Within Human Review
Why a Score Is Not Enough
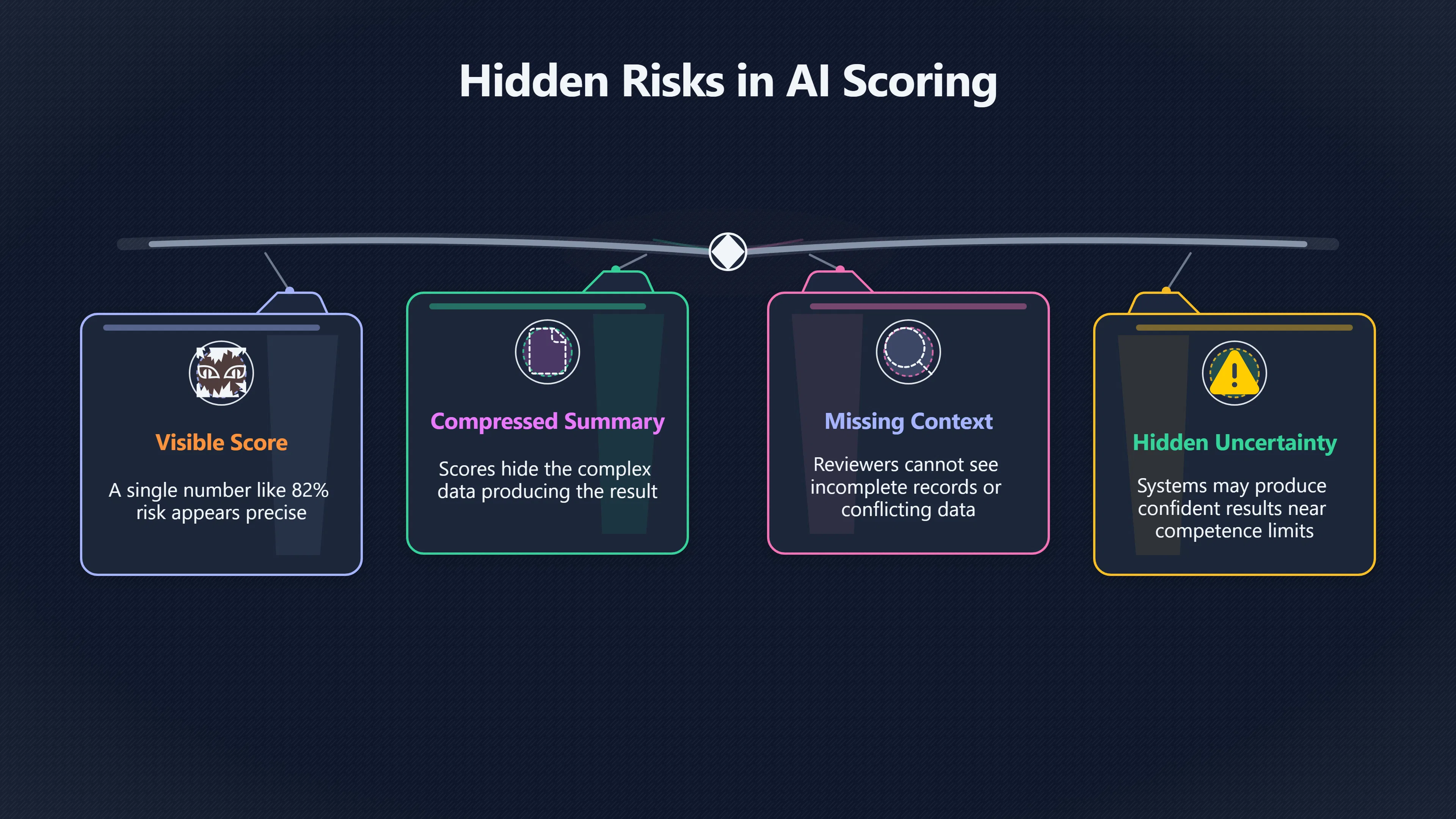
A human reviewer cannot judge a high-risk AI decision meaningfully when the system shows only a score or final recommendation.
