Within Deep Learning
Why do deep networks need shortcuts?
Residual connections helped very deep networks learn useful changes without forcing every layer to rebuild the whole signal.
On this page
- Why simply stacking layers can fail
- How residual learning changes the training problem
- Why Res Net mattered beyond one benchmark
Page outline Jump by section
Introduction
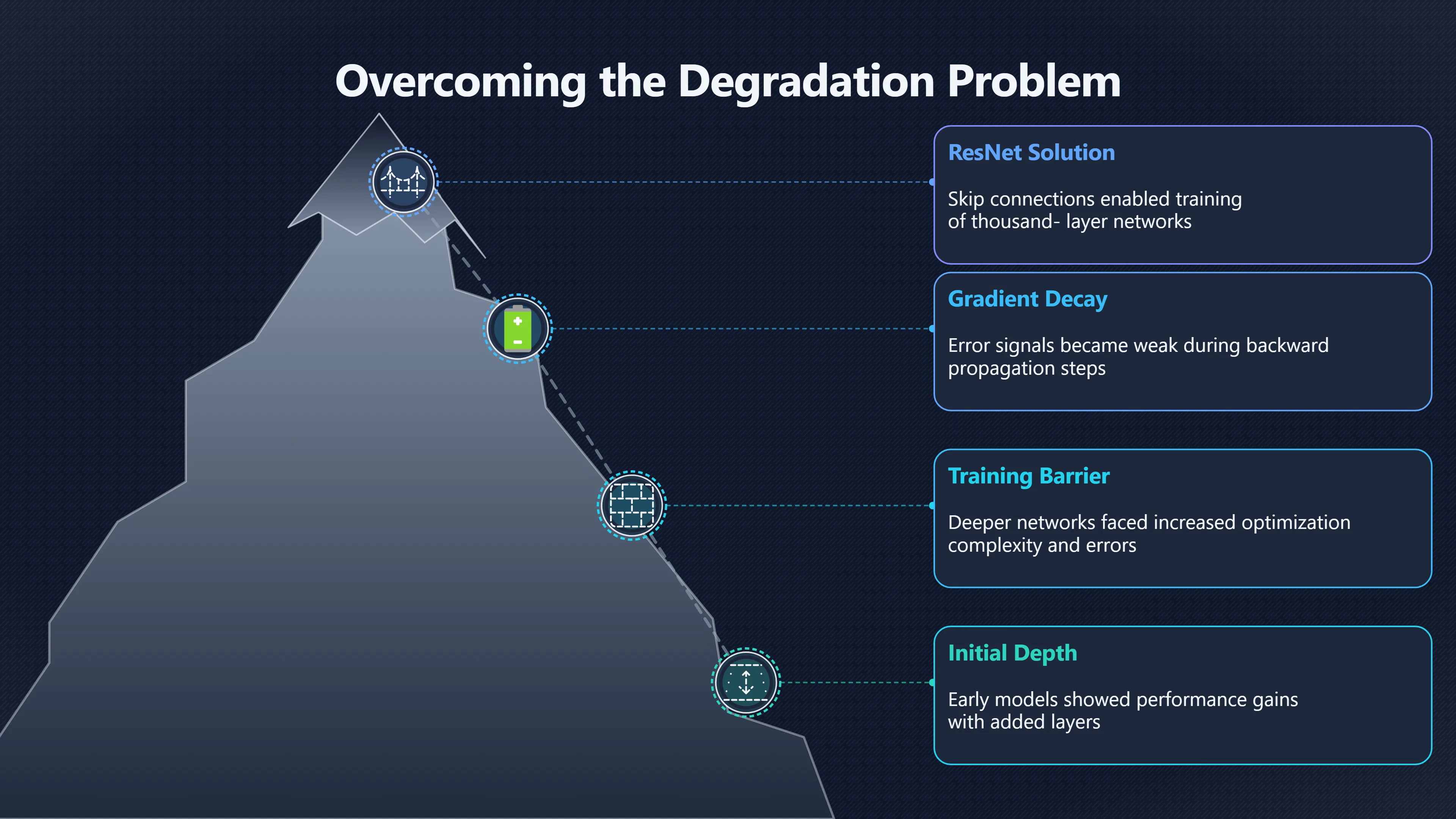
As neural networks became deeper, researchers expected performance to keep improving. Instead, they discovered a surprising problem: simply adding more layers could make a network harder to train and sometimes even less accurate. Skip connections, popularised by the 2015 ResNet (Residual Network) architecture, solved much of this optimisation difficulty by giving information and gradients a direct path through the network. Rather than forcing every layer to completely transform its input, skip connections allowed layers to focus on learning only the useful changes. This seemingly simple architectural adjustment made it practical to train networks with dozens, hundreds, and eventually even more than a thousand layers, helping unlock many later advances in artificial intelligence. [arXiv]arxiv.orgarXiv[1512.03385] Deep Residual Learning for Image RecognitionDecember 10, 2015 — by K He · 2015 · Cited by 315493 — We present a residua…

Why simply stacking layers can fail
The intuitive idea behind deep learning is that more layers should allow a network to learn more complex representations. However, early experiments revealed a problem known as the degradation problem. Researchers found that beyond a certain depth, adding layers could increase training error rather than reduce it. Importantly, this was not merely a matter of overfitting; even on the training data itself, deeper networks could become harder to optimise. [arXiv+2cv-foundation.org]arxiv.orgarXiv:1512.03385v1 [cs.CV] 10 Dec 2015December 10, 2015 — by K He · 2015 · Cited by 320310 — In this paper, we address the degradati…
One reason is that information and error signals must travel through many transformations during training. As gradients are propagated backwards, they can become weak or unstable, making it difficult for earlier layers to learn effectively. Deep networks also face a practical optimisation challenge: each additional layer increases the complexity of the function that training must discover. [arXiv+2GeeksforGeeks]arxiv.orgarXiv Res Net: Enabling Deep Convolutional Neural NetworksResNet: Enabling Deep Convolutional Neural Networks…October 28, 2025 — by X Liu · 2025 · Cited by 4 — Surprisingly, the addition…
