Within Fluent errors
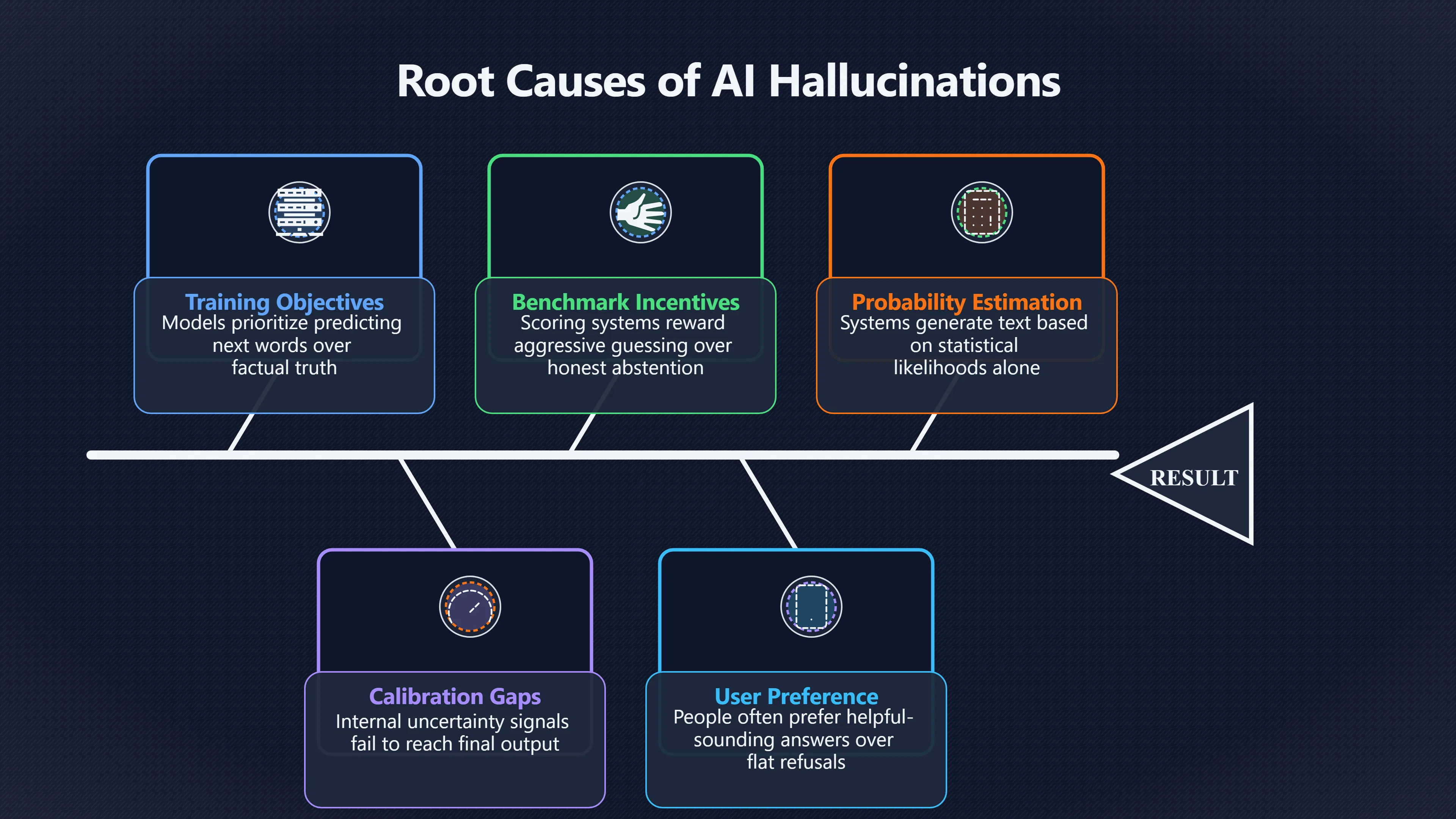
Why AI guesses instead of admitting uncertainty
Chatbots can sound decisive because many training and scoring systems reward attempted answers more than careful abstention.