On this page
- What reviewers need to see before deciding
- How uncertainty and missing context change judgement
- Design choices that make challenge possible
Page outline Jump by section
Introduction
In high-risk AI systems, a human reviewer is often expected to provide a safeguard against mistakes. That safeguard breaks down if the reviewer sees only a score, ranking, risk label or recommendation. A number such as “82% risk”, “deny”, or “high priority” may appear precise, but it does not tell the reviewer whether the result is based on reliable evidence, whether important information is missing, or how uncertain the system is about its conclusion.
 This matters because high-risk AI systems influence decisions about employment, healthcare, benefits, credit, policing and critical infrastructure. Modern oversight frameworks increasingly emphasise that humans must be able to understand, interpret and, when necessary, override AI outputs. Meaningful oversight therefore depends on access to evidence, context and uncertainty information—not merely the final score. [AI Act Service Desk]ai-act-service-desk.ec.europa.euAI Act Service Desk Article 14: Human oversight | AI Act Service DeskAI Act Service DeskArticle 14: Human oversight | AI Act Service DeskJune 13, 2024…
This matters because high-risk AI systems influence decisions about employment, healthcare, benefits, credit, policing and critical infrastructure. Modern oversight frameworks increasingly emphasise that humans must be able to understand, interpret and, when necessary, override AI outputs. Meaningful oversight therefore depends on access to evidence, context and uncertainty information—not merely the final score. [AI Act Service Desk]ai-act-service-desk.ec.europa.euAI Act Service Desk Article 14: Human oversight | AI Act Service DeskAI Act Service DeskArticle 14: Human oversight | AI Act Service DeskJune 13, 2024…
Why a Score Is Not Enough
A score is a compressed summary. By design, it hides much of the information that produced it.
Imagine two applicants receiving the same risk score from a lending system. One score may be driven by a short credit history. The other may result from incomplete records, conflicting data or unusual circumstances that the model struggles to interpret. If reviewers see only the identical score, they cannot distinguish between these situations.
This creates a practical problem: reviewers are asked to judge a decision without seeing the reasons that support it. Instead of independently evaluating the case, they are pushed toward accepting the AI’s conclusion. European AI oversight requirements specifically recognise this danger by requiring that human overseers can correctly interpret outputs and remain aware of automation bias—the tendency to rely too heavily on automated recommendations. [AI Act Service Desk]ai-act-service-desk.ec.europa.euAI Act Service Desk Article 14: Human oversight | AI Act Service DeskAI Act Service DeskArticle 14: Human oversight | AI Act Service DeskJune 13, 2024…
The issue is not that scores are useless. Scores can help prioritise cases or summarise complex information. The problem arises when the score becomes the only visible output. At that point, the human reviewer no longer has enough information to perform a genuine review.
What Reviewers Need to See Before Deciding
Effective oversight requires access to the underlying evidence that supports a recommendation.
Depending on the application, that evidence may include:
- The key factors that influenced the result.
- The source and quality of the data used.
- Information that was unavailable or incomplete.
- Alternative explanations that the system considered.
- Indicators showing how confident the system is.
- Historical performance data for similar cases.
For example, in a hiring system, a reviewer should be able to see which qualifications, experiences or assessment results contributed to a recommendation. In healthcare, a clinician reviewing an AI-assisted diagnosis may need access to the underlying measurements, images or symptoms that informed the model’s assessment.
Without this information, the reviewer is effectively asked to trust the machine rather than evaluate it.
Research and governance frameworks frequently connect explainability, interpretability and auditability to trustworthy AI because these properties allow human decision-makers to reconstruct and verify why a recommendation was produced. A decision that cannot be inspected cannot be meaningfully challenged. Reasoning Systems Authority+2NIST AI Resource Center [reasoningsystemsauthority.com]reasoningsystemsauthority.comOpen source on reasoningsystemsauthority.com.
Evidence Supports Accountability
Evidence is also necessary after a decision has been made.
If a person is denied a benefit, refused a loan or incorrectly flagged by a security system, investigators need to determine what happened. A score alone offers little help. Reviewers need records showing what information the system used, how it processed that information and what warning signs may have been present.
