Within Narrow vs AGI
Do benchmark wins prove intelligence?
Fast gains on hard tests can show real progress while still leaving gaps in adaptability, reliability, and real-world judgment.
On this page
- What modern AI benchmarks are designed to measure
- Why static tests can overstate real world competence
- How to read benchmark claims without hype
Page outline Jump by section
Introduction
Strong benchmark results are evidence that AI systems are improving, but they are not proof that artificial general intelligence (AGI) has arrived. Modern models have achieved dramatic gains on difficult tests in science, coding, mathematics, and multimodal reasoning. Yet a benchmark victory shows success on a specific evaluation, not necessarily the broad adaptability, reliability, and real-world judgement usually associated with general intelligence. The central challenge is that intelligence is broader than any fixed test. A system can excel on carefully designed tasks while still failing in unfamiliar situations, making inconsistent decisions, or struggling to transfer its abilities outside the conditions under which it was evaluated. [Stanford HAI]hai.stanford.edutechnical performanceStanford HAITechnical Performance | The 2025 AI Index ReportIn 2023, AI researchers introduced several challenging new benchmarks, includ…
 The debate is not whether benchmark progress is real—it clearly is. The question is what benchmark scores actually measure and how much they should influence claims that AI has crossed a threshold into general intelligence.
The debate is not whether benchmark progress is real—it clearly is. The question is what benchmark scores actually measure and how much they should influence claims that AI has crossed a threshold into general intelligence.
Do benchmark wins prove intelligence?
The short answer is no. Benchmark wins provide evidence of capability, but capability and general intelligence are not identical concepts.
Researchers use benchmarks because they offer a standard way to compare systems. Recent evaluations such as MMMU (Massive Multitask Multimodal Understanding), GPQA (Graduate-Level Google-Proof Question Answering), and SWE-bench have become important because they test skills that were previously difficult for AI systems. Stanford’s 2025 AI Index documented rapid gains on all three, with some models improving by tens of percentage points in a single year. [Stanford HAI]hai.stanford.edutechnical performanceStanford HAITechnical Performance | The 2025 AI Index ReportIn 2023, AI researchers introduced several challenging new benchmarks, includ…