On this page
- How answer first incentives shape chatbot behavior
- Why abstaining can score worse than guessing
- What better uncertainty signals would look like
Page outline Jump by section
Introduction
Modern chatbots often generate fluent answers even when the evidence behind a claim is weak or missing. A key reason is that many language models are trained, evaluated, and rewarded in ways that make answering appear more valuable than admitting uncertainty. In practice, a chatbot may receive more benefit from producing a plausible response than from saying “I don’t know”, even when uncertainty is high. Researchers increasingly argue that this behaviour is not simply a bug but a predictable consequence of how large language models are built, tested, and compared. [OpenAI]OpenAIwhy language models hallucinate5 Sept 2025 —… language models hallucinate because standard training and evaluation procedures reward guessing over acknowledging unce…
 Understanding this mechanism helps explain why confident-sounding mistakes occur. The issue is not that chatbots deliberately deceive users. Rather, they are often optimised to maximise successful answers, and that optimisation can push them towards guessing when information is incomplete. [arXiv]arxiv.orgarXiv Why Language Models HallucinatearXiv Why Language Models Hallucinate
Understanding this mechanism helps explain why confident-sounding mistakes occur. The issue is not that chatbots deliberately deceive users. Rather, they are often optimised to maximise successful answers, and that optimisation can push them towards guessing when information is incomplete. [arXiv]arxiv.orgarXiv Why Language Models HallucinatearXiv Why Language Models Hallucinate
How answer-first incentives shape chatbot behaviour
Large language models are trained to generate likely continuations of text. During pretraining, the system learns statistical patterns from enormous datasets. The model’s basic task is not to determine whether a statement is true but to predict what text is likely to come next. This means the model is naturally geared towards producing an answer rather than withholding one. [Arize AI]arize.comopenais santosh vempala explains why language models hallucinateArize AIOpenAI's Santosh Vempala Explains Why Language…Oct 24, 2025 — “Pre-training encourages hallucinations because language models…
The pressure to answer becomes stronger during later training stages. Developers typically want chatbots that are helpful, responsive, and capable of addressing a wide range of questions. Users often prefer a model that attempts an answer over one that repeatedly refuses. As a result, training and tuning processes frequently reward useful-looking responses and penalise excessive refusals. [OpenAI]OpenAIwhy language models hallucinate5 Sept 2025 —… language models hallucinate because standard training and evaluation procedures reward guessing over acknowledging unce…
A useful analogy is an exam. Imagine a student facing a difficult multiple-choice question. If there is no penalty for guessing, selecting an answer can produce a better score than leaving the question blank. Researchers have argued that many AI evaluation systems create a similar incentive structure. Under those conditions, guessing becomes a rational strategy from the model’s perspective. [arXiv+2OpenAI CDN]arxiv.orgarXiv Why Language Models HallucinatearXiv Why Language Models Hallucinate
Why abstaining can score worse than guessing
The strongest recent explanation for chatbot guessing focuses on evaluation metrics. Many benchmarks judge systems by how many questions they answer correctly. A wrong answer receives a poor score, but an abstention often receives little or no credit. Because some guesses will inevitably be correct, a model that answers aggressively can outperform a model that abstains frequently. [arXiv]arxiv.orgarXiv Why Language Models HallucinatearXiv Why Language Models Hallucinate
This creates a subtle but powerful feedback loop:
- Models that answer more questions often achieve higher benchmark scores.
- Higher benchmark scores influence research priorities, rankings, and model development.
- Training methods evolve to improve those scores.
- Behaviour that favours answering becomes reinforced.
