Within Deep Learning
What makes attention layers different?
Transformer attention layers let models connect words, patches or tokens directly, making deep learning work differently from older sequence networks.
On this page
- Why recurrence was not the only way to handle sequences
- How attention lets tokens exchange information
- Why transformers still belong to deep learning
Page outline Jump by section
Introduction
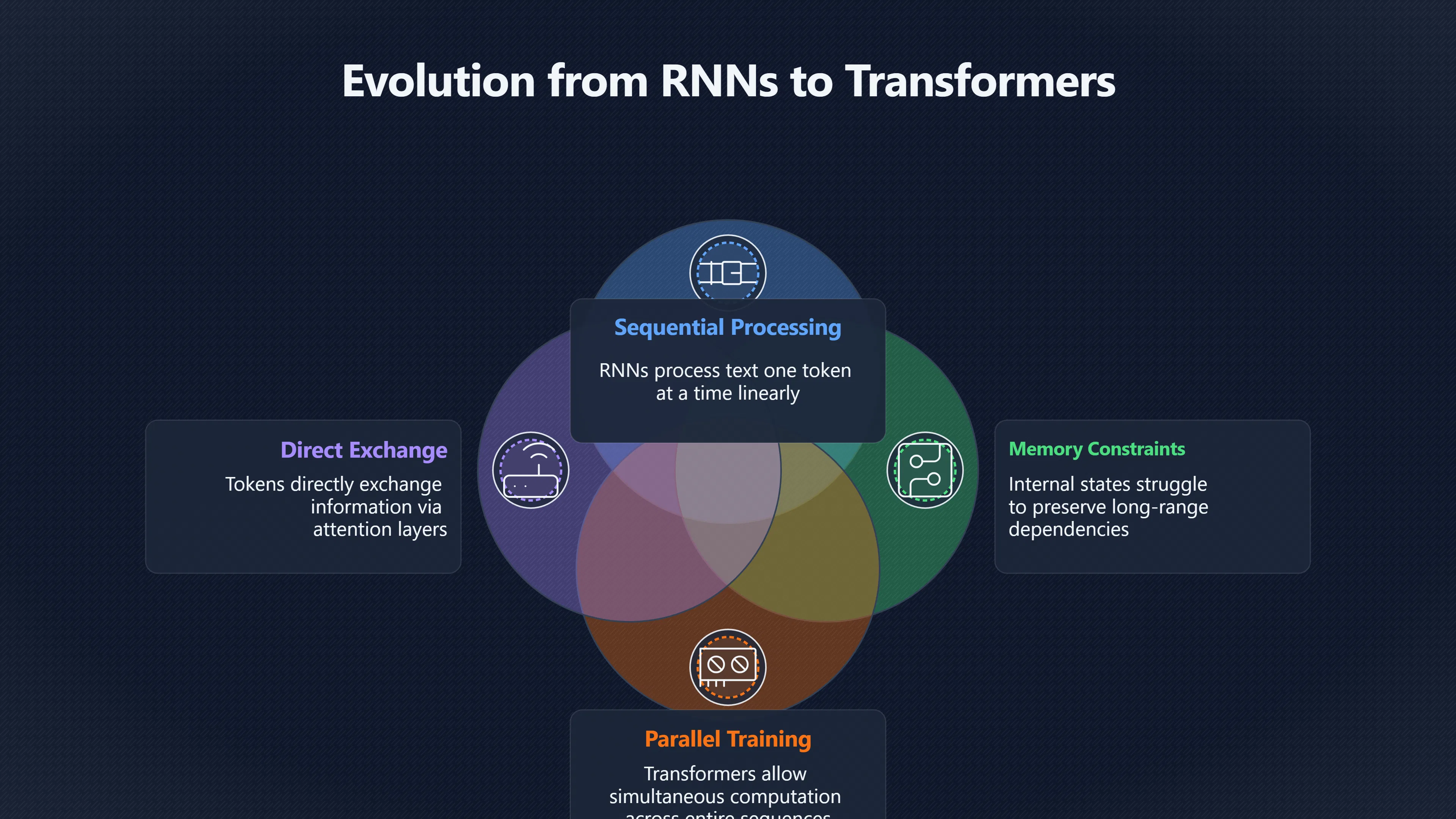
Attention layers changed language models by altering how information moves through a neural network. Earlier sequence models, especially recurrent neural networks (RNNs) and long short-term memory networks (LSTMs), processed text one step at a time. Attention-based transformers instead allow every token in a sequence to directly examine and exchange information with other relevant tokens. This shift made training far more parallelisable, improved the handling of long-range relationships in text, and enabled the scaling that produced modern large language models. The result was not merely a performance improvement but a change in the basic mechanism used to represent language. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…

What makes attention layers different?
