Within Transformers
Why did Transformers scale so well?
Transformers mattered because attention could be trained across many tokens at once, making larger models fit the economics of modern hardware.
On this page
- The bottleneck in recurrent sequence models
- How parallel attention changed training speed
- Why scaling became a practical strategy
Page outline Jump by section
Introduction
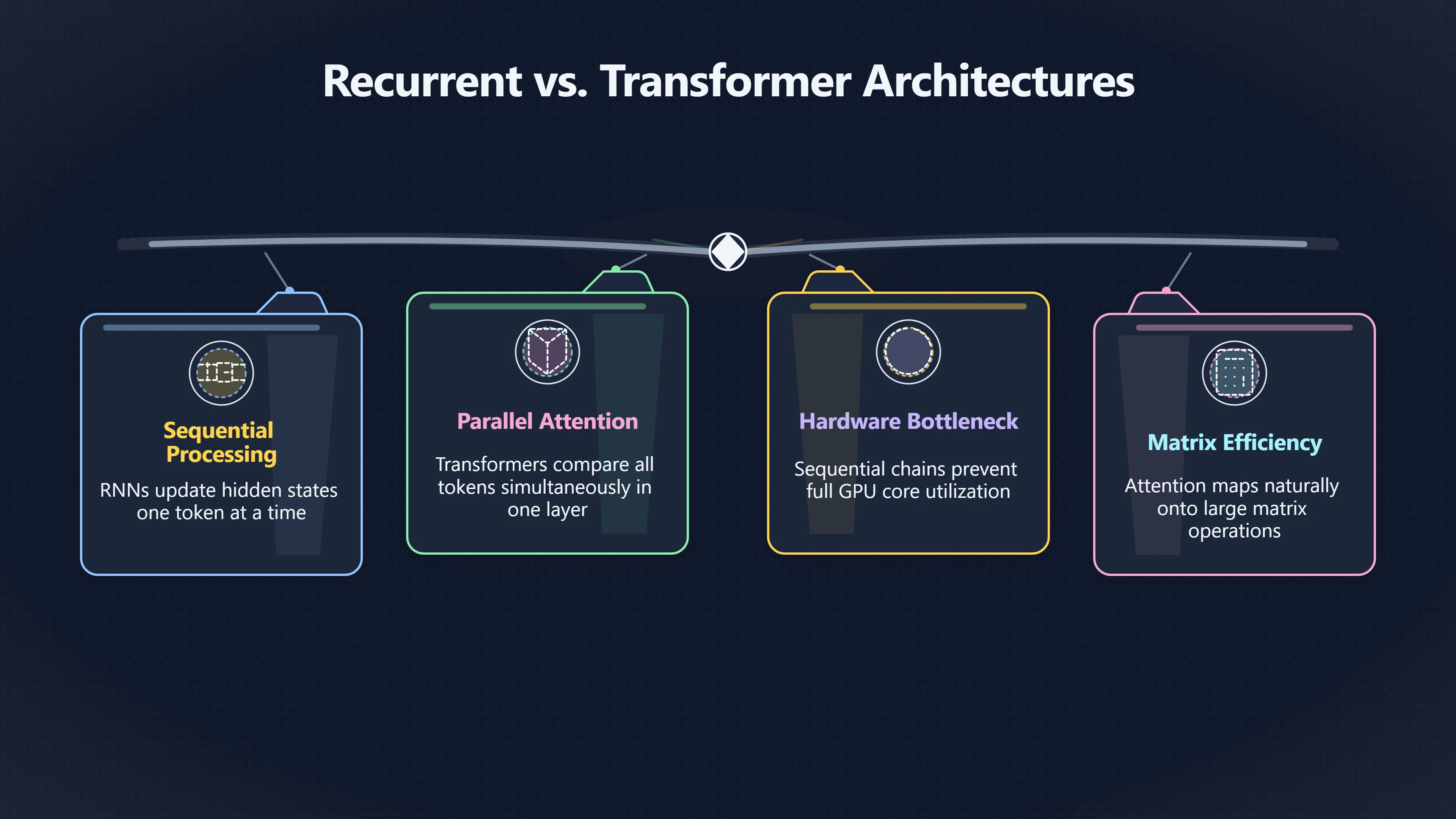
One of the most important reasons Transformers transformed artificial intelligence was not merely that they produced better results, but that they fit the economics of modern computing. Earlier sequence models such as recurrent neural networks (RNNs) and long short-term memory networks (LSTMs) processed information one step at a time. Transformers replaced that sequential bottleneck with attention mechanisms that could process many tokens simultaneously. This made training dramatically easier to distribute across graphics processing units (GPUs) and other specialised AI hardware, allowing researchers to train much larger models on much larger datasets. The result was a shift from improving individual architectures to scaling them: adding more data, more parameters, and more computing power became a practical path to better performance. [arXiv+2NeurIPS Papers]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…

The bottleneck in recurrent sequence models
Before Transformers, state-of-the-art language systems were usually based on recurrent architectures. These models maintained a hidden state that was updated after each token. The representation for word 50 depended on the computation performed for word 49, which depended on word 48, and so on.