This is why auditability has become an increasingly important requirement in regulated environments. Evidence trails allow organisations to investigate failures, identify recurring problems and determine whether human reviewers exercised appropriate judgement. [Reasoning Systems Authority]reasoningsystemsauthority.comOpen source on reasoningsystemsauthority.com.
How Uncertainty and Missing Context Change Judgement
One of the most important pieces of evidence is uncertainty.
Many AI systems can produce a confident-looking result even when they are operating near the limits of their competence. A score of 0.85 may look decisive, yet the system may have encountered unusual circumstances, sparse data or conflicting inputs.
When uncertainty is hidden, reviewers may assume that all recommendations deserve equal trust. When uncertainty is visible, the reviewer’s behaviour can change dramatically. Cases with missing information, weak evidence or unusual patterns can be escalated for deeper examination instead of being treated as routine.
This distinction is especially important in high-risk settings because human reviewers often possess contextual knowledge that the AI lacks. A welfare caseworker may know about a recent life event affecting an applicant. A doctor may recognise symptoms that are poorly represented in training data. A credit analyst may notice that a score was affected by an administrative error rather than genuine financial risk.
The reviewer can only contribute that knowledge if the system reveals where uncertainty exists and where additional context may matter.

The Difference Between Error Detection and Error Prevention
Scores help people identify outcomes. Evidence helps them identify mistakes.
A reviewer who sees only a final recommendation can often detect obvious anomalies. However, they may miss subtle failures caused by biased data, missing records or unusual circumstances.
When evidence is available, reviewers can examine whether the AI’s reasoning process appears appropriate for the case at hand. This shifts oversight from passive acceptance to active evaluation.
Scholars studying explainability have noted that high accuracy alone does not guarantee good human-AI decision-making. Human reviewers improve outcomes only when they can appropriately rely on the system—following it when it is correct and challenging it when it is not. That requires access to information beyond the final prediction. [Springer]link.springer.comAccuracy is not all you need! The Reasons to Require AI Explainability | Minds and Machines | Springer Nature LinkFebruary 27, 2026…

Design Choices That Make Challenge Possible
Whether oversight is meaningful often depends on interface design rather than abstract governance principles.
A system that merely displays a score encourages deference. A system that displays evidence, uncertainty and relevant context encourages scrutiny.
Several design choices make challenge more realistic:
Reason displays. Show the main factors influencing a recommendation rather than only the outcome.
Confidence indicators. Communicate uncertainty levels and data limitations clearly.
Data provenance information. Allow reviewers to identify where information originated and whether it may be outdated or incomplete.
Access to underlying records. Enable reviewers to inspect the evidence supporting a recommendation.
Override pathways. Make it easy to reject, reverse or escalate an AI-generated result.
Challenge prompts. Deliberately encourage reviewers to consider alternative explanations before accepting a recommendation.
These features help counter automation bias by reminding reviewers that the system is an aid to judgement rather than a replacement for it. European oversight requirements explicitly emphasise the need for humans to understand system limitations, interpret outputs correctly and disregard or override recommendations when appropriate. [AI Act Service Desk]ai-act-service-desk.ec.europa.euAI Act Service Desk Article 14: Human oversight | AI Act Service DeskAI Act Service DeskArticle 14: Human oversight | AI Act Service DeskJune 13, 2024…
The Real Test of Human Oversight
The simplest way to evaluate a human oversight process is to ask a practical question: could the reviewer explain why they agreed or disagreed with the AI?
If the only available answer is “because the system gave a high score”, oversight is largely symbolic. If the reviewer can point to evidence, identify uncertainty, explain contextual factors and justify an override or acceptance, then oversight becomes a genuine safeguard.
In high-risk AI systems, meaningful human review is therefore not defined by the presence of a person in the workflow. It is defined by whether that person has enough evidence to make an informed judgement that is independent of the score placed in front of them. [AI Act Service Desk+2European Commission]ai-act-service-desk.ec.europa.euAI Act Service Desk Article 14: Human oversight | AI Act Service DeskAI Act Service DeskArticle 14: Human oversight | AI Act Service DeskJune 13, 2024…
Amazon book picks
Further Reading
Books and field guides related to Why a Score Is Not Enough. Use these as the next step if you want deeper reading beyond the article.