A useful thought experiment illustrates the issue. Suppose a 20-layer network already performs well. A 30-layer version should, in theory, be able to achieve at least the same result by letting the extra ten layers do nothing. Yet standard architectures often failed to find this simple solution during training. The deeper model could therefore perform worse even though it contained all the capabilities of the shallower one. This observation became one of the central motivations for residual learning. [arXiv]arxiv.orgarXiv:1512.03385v1 [cs.CV] 10 Dec 2015December 10, 2015 — by K He · 2015 · Cited by 320310 — In this paper, we address the degradati…
How residual learning changes the training problem
The key insight behind ResNet was that layers do not always need to learn an entirely new representation. Often, they only need to make a small adjustment to what already exists.
Instead of asking a stack of layers to learn a complete mapping from input to output, residual learning asks them to learn the difference between the desired output and the original input. In the ResNet formulation, a shortcut path carries the input forward unchanged while the main path learns a residual function. The final output is obtained by combining the two. [arXiv+2arXiv]arxiv.orgarXiv:1512.03385v1 [cs.CV] 10 Dec 2015December 10, 2015 — by K He · 2015 · Cited by 320310 — In this paper, we address the degradati…
A simplified view of a residual block is:
y=F(x)+xy = F(x) + xy=F(x)+x
Here, the shortcut contributes the original signal xxx, while the learned component F(x)F(x)F(x) only has to represent what should change. If the best action is effectively to leave the signal alone, the residual function can approach zero and the block behaves close to an identity mapping. This is far easier for optimisation algorithms to discover than forcing several layers to learn the identity transformation from scratch. [arXiv+2ICML]arxiv.orgarXiv:1512.03385v1 [cs.CV] 10 Dec 2015December 10, 2015 — by K He · 2015 · Cited by 320310 — In this paper, we address the degradati…
The shortcut connection also creates a more direct route for gradients during backpropagation. Error signals can flow through the identity path without being repeatedly distorted by every weight layer, making training more stable as depth increases. Later theoretical analyses linked this behaviour to improved gradient preservation and more reliable optimisation in very deep networks. [arXiv+2abhik.ai]arxiv.orgarXiv Norm-Preservation: Why Residual Networks Can Become Extremely Deep?arXiv Norm-Preservation: Why Residual Networks Can Become Extremely Deep?

What the shortcut is actually doing
A common misunderstanding is that skip connections allow the network to skip learning. In reality, they make learning more selective.