Why recurrence was not the only way to handle sequences
Before transformers, language models usually relied on recurrence. A recurrent network reads text token by token, carrying forward an internal state that acts as a compressed memory of everything seen so far. This approach works, but it creates two important constraints.
First, processing is inherently sequential. A model cannot fully process the tenth word until it has processed the ninth. That limits the amount of parallel computation available during training. Second, information from distant parts of a sentence can become harder to preserve as the sequence grows longer. Although LSTMs improved this problem, learning very long-range dependencies remained challenging. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
The 2017 transformer paper challenged the assumption that recurrence was necessary. Its authors proposed an architecture built entirely around attention mechanisms, removing both recurrent and convolutional sequence processing. On major machine-translation benchmarks, the new design achieved state-of-the-art results while requiring substantially less training time and offering much greater parallelisation. [arXiv+2NeurIPS Papers]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
This was an important piece of evidence. The success of transformers showed that a language model could understand sequences without marching through them one position at a time.
How attention lets tokens exchange information
An attention layer allows each token to examine other tokens in the same sequence and decide which ones matter most for the current computation. Instead of relying on a single compressed memory passed forward through time, information can travel directly between relevant positions. [Wikipedia]WikipediaAttention Is All You NeedAttention Is All You Need
Consider the sentence:
“The trophy did not fit into the suitcase because it was too small.”
Understanding the word “it” requires determining whether it refers to the trophy or the suitcase. In an attention-based model, the representation of “it” can directly incorporate information from both nouns and assign more weight to whichever one best matches the context. The connection does not need to pass through every intermediate word. [Wikipedia]WikipediaAttention Is All You NeedAttention Is All You Need
This mechanism is called self-attention because the sequence attends to itself. Each token produces signals that help determine:
- which other tokens are relevant;
- how strongly they should influence the current token;
- how the resulting information should be combined.
Because every token can interact with many others simultaneously, the model can capture relationships across an entire sentence or document more efficiently than many earlier architectures. [Wikipedia]WikipediaAttention Is All You NeedAttention Is All You Need

Why multiple attention heads matter
Transformers do not use a single attention calculation. Instead, they employ multiple attention heads operating in parallel. Each head can learn a different pattern of relationships.
One head may focus on grammatical agreement between subjects and verbs. Another may focus on references between pronouns and nouns. A third may specialise in nearby context while another tracks distant context. These specialised views are then combined into a richer representation. [Wikipedia]WikipediaAttention Is All You NeedAttention Is All You Need
The importance of this design is not that engineers manually assign these roles. Rather, the heads learn useful patterns during training. The model discovers for itself which relationships improve prediction accuracy.
How attention changed language-model capability
The most immediate impact was scale. Because attention-based transformers can process many positions in parallel, they align well with modern graphics processors and specialised AI hardware. Researchers could train larger models on larger datasets more efficiently than with strongly sequential architectures. [arXiv+2Wikipedia]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
This scaling produced several practical effects:
- Better handling of long-range context.
- Stronger language understanding across diverse tasks.
- More effective transfer learning from large pre-training corpora.