This design created a fundamental limitation. Even if a machine contained thousands of processing cores, the model could not fully exploit them because many calculations had to wait for previous calculations to finish. GPUs are exceptionally good at performing large numbers of matrix operations simultaneously, but recurrent models forced much of the work into a sequential chain. [arXiv+2Michał Chromiak's blog]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
Researchers could still increase throughput by processing multiple training examples in parallel within a batch, but the computation inside each sequence remained constrained by time-step dependencies. As datasets grew and models became larger, this sequential nature increasingly became a practical obstacle rather than merely a theoretical inconvenience. [Reddit]reddit.comIt's commonly said that transformers are more parallelizableWhy is it said that the transformer is more parallelizable…June 15, 2023 — The parallelization of transformers and RNNs (Recurre…
The problem was especially visible in machine translation, one of the leading AI benchmarks of the mid-2010s. Longer sentences required longer chains of sequential operations, increasing training time and making it difficult to utilise hardware efficiently. The architecture itself limited how much additional computing power could accelerate training. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
How parallel attention changed training speed
The Transformer introduced a different approach. Instead of updating a hidden state one token at a time, self-attention allows every token in a sequence to compare itself with every other token during the same layer computation.
Because these comparisons can be expressed as large matrix operations, they map naturally onto GPU hardware. A model can process an entire sequence in parallel during training rather than stepping through it word by word. The architecture therefore removes the recurrence that had constrained previous systems. [arXiv+2NeurIPS Papers]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
This was not simply an engineering convenience. In the original Transformer paper, the authors highlighted that their architecture was both “more parallelizable” and required substantially less training time than leading recurrent alternatives. On a major English–French translation benchmark, they reported state-of-the-art performance after training for 3.5 days on eight GPUs, representing only a fraction of the training cost associated with competing approaches at the time. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
Another important design choice was multi-head attention. Different attention heads can operate independently, allowing the model to perform many relationship calculations simultaneously. This further increased the degree to which computations could be packaged into large, efficient tensor operations suited to accelerator hardware. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
Historically, this represented a significant shift in thinking. Much of the field had assumed that language models needed recurrence to capture sequential structure. The Transformer demonstrated that attention alone could preserve strong language performance while eliminating the main obstacle to large-scale parallel training. [Wikipedia]WikipediaTransformer (deep learningTransformer (deep learning

Why scaling became a practical strategy
Once training could be parallelised effectively, a new possibility emerged: simply making models bigger.