The residual branch can still learn complex transformations when they are useful. The shortcut simply ensures that information already present in the input is not unnecessarily destroyed or reconstructed. Layers can therefore concentrate on refining features rather than repeatedly rebuilding them. [cv-foundation.org+2arXiv]cv-foundation.orgHe Deep Residual Learning CVPR 2016 paperWe explicitly reformulate…Read more…
This changes the optimisation landscape. Instead of every layer carrying the burden of preserving useful information while simultaneously creating new features, the shortcut preserves the baseline signal and the learned branch focuses on improvement. The result is a network that is easier to train even as depth grows dramatically. [cv-foundation.org]cv-foundation.orgHe Deep Residual Learning CVPR 2016 paperWe explicitly reformulate…Read more…
Why ResNet mattered beyond one benchmark
The original ResNet work demonstrated that residual learning could successfully train networks far deeper than those that had previously been practical. The architecture achieved leading results in the ImageNet image-recognition competition and showed that depth could continue to provide benefits when paired with the right optimisation strategy. [cv-foundation.org]cv-foundation.orgHe Deep Residual Learning CVPR 2016 paperWe explicitly reformulate…Read more…
Its influence extended far beyond image classification. Residual connections became a standard design pattern across deep learning because they addressed a general optimisation problem rather than a task-specific one. Variants of the idea appeared in later computer vision systems, language models, reinforcement-learning systems, and scientific AI applications. Surveys of modern architectures consistently identify skip connections as one of the foundational innovations that enabled extremely deep neural networks. [arXiv]arxiv.orgDevelopment of Skip Connection in Deep Neural Networks…2 May 2024 — This survey provides a comprehensive summary and outlook on t…
Perhaps the most important legacy of skip connections is conceptual. They showed that improving neural networks is not only about adding more layers or more parameters. Sometimes the decisive breakthrough comes from changing the way information flows through a model. By allowing layers to learn useful corrections instead of complete reconstructions, residual learning turned depth from a liability into an advantage and made very deep networks practical for modern artificial intelligence. [arXiv+2cv-foundation.org]arxiv.orgarXiv[1512.03385] Deep Residual Learning for Image RecognitionDecember 10, 2015 — by K He · 2015 · Cited by 315493 — We present a residua…

Amazon book picks
Further Reading
Books and field guides related to Why do deep networks need shortcuts?. Use these as the next step if you want deeper reading beyond the article.
Deep Learning
Rating: 3.5/5 from 6 Google Books ratings
Covers optimisation challenges, gradient flow, and deep architectures.
Dive into Deep Learning
Explains modern architectures including residual-style concepts.
Hands-on Machine Learning with Scikit-Learn, Keras, and Tenso...
Includes practical treatment of deep neural network design.
Artificial Intelligence
Rating: 4.5/5 from 10 Google Books ratings
Places deep learning within the wider AI landscape.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.


Endnotes
-
Source: arxiv.org
Link: https://arxiv.org/abs/1512.03385Source snippet
arXiv[1512.03385] Deep Residual Learning for Image RecognitionDecember 10, 2015 — by K He · 2015 · Cited by 315493 — We present a residua...
Published: December 10, 2015
-
Source: cv-foundation.org
Title: He Deep Residual Learning CVPR 2016 paper
Link: https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdfSource snippet
We explicitly reformulate...Read more...
-
Source: arxiv.org
Link: https://arxiv.org/pdf/1512.03385Source snippet
arXiv:1512.03385v1 [cs.CV] 10 Dec 2015December 10, 2015 — by K He · 2015 · Cited by 320310 — In this paper, we address the degradati...
Published: December 10, 2015
-
Source: arxiv.org
Title: arXiv Res Net: Enabling Deep Convolutional Neural Networks
Link: https://arxiv.org/pdf/2510.24036Source snippet
ResNet: Enabling Deep Convolutional Neural Networks...October 28, 2025 — by X Liu · 2025 · Cited by 4 — Surprisingly, the addition...
Published: October 28, 2025
-
Source: geeksforgeeks.org
Title: Geeksfor Geeks Residual Networks (Res Net)
Link: https://www.geeksforgeeks.org/deep-learning/residual-networks-resnet-deep-learning/Source snippet
Residual Networks (ResNet) - Deep LearningMay 12, 2026 — Eases training of deep networks by allowing direct [gradient flow]({{ 'gradient-flow/' | relative_url }}) through skip co...
Published: May 12, 2026
-
Source: arxiv.org
Title: arXiv Norm-Preservation: Why Residual Networks Can Become Extremely Deep?
Link: https://arxiv.org/abs/1805.07477 -
Source: icml.cc
Title: icml2016 tutorial deep residual networks kaiminghe
Link: https://icml.cc/2016/tutorials/icml2016_tutorial_deep_residual_networks_kaiminghe.pdfSource snippet
Deep Residual Networks“Deep Residual Learning for Image Recognition”. CVPR 2016. • If identity were optimal, easy to set weights as 0. •...