- The emergence of foundation models and large language models. [ibm.com]ibm.comessing vast amounts of text data…
The transformer architecture introduced in 2017 became the basis for systems such as BERT, GPT-family models, and many later multimodal systems. Although these models differ in details, they share the core idea that attention layers are the primary mechanism for exchanging information between tokens. [Wikipedia+2Hugging Face]WikipediaAttention Is All You NeedAttention Is All You Need
An important historical point is that attention did not merely improve machine translation, the original target of the transformer paper. Researchers quickly found that the same mechanism generalised to question answering, summarisation, text generation, reasoning tasks, and eventually systems that combine language with images, audio, and other modalities. [Wikipedia]WikipediaAttention Is All You NeedAttention Is All You Need
Why transformers still belong to deep learning
The success of attention sometimes creates a misconception that transformers replaced deep learning. In reality, transformers are a form of deep learning.
A transformer still consists of many stacked learned layers. Each layer transforms numerical representations into more useful representations for the next layer. Attention changes the nature of those transformations, but the overall principle remains the same: a deep hierarchy of learned representations built through optimisation on large datasets. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
Modern language models therefore remain deep neural networks. The difference is that their most important layer type is often self-attention rather than recurrence or convolution. Stacking many attention-based layers allows information to be repeatedly refined, enabling increasingly abstract representations of meaning, context, and relationships within text. [Wikipedia]WikipediaAttention Is All You NeedAttention Is All You Need
The remaining trade-off
Attention transformed language modelling, but it introduced new challenges. Standard self-attention requires computation that grows rapidly as sequences become longer, creating memory and cost pressures. Researchers have responded with variants such as sparse attention, linear attention, and long-context transformer designs that reduce these costs while preserving the benefits of token-to-token communication. [arXiv+2arXiv]arxiv.orgarXiv Longformer: The Long-Document TransformerLongformer: The Long-Document TransformerApril 10, 2020…
Even so, the central idea remains unchanged. The breakthrough was recognising that understanding language does not require processing text strictly in order. By allowing tokens to directly exchange information through learned attention patterns, transformers changed both the architecture of language models and the practical trajectory of modern artificial intelligence. [arXiv+2Google Research]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…

Amazon book picks
Further Reading
Books and field guides related to What makes attention layers different?. Use these as the next step if you want deeper reading beyond the article.
Natural Language Processing with Transformers
Directly explains attention mechanisms and transformer architectures.
Build a Large Language Model (From Scratch)
Explains self-attention and transformer internals in detail.
Deep Learning
Rating: 3.5/5 from 6 Google Books ratings
Provides the neural-network foundations behind attention layers.
Artificial Intelligence
Rating: 4.5/5 from 10 Google Books ratings
Places deep learning within the wider AI landscape.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: arxiv.org
Title: arXiv Attention Is All You Need
Link: https://arxiv.org/abs/1706.03762Source snippet
Attention Is All You NeedJune 12, 2017...
Published: June 12, 2017
-
Source: arxiv.org
Link: https://arxiv.org/html/1706.03762v7Source snippet
Attention Is All You NeedWe propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing...
-
Source: papers.neurips.cc
Title: 7181 attention is all you need
Link: https://papers.neurips.cc/paper/7181-attention-is-all-you-need.pdfSource snippet
NeurIPS PapersAttention is All you Needby A Vaswani · Cited by 251460 — We propose a new simple network architecture, the Transformer, ba...
-
Source: Wikipedia
Title: Attention Is All You Need
Link: https://en.wikipedia.org/wiki/Attention_Is_All_You_Need -
Source: Wikipedia
Title: Transformer (deep learning)
Link: https://en.wikipedia.org/wiki/Transformer_%28deep_learning%29Source snippet
Transformer (deep learning)In deep learning, the transformer is a family of artificial neural network architectures based on the multi...