These improvements matter. They demonstrate that models are becoming better at solving complex problems. However, even exceptional performance on such tests does not automatically establish that a system possesses the flexible, open-ended intelligence implied by AGI. A benchmark typically measures success within a predefined task distribution, whereas AGI is usually imagined as competence across a vast range of unfamiliar environments and goals. [arXiv]arxiv.orgUnderstanding and Benchmarking Artificial Intelligence: OpenAI's o3 Is Not AGIJanuary 13, 2025…
A useful comparison is human examination performance. A student who scores highly on a difficult exam has demonstrated important skills, but the result alone does not reveal how well that person will handle novel situations, long-term planning, social judgement, creativity under uncertainty, or real-world responsibility. The same caution applies to AI systems.
What modern AI benchmarks are designed to measure
Most contemporary benchmarks are created to test specific dimensions of performance rather than intelligence as a whole.
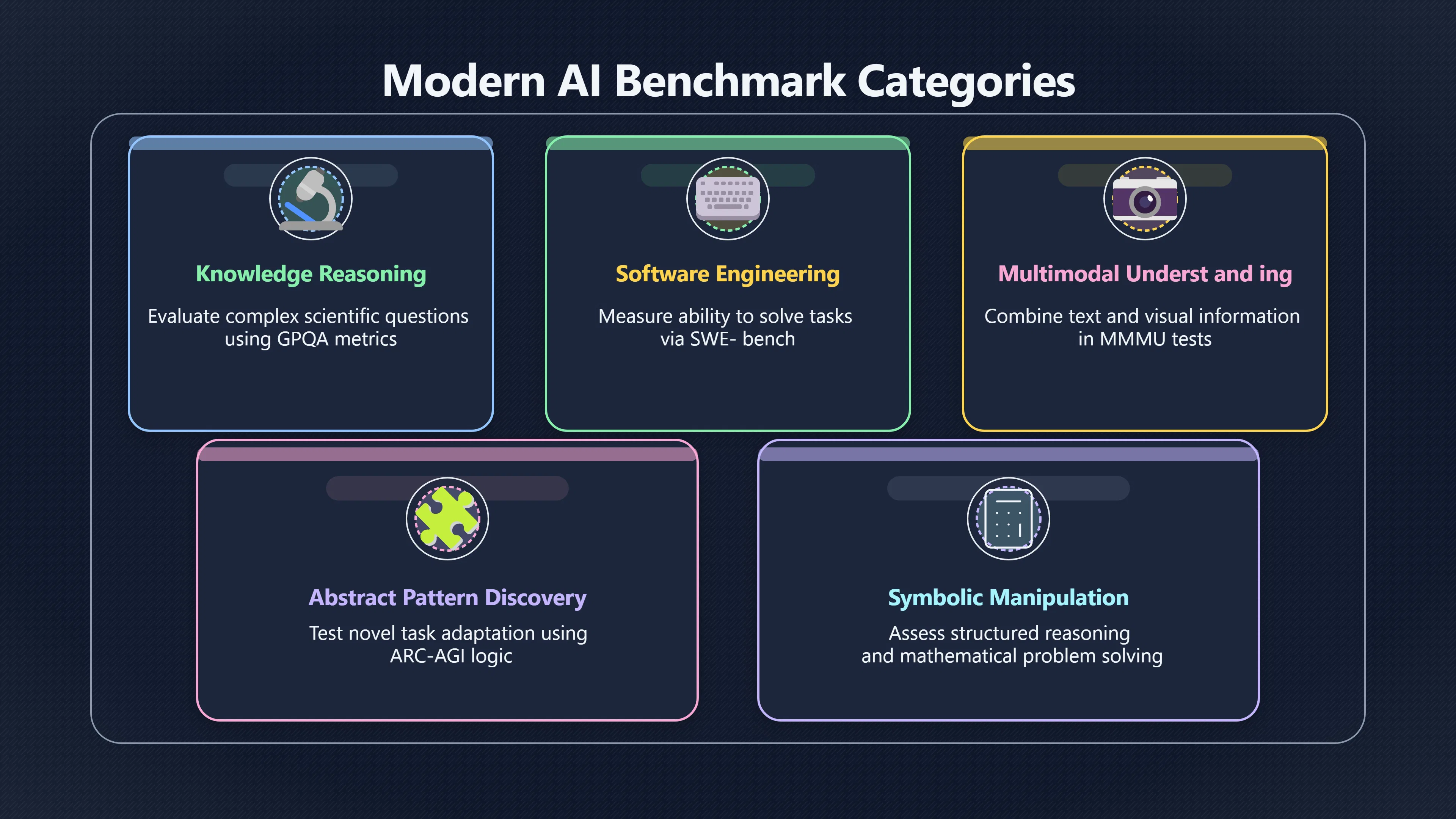
Examples include:
- Knowledge and reasoning benchmarks such as GPQA, which evaluate difficult scientific questions.
- Coding benchmarks such as SWE-bench, which measure the ability to solve software engineering tasks.
- Multimodal benchmarks such as MMMU, which require combining text and visual information.
- Mathematics and problem-solving benchmarks that test structured reasoning and symbolic manipulation.
- General reasoning challenges such as ARC-AGI, which aim to evaluate abstract pattern discovery rather than memorised knowledge. [Stanford HAI]hai.stanford.edutechnical performanceStanford HAITechnical Performance | The 2025 AI Index ReportIn 2023, AI researchers introduced several challenging new benchmarks, includ…
The value of these tests is that they reveal capabilities that are difficult to observe through casual chatbot interactions. They often expose genuine advances in reasoning, planning, and problem-solving.
The limitation is that each benchmark captures only a slice of performance. Success on one benchmark may say little about how a model behaves in a different domain, under changing conditions, or when interacting with people over long periods. Researchers increasingly rely on many benchmarks because no single test provides a complete picture. [arXiv]arxiv.orgOpen source on arxiv.org.
Why static tests can overstate real-world competence
One reason benchmark wins can be misleading is that benchmarks are static while the real world is dynamic.
