like OpenAI's o3, o4 mini or DeepSeek R1 are significantly more prone to hallucinations than their base m...
Published: May 16, 2025
-
Source: reddit.com
Link: https://www.reddit.com/r/ChatGPT/comments/1cvvbcq/if_llms_are_just_next_token_prediction_how_are/Source snippet
generally work by predicting the next token (word or subword) in a sequence...
Topic Tree