Researchers behind the paper Why Language Models Hallucinate argue that this incentive structure helps explain why hallucinations persist even as models become more capable. In their view, many systems are effectively being trained to become excellent test-takers rather than excellent judges of when knowledge is missing. [arXiv+2arXiv]arxiv.orgarXiv Why Language Models HallucinatearXiv Why Language Models Hallucinate
This also explains why a chatbot may produce a detailed response to a question that lacks sufficient information. From the model’s learned perspective, generating a plausible answer can be statistically advantageous compared with refusing to answer. [IBM]ibm.comThe hidden incentives driving AI hallucinationsWhat happens when large language models are trained to provide wrong answers instead of…

Why uncertainty is difficult for language models
Humans can often recognise when they lack knowledge and communicate that uncertainty explicitly. Language models do not possess this capability in the same way. They generate text by estimating probabilities over possible continuations rather than consulting a separate internal database of verified facts. [Wall Street Journal]wsj.comThese models generate responses using educated guesses without expressing uncertainty, often leading to errors known as hallucinations. T…
As a result, uncertainty is not automatically translated into phrases such as “I don’t know” or “I am not sure”. The model may simply continue generating the most statistically plausible sequence of words available. When evidence is sparse, this process can produce answers that sound coherent while lacking reliable factual support. [Arize AI]arize.comopenais santosh vempala explains why language models hallucinateArize AIOpenAI's Santosh Vempala Explains Why Language…Oct 24, 2025 — “Pre-training encourages hallucinations because language models…
Another challenge is calibration. A model may have internal signals indicating uncertainty, but those signals do not always appear clearly in the final response. The output can therefore sound confident even when the underlying prediction process is uncertain. [arXiv]arxiv.orgUncertainty-Based Abstention in LLMs Improves Safety and Reduces HallucinationsApril 17, 2024…
What better uncertainty signals would look like
Researchers are increasingly exploring ways to reward restraint instead of guessing. One approach is abstention: allowing a model to decline answering when confidence falls below a threshold. Studies have found that selective abstention can significantly reduce hallucinations and improve reliability, particularly when questions are unanswerable or lack sufficient context. [arXiv]arxiv.orgUncertainty-Based Abstention in LLMs Improves Safety and Reduces HallucinationsApril 17, 2024…
Several improvements have been proposed:
- Explicit uncertainty statements that indicate confidence levels rather than presenting all answers with the same tone.
- Abstention mechanisms that allow the model to refuse when evidence is insufficient.
- Evidence-linked answers that show where information came from instead of relying solely on generated text.
- Evaluation systems that reward honesty, giving credit for correctly identifying uncertainty rather than encouraging speculative answers. [OpenAI+2arXiv]OpenAIwhy language models hallucinate5 Sept 2025 —… language models hallucinate because standard training and evaluation procedures reward guessing over acknowledging unce…
Recent research efforts have also explored systems that encourage models to report possible mistakes or uncertainty after producing an answer. The goal is not merely to improve accuracy but to make uncertainty visible to users. [Tom's Guide]tomsguide.comTom's Guide Open AI is teaching AI models to 'confess' when they hallucinateRather than making models more self-aware or accurate, this method adds a secondary output—called a "ConfessionReport"—where the AI evalu…

The trade-off between usefulness and restraint
Although saying “I don’t know” sounds like an obvious solution, the issue is more complicated. A chatbot that refuses too often becomes less useful. A model that never takes informed risks may avoid some mistakes but also fail to help users when partial information could still be valuable. [Business Insider]businessinsider.comThis test-centric optimization encourages models to provide confident but potentially incorrect outputs, rather than abstaining when unsu…
Developers therefore face a balancing problem. They want systems that answer confidently when evidence is strong, acknowledge uncertainty when evidence is weak, and avoid inventing information when evidence is absent. Achieving that balance requires changes not only to model training but also to the benchmarks and reward systems used to judge success. [arXiv+2OpenAI]arxiv.orgarXiv Why Language Models HallucinatearXiv Why Language Models Hallucinate
The central lesson is that chatbot guessing is not primarily a personality trait or design quirk. It emerges from incentives. When answering is rewarded more than admitting uncertainty, models learn to answer. When uncertainty is recognised and rewarded appropriately, models become more willing to say what users sometimes most need to hear: “I don’t know.” [OpenAI+2arXiv]OpenAIwhy language models hallucinate5 Sept 2025 —… language models hallucinate because standard training and evaluation procedures reward guessing over acknowledging unce…
Amazon book picks
Further Reading
Books and field guides related to Why AI guesses instead of admitting uncertainty. Use these as the next step if you want deeper reading beyond the article.
Co-Intelligence
Discusses practical ways to evaluate and supervise AI-generated answers.
Hands-On Large Language Models
Explains how language models generate outputs and where errors emerge.
The AI Revolution in Medicine
Helps readers understand why AI systems can sound confident despite imperfect knowledge.
Build a Large Language Model (From Scratch)
Shows the prediction mechanisms that encourage answer generation over abstention.
eBay marketplace picks
Marketplace Samples
Live-tested eBay searches with available results related to this page.