-
Source: abhik.ai
Title: skip connections
Link: https://www.abhik.ai/concepts/deep-learning/skip-connectionsSource snippet
in Neural Networks1 Apr 2024 — Skip Connections in Neural Networks. Summary: Learn how skip connections and residual learning enable trai...
-
Source: arxiv.org
Link: https://arxiv.org/html/2405.01725v1Source snippet
Development of Skip Connection in Deep Neural Networks...2 May 2024 — This survey provides a comprehensive summary and outlook on t...
Published: May 2024
-
Source: resnet.us
Link: https://www.resnet.us/about/us/Source snippet
United States.Read more...
-
Source: web.cs.ucdavis.edu
Link: https://web.cs.ucdavis.edu/~yjlee/teaching/ecs289g-winter2018/resnet.pdfSource snippet
Page 2... Identity Mapping. If the “extra” layers are identity functions. The network...Read more...
-
Source: people.csail.mit.edu
Title: cvpr2016 deep residual learning kaiminghe
Link: https://people.csail.mit.edu/kaiming/cvpr16resnet/cvpr2016_deep_residual_learning_kaiminghe.pdfSource snippet
arXiv 2016. Kaiming He, Xiangyu Zhang, Shaoqing Ren, & Jian Sun. “Deep Residual Learning for Image Recognition”.Read more...
-
Source: mohitjain.me
Link: https://mohitjain.me/2018/06/13/resnet/Source snippet
Deep Residual Learning for Image Recognition (ResNet)13 Jun 2018 — The paper analysed what was causing the accuracy of deeper networks to...
-
Source: community.deeplearning.ai
Title: Reading time: 6 min read.Read more
Link: https://community.deeplearning.ai/t/resnet-identity-mapping/48515Source snippet
identity mapping - Convolutional Neural NetworksOct 11, 2021 — Residual learning framework to ease the training of networks that are subs...
Additional References
-
Source: irejournals.com
Link: https://www.irejournals.com/formatedpaper/1703688.pdfSource snippet
Deep Residual Learning for Image RecognitionDegradation Problem: The deeper networks at times visually showcase higher... Skip connectio...
-
Source: semanticscholar.org
Link: https://www.semanticscholar.org/paper/Deep-Residual-Learning-for-Image-Recognition-He-Zhang/2c03df8b48bf3fa39054345bafabfeff15bfd11dSource snippet
Deep Residual Learning for Image RecognitionThis work presents a residual learning framework to ease the training of networks that are su...
-
Source: huggingface.co
Link: https://huggingface.co/learn/computer-vision-course/en/unit2/cnns/resnetSource snippet
ResNet (Residual Network)ResNets introduce a concept called residual learning, which allows the network to learn the residuals (i.e., the...
-
Source: medium.com
Link: https://medium.com/%40kdwaMachineLearning/resnet-explained-how-skip-connections-saved-deep-learning-faed41c36418Source snippet
ResNet Explained: How Skip Connections Saved Deep...Researchers introduced residual connections that skip one or more layers and add the...
-
Source: medium.com
Link: https://medium.com/%40tnodecode/resnet-e7e0cba19e04Source snippet
ResNet. How skip connections enabled very deep…How skip connections enabled very deep networks and tackled problems like vanishing gradie...
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/286512696_Deep_Residual_Learning_for_Image_RecognitionSource snippet
Deep Residual Learning for Image RecognitionWe present a residual learning framework to ease the training of networks that are substantia...
-
Source: medium.com
Link: https://medium.com/deepreview/review-of-identity-mappings-in-deep-residual-networks-ad6533452f33Source snippet
Review of Identity Mappings in Deep Residual NetworksIn this paper, the authors investigate the nature of residual networks and the impac...
-
Source: medium.com
Link: https://medium.com/%40zilliz_learn/deep-residual-learning-for-image-recognition-0025592e3910 -
Source: merriam-webster.com
Link: https://www.merriam-webster.com/dictionary/residualSource snippet
RESIDUAL Definition & Meaning1. of, relating to, or being a residue 2. leaving a residue that is effective for some time afterwardRead more...
-
Source: viso.ai
Link: https://viso.ai/deep-learning/resnet-residual-neural-network/Source snippet
It is an innovative neural network architecture that was first introduced by Kaiming He, Xiangyu Zhang, Shaoqing Ren, and...Read more...
Topic Tree