A benchmark presents a fixed collection of questions or tasks. Once that benchmark becomes important, researchers and companies naturally optimise for it. This creates a version of Goodhart’s Law: when a measure becomes a target, it becomes a less reliable measure of the thing it was intended to represent. [arXiv+2Collinear AI Blog]arxiv.orgTowards More Standardized AI Evaluation: From Models to…20 Feb 2026 — This dynamic is a direct instance of Goodhart's law: “When…
Several effects follow:
Benchmark saturation. Over time, systems become so good at a benchmark that it no longer distinguishes between levels of capability. Scores cluster near the top, making further progress difficult to interpret. [Michael Brenndoerfer+2GIZ Data Lab Blog]mbrenndoerfer.comLearn why static metrics hit ceiling effects, lose statistical power, and how dynamic benchmarks solve this…
Narrow optimisation. Developers may improve performance specifically on benchmark tasks without producing equally large gains elsewhere. A higher score may reflect targeted engineering rather than a broad increase in intelligence. [arXiv]arxiv.orgTowards More Standardized AI Evaluation: From Models to…20 Feb 2026 — This dynamic is a direct instance of Goodhart's law: “When…
Distribution mismatch. Real-world environments contain ambiguity, incomplete information, changing objectives, and social consequences. Benchmarks often simplify these factors to create measurable tasks. A model that succeeds in the benchmark setting may behave differently once deployed. [arXiv]arxiv.orgOpen source on arxiv.org.
This does not make benchmarks useless. It means that benchmark results should be interpreted as evidence of competence under test conditions rather than definitive proof of general intelligence.

The contamination problem
Another reason to treat benchmark claims cautiously is data contamination.
Many AI benchmarks are public. Over time, benchmark questions, solutions, or closely related material can appear in training data. When this happens, it becomes difficult to know whether a model is demonstrating genuine generalisation or recalling patterns it has effectively seen before. [arXiv+2arXiv]arxiv.orgBenchmarking is Broken – Don't Let AI be its Own Judgeby Z Cheng · 2025 · Cited by 9 — Public benchmarks may leak into or be delibe…
Researchers have increasingly warned that contamination can inflate benchmark scores. Reviews of AI evaluation practices identify benchmark leakage as one of the most significant threats to reliable measurement. [arXiv+2arXiv]arxiv.orgOpen source on arxiv.org.
Even when direct memorisation is absent, models may benefit from indirect exposure to similar examples. This makes interpretation harder. A strong score remains evidence of useful capability, but it may be weaker evidence of broad reasoning ability than it first appears.
The contamination issue has become important enough that some benchmark creators now rely on private test sets, hidden evaluation procedures, or continuously updated datasets to preserve measurement quality. [Time]time.comAI Models Are Getting SmarterNew Tests Are Racing to Catch UpDecember 24, 2024 — AI developers are constantly evaluating their systems with new and more challenging t…
The ARC-AGI debate illustrates the problem
The discussion surrounding ARC-AGI provides a useful example of why benchmark success does not settle the AGI question.
ARC-AGI was designed by François Chollet to test abstract reasoning and adaptation to novel tasks. Because it focuses on unfamiliar problems rather than accumulated knowledge, many observers regard it as more relevant to intelligence than traditional question-answering benchmarks. [arXiv]arxiv.orgUnderstanding and Benchmarking Artificial Intelligence: OpenAI's o3 Is Not AGIJanuary 13, 2025…
When advanced models achieved impressive ARC-AGI scores, some commentators viewed the results as evidence that AGI might be close. Others disagreed. Critics argued that high scores could result from specialised search strategies, extensive computation, or benchmark-specific optimisation rather than the kind of flexible intelligence humans display across diverse real-world situations. [arXiv]arxiv.orgUnderstanding and Benchmarking Artificial Intelligence: OpenAI's o3 Is Not AGIJanuary 13, 2025…
The disagreement highlights a broader point: even sophisticated benchmarks measure particular tasks. They can provide evidence for intelligence-related capabilities, but they cannot by themselves resolve philosophical and scientific debates about what AGI actually requires.
How to read benchmark claims without hype
Readers do not need to dismiss benchmark results, but they should ask a few practical questions.
What does the benchmark measure? A coding benchmark, reasoning benchmark, and multimodal benchmark test different abilities.
Is performance improving across many benchmarks or only one? Broad improvement is usually more meaningful than a single standout score.
How well does the benchmark reflect real-world use? A model may excel on laboratory tests while remaining unreliable in practical deployment.
Could contamination or benchmark-specific optimisation be influencing results? Public benchmarks become easier to target over time. [arXiv]arxiv.orgBenchmarking is Broken – Don't Let AI be its Own Judgeby Z Cheng · 2025 · Cited by 9 — Public benchmarks may leak into or be delibe…
Are independent evaluations available? Third-party testing often provides a more balanced picture than vendor-reported scores alone. [Time]time.comAI Models Are Getting SmarterNew Tests Are Racing to Catch UpDecember 24, 2024 — AI developers are constantly evaluating their systems with new and more challenging t…
The most informative evidence comes from converging signals: strong benchmark performance, robust real-world behaviour, adaptation to unfamiliar tasks, and reliability across different evaluation methods.