Related search
AI safety poster
Open a targeted eBay search for items related to this topic.
Browse eBay
Related search
artificial intelligence poster
Open a targeted eBay search for items related to this topic.
Browse eBay
Related search
machine learning poster
Open a targeted eBay search for items related to this topic.
Browse eBayEndnotes
-
Source: OpenAI
Title: why language models hallucinate
Link: https://openai.com/index/why-language-models-hallucinate/Source snippet
5 Sept 2025 —... language models hallucinate because standard training and evaluation procedures reward guessing over acknowledging unce...
-
Source: arxiv.org
Title: arXiv Why Language Models Hallucinate
Link: https://arxiv.org/abs/2509.04664 -
Source: arxiv.org
Link: https://arxiv.org/html/2509.04664v1Source snippet
Why Language Models Hallucinate4 Sept 2025 — We argue that language models hallucinate because the training and evaluation procedures rew...
-
Source: arize.com
Title: openais santosh vempala explains why language models hallucinate
Link: https://arize.com/blog/openais-santosh-vempala-explains-why-language-models-hallucinate/Source snippet
Arize AIOpenAI's Santosh Vempala Explains Why Language...Oct 24, 2025 — “Pre-training encourages hallucinations because language models...
-
Source: cdn.openai.com
Title: why language models hallucinate
Link: https://cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdfSource snippet
OpenAI CDNWhy Language Models Hallucinateby AT Kalai · 2025 · Cited by 356 — When uncertain, students may guess on multiple-choice exams...
-
Source: ibm.com
Link: https://www.ibm.com/think/news/hidden-incentives-driving-ai-hallucinationsSource snippet
The hidden incentives driving AI hallucinationsWhat happens when large language models are trained to provide [wrong answers]({{ 'wrong-answers/' | relative_url }}) instead of...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2404.10960Source snippet
Uncertainty-Based Abstention in LLMs Improves Safety and Reduces HallucinationsApril 17, 2024...
Published: April 17, 2024
-
Source: arxiv.org
Link: https://arxiv.org/pdf/2509.04664Source snippet
Like students facing hard exam questions, large language models sometimes guess when uncertain, producing plausible yet incorrect...Read...
-
Source: community.openai.com
Title: why language models hallucinate openai research paper
Link: https://community.openai.com/t/why-language-models-hallucinate-openai-research-paper/1356581Source snippet
Models... language models hallucinate because standard training and evaluation procedures reward guessing over acknowledging uncertainty...
-
Source: wsj.com
Link: https://www.wsj.com/tech/ai/ai-halluciation-answers-i-dont-know-738bde07Source snippet
These models generate responses using educated guesses without expressing uncertainty, often leading to errors known as hallucinations. T...
-
Source: businessinsider.com
Link: https://www.businessinsider.com/why-ai-chatbots-hallucinate-openai-chatgpt-anthropic-claude-2025-9Source snippet
This test-centric optimization encourages models to provide confident but potentially incorrect outputs, rather than abstaining when unsu...
-
Source: euronews.com
Title: Why do AI models make things up or hallucinate?
Link: https://www.euronews.com/next/2025/09/09/why-do-ai-models-make-things-up-or-hallucinate-openai-says-it-has-the-answer-and-how-to-prSource snippet
OpenAI...9 Sept 2025 — The reason hallucinations continue is because LLMs are “optimised to be good test-takers and guessing when uncert...
-
Source: livescience.com
Title: Live Science AI hallucinates more frequently as it gets more advanced
Link: https://www.livescience.com/technology/artificial-intelligence/ai-hallucinates-more-frequently-as-it-gets-more-advanced-is-there-any-way-to-stop-it-from-happening-and-should-we-even-trySource snippet
OpenAI's latest reasoning models, o3 and o4-mini, showed higher hallucination rates than earlier versions, sparking concerns about the re...
-
Source: tomsguide.com
Title: Tom’s Guide Open AI is teaching AI models to ‘confess’ when they hallucinate
Link: https://www.tomsguide.com/ai/chatgpt/openai-is-teaching-ai-models-to-confess-when-they-hallucinate-heres-what-that-actually-meansSource snippet
Rather than making models more self-aware or accurate, this method adds a secondary output—called a "ConfessionReport"—where the AI evalu...