In earlier generations of AI, increasing model size often produced diminishing practical returns because training times became prohibitive. With Transformers, additional hardware could be used much more effectively. Training could be distributed across larger GPU clusters and, later, across specialised systems such as tensor processing units (TPUs). [Introl+2IT Pro]introl.comTransformer Architecture: How Attention Changed AI | Introl Blog2 May 2025 — Transformers enable far more parallelization by discar…
This changed research incentives. Instead of relying primarily on architectural tricks, researchers discovered that increasing three factors together—model parameters, training data, and compute—could consistently improve performance. The Transformer architecture was unusually well suited to this strategy because its core operations were already designed around highly parallel matrix calculations. [Wikipedia+2Introl]WikipediaAttention Is All You NeedThis ensures that the operations necessary for training can be accelerated on a GPU, allowing both faster traini…
The effects became visible across the industry. Models such as BERT, GPT, PaLM, Gemini and many others were built on Transformer foundations and trained on hardware clusters containing thousands of accelerators. Such systems would have been far more difficult and expensive to train had they relied on the sequential processing characteristics of traditional recurrent networks. [Wikipedia+2TechRadar]WikipediaAttention Is All You NeedThis ensures that the operations necessary for training can be accelerated on a GPU, allowing both faster traini…
Researchers later developed additional forms of parallelism—such as tensor, pipeline and sequence parallelism—to spread Transformer workloads across even larger hardware systems. These methods extended the architecture’s scalability and helped push model sizes and context lengths far beyond what was practical in the early Transformer era. [arXiv]arxiv.orgarXiv Sequence Parallelism: Long Sequence Training from System PerspectiveSequence Parallelism: Long Sequence Training from System PerspectiveMay 26, 2021…
Parallelism was not a free lunch
The Transformer’s success does not mean recurrence was inherently flawed. In fact, recent research has revisited recurrent and state-space architectures in an attempt to recover some of their efficiency advantages while retaining the scalability benefits that made Transformers successful. [arXiv+2OpenReview]arxiv.orgWere RNNs All We Needed?Oct 2, 2024 — The scalability limitations of Transformers regarding sequence length have renewed interest in…
Transformers also introduced their own costs. Self-attention requires computations that grow rapidly with sequence length, creating memory and processing challenges for very long inputs. Considerable engineering effort has gone into making attention more efficient. [arXiv]arxiv.orgarXiv Sequence Parallelism: Long Sequence Training from System PerspectiveSequence Parallelism: Long Sequence Training from System PerspectiveMay 26, 2021…
Nevertheless, the historical significance of the Transformer remains clear. Its breakthrough was not only that attention improved language modelling, but that attention removed a major barrier to parallel computation. By aligning AI architectures with the strengths of GPUs and specialised accelerators, Transformers turned scaling from an aspiration into a practical engineering strategy. That compatibility with modern hardware is a central reason why large AI models became feasible in the first place. [TechRadar+3arXiv+3NeurIPS Papers]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…

Amazon book picks
Further Reading
Books and field guides related to Why did Transformers scale so well?. Use these as the next step if you want deeper reading beyond the article.
Hands-On Large Language Models
Explains why transformer architectures scaled successfully.
Natural Language Processing with Transformers
Shows practical transformer training and scaling.
Deep Learning
Rating: 3.5/5 from 6 Google Books ratings
Provides the neural-network foundations behind modern architectures, including attention-era systems.
Transformers for Machine Learning
Discusses architecture, scaling, training efficiency, and attention.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.


Endnotes
-
Source: arxiv.org
Title: arXiv Attention Is All You Need
Link: https://arxiv.org/abs/1706.03762Source snippet
Attention Is All You NeedJune 12, 2017...
Published: June 12, 2017
-
Source: papers.neurips.cc
Title: 7181 attention is all you need
Link: https://papers.neurips.cc/paper/7181-attention-is-all-you-need.pdfSource snippet
NeurIPS PapersAttention is All you Needby A Vaswani · Cited by 247770 — Experiments on two machine translation tasks show these models to...
-
Source: Wikipedia
Link: https://en.wikipedia.org/wiki/Attention_Is_All_You_NeedSource snippet
Attention Is All You NeedThis ensures that the operations necessary for training can be accelerated on a GPU, allowing both faster traini...
-
Source: Wikipedia
Title: Transformer ([deep learning]({{ ‘deep-learning/’ | relative_url }}))
Link: https://en.wikipedia.org/wiki/Transformer_%28deep_learning%29 -
Source: reddit.com
Title: It’s commonly said that transformers are more parallelizable
Link: https://www.reddit.com/r/MLQuestions/comments/14aedwk/why_is_it_said_that_the_transformer_is_more/Source snippet
Why is it said that the transformer is more parallelizable...June 15, 2023 — The parallelization of transformers and RNNs (Recurre...
Published: June 15, 2023
-
Source: introl.com
Link: https://introl.com/blog/the-transformer-revolution-how-attention-is-all-you-need-reshaped-modern-aiSource snippet
Transformer Architecture: How Attention Changed AI | Introl Blog2 May 2025 — Transformers enable far more parallelization by discar...
Published: May 2025
-
Source: techradar.com
Link: https://www.techradar.com/pro/what-are-transformer-modelsSource snippet
Transformers utilize a structure composed of encoders, decoders, and a dynamic attention mechanism, allowing more efficient handling of l...
-
Source: arxiv.org
Title: arXiv Sequence Parallelism: Long Sequence Training from System Perspective
Link: https://arxiv.org/abs/2105.13120Source snippet
Sequence Parallelism: Long Sequence Training from System PerspectiveMay 26, 2021...