What benchmark wins actually tell us
Benchmark victories are neither meaningless nor decisive. They demonstrate that AI systems can master increasingly demanding tasks and that technical progress is occurring at a remarkable pace. Stanford’s recent measurements of gains on MMMU, GPQA, and SWE-bench are genuine indicators of advancing capability. [Stanford HAI]hai.stanford.edutechnical performanceStanford HAITechnical Performance | The 2025 AI Index ReportIn 2023, AI researchers introduced several challenging new benchmarks, includ…
What they do not show is that AI has solved the broader challenge of general intelligence. Static tests cannot fully capture adaptability, robustness, judgement, long-term planning, or performance in unfamiliar environments. As a result, benchmark wins should be treated as important evidence of progress rather than proof that AGI has arrived. [arXiv+2arXiv]arxiv.orgOpen source on arxiv.org.
Amazon book picks
Further Reading
Books and field guides related to Do benchmark wins prove intelligence?. Use these as the next step if you want deeper reading beyond the article.
Artificial Intelligence
Explains why benchmark success and impressive performance do not necessarily imply general intelligence.
Human Compatible
Discusses capability measurement, limitations, and the gap between performance and intelligence.
The Alignment Problem
Highlights the difference between measured performance and robust real-world competence.
The Emerging Science of Machine Learning Benchmarks
Directly examines what benchmarks measure, where they fail, and how to interpret results.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: hai.stanford.edu
Title: technical performance
Link: https://hai.stanford.edu/ai-index/2025-ai-index-report/technical-performanceSource snippet
Stanford HAITechnical Performance | The 2025 AI Index ReportIn 2023, AI researchers introduced several challenging new benchmarks, includ...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2502.06559 -
Source: arxiv.org
Link: https://arxiv.org/abs/2501.07458Source snippet
Understanding and Benchmarking Artificial Intelligence: OpenAI's o3 Is Not AGIJanuary 13, 2025...
Published: January 13, 2025
-
Source: arxiv.org
Link: https://arxiv.org/html/2605.14164v1Source snippet
Unsteady Metrics and Benchmarking Cultures of AI Model...13 May 2026 — Few benchmarks achieve true widespread use (e.g., GPQA Diamo...
Published: May 2026
-
Source: arxiv.org
Link: https://arxiv.org/html/2602.18029v1Source snippet
Towards More Standardized AI Evaluation: From Models to...20 Feb 2026 — This dynamic is a direct instance of Goodhart's law: “When...
-
Source: blog.collinear.ai
Title: gaming the system goodharts law exemplified in ai leaderboard controversy
Link: https://blog.collinear.ai/p/gaming-the-system-goodharts-law-exemplified-in-ai-leaderboard-controversySource snippet
Collinear AI BlogGoodhart's Law Exemplified in AI Leaderboard Controversy15 May 2025 — The recent uproar over the LMSYS (now LMArena) Cha...
Published: May 2025
-
Source: arxiv.org
Link: https://arxiv.org/pdf/2510.07575Source snippet
Benchmarking is Broken -- Don't Let AI be its Own Judgeby Z Cheng · 2025 · Cited by 9 — Public benchmarks may leak into or be delibe...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2603.21636 -
Source: arxiv.org
Title: arXiv Benchmarking is Broken
Link: https://arxiv.org/html/2510.07575v1Source snippet
Benchmarking is Broken - Don't Let AI be its Own Judge8 Oct 2025 — Issues like data contamination and selective reporting by model develo...
-
Source: arxiv.org
Title: arXiv Benchmarking is Broken
Link: https://arxiv.org/html/2510.07575v2Source snippet
Benchmarking is Broken - Don't Let AI be its Own JudgeIssues like data contamination and selective reporting by model developers fuel hyp...
-
Source: time.com
Title: AI Models Are Getting Smarter
Link: https://time.com/7203729/ai-evaluations-safety/Source snippet
New Tests Are Racing to Catch UpDecember 24, 2024 — AI developers are constantly evaluating their systems with new and more challenging t...