-
Source: computerworld.com
Link: https://www.computerworld.com/article/4059383/openai-admits-ai-hallucinations-are-mathematically-inevitable-not-just-engineering-flaws.htmlSource snippet
OpenAI admits AI hallucinations are mathematically...18 Sept 2025 — “We argue that language models hallucinate because the training and...
-
Source: reddit.com
Title: Why Language Models Hallucinate
Link: https://www.reddit.com/r/MachineLearning/comments/1namvsk/why_language_models_hallucinate_openai_pseudo/Source snippet
OpenAi pseudo paperEffectively the problem is that “guessing, even if not confident” yields better results at benchmarks than saying “I d...
-
Source: facebook.com
Link: https://www.facebook.com/asthait/posts/is-your-ai-hallucinatinggood-news-openais-latest-research-suggests-theyve-finall/1186833133467666/Source snippet
OpenAI's latest research suggests they...Current benchmarks reward AI for guessing wildly rather than admitting uncertainty, much like a...
-
Source: thealgorithmicbridge.com
Title: openai researchers have discovered
Link: https://www.thealgorithmicbridge.com/p/openai-researchers-have-discoveredSource snippet
language models hallucinate because standard training and evaluation procedures reward guessing over acknowledging uncertainty.Read more...
-
Source: galileo.ai
Title: why language models hallucinate
Link: https://galileo.ai/blog/why-language-models-hallucinateSource snippet
Understanding Why Language Models Hallucinate?Sep 8, 2025 — A recent paper from OpenAI "Why Language Models Hallucinate" claims to prove...
Additional References
-
Source: news.ycombinator.com
Link: https://news.ycombinator.com/item?id=45147385Source snippet
language models hallucinatelanguage models can be trained to abstain when uncertain, by changing how rewards are set up. Incentives curre...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/zainhas_new-paper-from-openai-why-llms-hallucinate-activity-7369831862451531776-dY1nSource snippet
New paper from OpenAI: "Why LLMs Hallucinate"We argue that language models hallucinate because the training and evaluation procedures rew...
-
Source: reddit.com
Link: https://www.reddit.com/r/singularity/comments/1n9fued/new_research_from_openai_why_language_models/Source snippet
New research from OpenAI: "Why language models...Claim: Hallucinations are inevitable. Finding: They are not, because language models ca...
-
Source: medium.com
Link: https://medium.com/%40markus_brinsa/why-ai-models-always-answer-even-when-they-shouldnt-e95081e3f46bSource snippet
Why AI Models Always Answer — Even When They Shouldn'tModern AI chatbots and large language models (LLMs) almost never admit “I don't kno...
-
Source: lifewire.com
Link: https://www.lifewire.com/ai-chatbot-hallucinations-7643422Source snippet
AI's hallucinations are not indicative of sentience but are due to the complexities in training and fine-tuning language models with dive...
-
Source: sawantvishwajeet729.medium.com
Link: https://sawantvishwajeet729.medium.com/understanding-why-language-models-hallucinate-a-deep-dive-into-openais-latest-research-a5ccea95a327Source snippet
Why Language Models Hallucinate: A Deep...The paper demonstrates that hallucinations aren't mysterious artifacts — they emerge naturally...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/haythamassem_why-language-models-hallucinatepdf-activity-7370201125955997697–izi -
Source: youtube.com
Link: http://www.youtube.com/watch?v=qhCZsYufxqkSource snippet
"An explanation of the “illusion of thinking” paper re: LLMs.[http://www.youtube.com/watch?v=T-SP_z_4-e0..."](http://www.youtube.com/watch?v=T-SP_z_4-e0...")...
-
Source: linkedin.com
Title: Why don’t AI models just say “I don’t know”?
Link: https://www.linkedin.com/posts/brahim-guaali_why-dont-ai-models-just-say-i-dont-know-activity-7371955112908455936-RkP2Source snippet
Brahim GuaaliBecause current training and evaluation often reward guessing instead of admitting uncertainty. Accuracy-only benchmarks p...
-
Source: reddit.com
Link: https://www.reddit.com/r/ArtificialInteligence/comments/1qpd2qg/why_ai_chatbots_guess_instead_of_saying_i_dont/Source snippet
arly doesn’t know the answer, it still gives you one instead of...
Topic Tree