The Black Box Society
Addresses transparency and the information humans need to review automated decisions.
The Alignment Problem
Explains uncertainty, model limitations, and interpretability challenges.
Human Compatible
Highlights the need for humans to understand and supervise AI behaviour.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: airc.nist.gov
Title: AI Resource Center AI RMF
Link: https://airc.nist.gov/airmf-resources/airmf/?msockid=230452fd411163c516a4445a405c6214Source snippet
NIST AI Resource CenterAI RMF - AIRC...
-
Source: nist.gov
Title: Trustworthy and [responsible AI]({{ ‘responsible-ai/’ | relative_url }}) | NIST
Link: https://www.nist.gov/trustworthy-and-responsible-aiSource snippet
Trustworthy and responsible AI | NIST...
-
Source: link.springer.com
Link: https://link.springer.com/article/10.1007/s11023-026-09768-xSource snippet
Accuracy is not all you need! The Reasons to Require AI Explainability | Minds and Machines | Springer Nature LinkFebruary 27, 2026...
Published: February 27, 2026
-
Source: nist.gov
Title: www.nist.gov A I Risk Management Framework
Link: https://www.nist.gov/node/1674691Source snippet
Risk Management Framework - Engage | NISTApril 9, 2025...
Published: April 9, 2025
-
Source: nist.gov
Title: ai risk management framework
Link: https://www.nist.gov/itl/ai-risk-management-frameworkSource snippet
Risk Management Framework | NISTJanuary 26, 2023...
Published: January 26, 2023
-
Source: ai-act-service-desk.ec.europa.eu
Title: AI Act Service Desk Article 14: Human oversight | AI Act Service Desk
Link: https://ai-act-service-desk.ec.europa.eu/en/ai-act/article-14Source snippet
AI Act Service DeskArticle 14: Human oversight | AI Act Service DeskJune 13, 2024...
Published: June 13, 2024
-
Source: ec.europa.eu
Link: https://ec.europa.eu/futurium/en/ai-alliance-consultation/guidelines/1.html -
Source: reasoningsystemsauthority.com
Link: https://reasoningsystemsauthority.com/auditability-of-reasoning-systems/
Additional References
-
Source: aisi.gov.uk
Title: www.aisi.gov.uk A I Safety Institute approach to evaluations
Link: https://www.aisi.gov.uk/blog/our-approach-to-evaluationsSource snippet
Safety Institute approach to evaluations - GOV.UKFebruary 9, 2024...
Published: February 9, 2024
-
Source: arxiv.org
Link: https://arxiv.org/abs/2401.15229Source snippet
January 26, 2024...
Published: January 26, 2024
-
Source: youtube.com
Title: [Understanding]({{ ‘understanding/’ | relative_url }}) the importance of explainable AI in education | Francisco Bellas
Link: https://www.youtube.com/watch?v=jbo_wS9xQm8Source snippet
How Skylar Advisor Delivers Answers You Can Trust and Verify...
-
Source: youtube.com
Title: Building Trust in AI, What to Look For | AI Pulse Podcast by ABBYY
Link: https://www.youtube.com/watch?v=NJTir_YaX1oSource snippet
The Truth about AI Agent and Harness Engineering...
-
Source: youtube.com
Title: Taming AI
Link: https://www.youtube.com/watch?v=U3eDmVolcyASource snippet
Understanding the importance of explainable AI in education | Francisco Bellas...
-
Source: youtube.com
Title: The Truth about AI Agent and Harness Engineering
Link: https://www.youtube.com/watch?v=dBm3DkRKW9ESource snippet
Taming AI - Matt Jones...
-
Source: youtube.com
Title: How Skylar Advisor Delivers Answers You Can Trust and Verify
Link: https://www.youtube.com/watch?v=3GDSd_1jBkQ
Topic Tree