Published: December 24, 2024
-
Source: hai.stanford.edu
Title: hai ai index report 2025 chapter2 final
Link: https://hai.stanford.edu/assets/files/hai_ai-index-report-2025_chapter2_final.pdfSource snippet
2: Technical Performancebenchmarks, including MMMU, GPQA, and SWE-bench, aimed at testing the limits of increasingly capable AI systems...
-
Source: mbrenndoerfer.com
Link: https://mbrenndoerfer.com/writing/benchmark-saturation-ai-evaluation-metricsSource snippet
Learn why static metrics hit ceiling effects, lose statistical power, and how dynamic benchmarks solve this...
-
Source: blog-datalab.com
Title: making sense of ai benchmarks
Link: https://blog-datalab.com/making-sense-of-ai-benchmarks/Source snippet
GIZ Data Lab BlogMaking Sense of AI Benchmarks4 Sept 2025 — What are the challenges in benchmark evaluation? Despite their utility, AI be...
-
Source: llm-stats.com
Link: https://llm-stats.com/benchmarksSource snippet
AI Benchmarks 2026The benchmark tests AI's ability to understand document structure and content, requiring models to comprehend document...
Additional References
-
Source: openreview.net
Link: https://openreview.net/pdf?id=Y5LJrvfAISSource snippet
AI Benchmarks: Interdisciplinary Issues and Policy...by M Eriksson — This paper summarises the results of an interdisci- plinary meta-re...
-
Source: reuters.com
Link: https://www.reuters.com/technology/artificial-intelligence/ai-experts-ready-humanitys-last-exam-stump-powerful-tech-2024-09-16/Source snippet
El proyecto, llamado "Humanity's Last Exam", es organizado por el Centro para la Seguridad de la IA (CAIS) y la startup Scale AI. El anun...
-
Source: vox.com
Link: https://www.vox.com/future-perfect/394336/artificial-intelligence-openai-o3-benchmarks-agiSource snippet
In 2024, it was observed that existing AI systems are powerful enough to significantly change our world. OpenAI's latest large language m...
-
Source: reddit.com
Link: https://www.reddit.com/r/BetterOffline/comments/1rj2pi2/please_look_inside_the_ai_benchmarks_before/Source snippet
Please, look inside the AI benchmarks before talking about...SWE-Bench Verified, and likely all the open benchmarks, are also contamina...
-
Source: theguardian.com
Link: https://www.theguardian.com/technology/2025/nov/04/experts-find-flaws-hundreds-tests-check-ai-safety-effectivenessSource snippet
The study found nearly all benchmarks had weaknesses, with some being misleading or irrelevant, thereby undermining claims about AI model...
-
Source: hub.stabilarity.com
Title: the measurement crisis saturation goodharts law and the end of ai leaderboards
Link: https://hub.stabilarity.com/the-measurement-crisis-saturation-goodharts-law-and-the-end-of-ai-leaderboards/Source snippet
Measurement Crisis: Saturation, Goodhart's Law, and the...13 Mar 2026 — We show that [business]({{ 'business-adoption/' | relative_url }}) deployment metrics from our Cost-Effective...
-
Source: forum.gnoppix.org
Title: ai benchmarks are broken and the industry keeps using them anyway study finds
Link: https://forum.gnoppix.org/t/ai-benchmarks-are-broken-and-the-industry-keeps-using-them-anyway-study-finds/3890Source snippet
benchmarks are broken and the industry keeps using...10 Jan 2026 — AI Benchmarks Are Flawed Due to Data Contamination, Yet the Industry...
-
Source: medium.com
Title: modern ai benchmarks what practitioners actually need to know b59f2367ef9f
Link: https://medium.com/%40adnanmasood/modern-ai-benchmarks-what-practitioners-actually-need-to-know-b59f2367ef9fSource snippet
Modern AI Benchmarks: What Practitioners Actually Need...A practitioner's guide to AI benchmarks in 2026: what SWE-bench, GDPval, ARC-AG...
-
Source: notes.muthu.co
Title: agent evaluation and benchmarking for measuring what matters
Link: https://notes.muthu.co/2026/02/agent-evaluation-and-benchmarking-for-measuring-what-matters/Source snippet
Evaluation and Benchmarking for Measuring What...19 Feb 2026 — The shift to agent evaluation reflects Goodhart's Law in action: when LLM...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/ais-dirty-little-secret-why-most-benchmarks-joke-how-changes-danu-s-jmiqcSource snippet
It's bold, it's uncompromising, and it's precisely what the AI community needs...Read more...
Topic Tree