-
Source: arxiv.org
Title: arXiv Longformer: The Long-Document Transformer
Link: https://arxiv.org/abs/2004.05150Source snippet
Longformer: The Long-Document TransformerApril 10, 2020...
Published: April 10, 2020
-
Source: arxiv.org
Link: https://arxiv.org/abs/2310.12442 -
Source: arxiv.org
Link: https://arxiv.org/html/2507.19595v3Source snippet
Efficient Attention Mechanisms for Large Language Models7 Feb 2026 — The results in the paper show that these models can often match or e...
-
Source: Wikipedia
Link: https://en.wikipedia.org/wiki/TransformerSource snippet
TransformerA transformer is a passive component that transfers electrical energy from one electrical circuit to another circuit, or mu...
-
Source: research.google
Link: https://research.google/pubs/attention-is-all-you-need/Source snippet
Google ResearchAttention is All You NeedWe propose a new simple network architecture, the Transformer, based solely on attention mechanis...
-
Source: huggingface.co
Title: attention is all you need
Link: https://huggingface.co/blog/Esmail-AGumaan/attention-is-all-you-needSource snippet
TransformersJul 2, 2024 — the Transformer Neural Network (TNN) introduced a breakthrough solution called "Self-Attention" in the paper "A...
-
Source: merriam-webster.com
Link: https://www.merriam-webster.com/dictionary/theSource snippet
a: used as a function word to indicate that a following noun or noun equivalent is definite or has been previously specified by context...
-
Source: ibm.com
Link: https://www.ibm.com/think/topics/large-language-modelsSource snippet
essing vast amounts of text data...
Additional References
-
Source: poloclub.github.io
Link: https://poloclub.github.io/transformer-explainer/Source snippet
LLM Transformer Model Visually ExplainedWhat is a Transformer? Transformer is a neural network architecture that has fundamentally change...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/understanding-groundbreaking-attention-all-you-need-research-disansa-becncSource snippet
Understanding the Groundbreaking 'Attention Is All You...The Goal is to reduce sequential computation, which forms the foundations of: E...
-
Source: techradar.com
Link: https://www.techradar.com/pro/what-are-transformer-modelsSource snippet
Transformers utilize a structure composed of encoders, decoders, and a dynamic attention mechanism, allowing more efficient handling of l...
-
Source: electronics-tutorials.ws
Link: https://www.electronics-tutorials.ws/transformer/transformer-basics.htmlSource snippet
Transformer Basics and Transformer PrinciplesTransformers are electrical devices consisting of two or more coils of wire used to transfer...
-
Source: pub.towardsai.net
Link: https://pub.towardsai.net/attention-is-all-you-need-a-deep-dive-into-the-revolutionary-transformer-architecture-52734fb355dcSource snippet
Deep Dive into the Revolutionary Transformer Architecture10 Apr 2025 — The Transformer changed all that by introducing an architecture ba...
-
Source: medium.com
Link: https://medium.com/swlh/large-language-models-transformer-architecture-the-basics-2bdd84a6db17 -
Source: linkedin.com
Link: https://www.linkedin.com/pulse/transformers-simplified-guide-attention-all-you-need-moiz-asghar-zdvmcSource snippet
Transformers Simplified: A Guide to Attention Is All You NeedThe self-attention mechanism allows a model to understand the relationships...
-
Source: amazon.com
Link: https://www.amazon.com/electrical-transformer/s?k=electrical+transformerSource snippet
Electrical TransformerDiscover reliable electrical transformers for home and industrial use. Shop top-rated options with advanced protect...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/why-attention-all-you-need-deep-dive-transformer-model-padhy-cijwcSource snippet
how the Transformer is designed, and what makes it more efficient and scalable...Read more...
-
Source: reddit.com
Link: https://www.reddit.com/r/MachineLearning/comments/qidpqx/d_how_to_truly_understand_attention_mechanism_in/Source snippet
However it is not that easy to fully understand, and in my opinion, somewhat unintuitive...
Topic Tree