Published: May 26, 2021
-
Source: arxiv.org
Link: https://arxiv.org/html/2410.01201v1Source snippet
Were RNNs All We Needed?Oct 2, 2024 — The scalability limitations of Transformers regarding sequence length have renewed interest in...
-
Source: openreview.net
Link: https://openreview.net/forum?id=GrmFFxGnORSource snippet
Were RNNs All We Needed?by L Feng · Cited by 98 — The paper investigates simplified versions of traditional recurrent neural networks (RN...
-
Source: arxiv.org
Title: arXiv RWKV: Reinventing RNNs for the Transformer Era
Link: https://arxiv.org/abs/2305.13048 -
Source: Wikipedia
Link: https://en.wikipedia.org/wiki/TransformerSource snippet
TransformerA transformer is a passive component that transfers electrical energy from one electrical circuit to another circuit, or mu...
-
Source: mchromiak.github.io
Title: Transformer Attention is all you need
Link: https://mchromiak.github.io/articles/2017/Sep/12/Transformer-Attention-is-all-you-need/Source snippet
This in turn leads to...Read more...
-
Source: itpro.com
Link: https://www.itpro.com/infrastructure/what-is-a-tensor-processing-unit-tpuSource snippet
TPUs are designed specifically to accelerate [machine learning]({{ 'machine-learning/' | relative_url }}) tasks, particularly large-scale training and [inference]({{ 'inference-test/' | relative_url }&#...
-
Source: smythstoys.com
Link: https://www.smythstoys.com/uk/en-gb/toys/action-figures-and-playsets/transformers/c/SM06010123
Additional References
-
Source: merriam-webster.com
Link: https://www.merriam-webster.com/dictionary/attentionSource snippet
ATTENTION Definition & Meaning7 days ago — 1. a: the act or state of applying the mind to something Our attention was on the game. You s...
-
Source: amazon.co.uk
Link: https://www.amazon.co.uk/Electrical-Transformers/s?k=Electrical+TransformersSource snippet
Electrical TransformersExplore a wide range of electrical transformers for industrial, residential, and commercial applications. Find qua...
-
Source: medium.com
Link: https://medium.com/analytics-vidhya/attention-is-all-you-need-explained-for-everyone-1349430f8f6eSource snippet
Attention Is All You Need — Explained for EveryoneThis paper introduces the Transformer architecture, which powers models such as GPT and...
-
Source: medium.com
Link: https://medium.com/%40weidagang/coffee-time-papers-attention-is-all-you-need-3c7d6bc75eabSource snippet
Coffee Time Papers: Attention Is All You NeedEfficiency: The model achieves superior results while being more parallelizable and requirin...
-
Source: se.com
Link: https://www.se.com/in/en/product-category/3600-medium-voltage-transformers/Source snippet
Medium-Voltage TransformersDiscover our range of dry-type, oil and power transformers from medium voltage up to 170kV. Our long experienc...
-
Source: electronics-tutorials.ws
Link: https://www.electronics-tutorials.ws/transformer/transformer-basics.htmlSource snippet
Transformer Basics and Transformer PrinciplesTransformers are electrical devices consisting of two or more coils of wire used to transfer...
-
Source: mouser.co.uk
Link: https://www.mouser.co.uk/c/power/transformers/?srsltid=AfmBOorvccpxPuO9o_UKS52RWhTSe-GY0lfhrm4kiz-z0eyuKInJzHJ8Source snippet
Transformers – Mouser United KingdomMouser is an authorized distributor for many transformer manufacturers including Bel, Coilcraft, Hamm...
-
Source: pub.towardsai.net
Link: https://pub.towardsai.net/attention-is-all-you-need-a-deep-dive-into-the-revolutionary-transformer-architecture-52734fb355dcSource snippet
Deep Dive into the Revolutionary Transformer ArchitectureApr 10, 2025 — This paper introduced the Transformer architecture, a novel appro...
-
Source: abhishek-reddy.medium.com
Link: https://abhishek-reddy.medium.com/how-attention-is-all-you-need-revolutionized-ai-unpacking-the-transformer-breakthrough-7564aca3cf08Source snippet
'Attention is All You Need' Revolutionized AI: Unpacking...This pivotal work introduced the transformer model, setting a new standard in...
-
Source: towardsai.net
Link: https://towardsai.net/p/machine-learning/attention-is-all-you-need-a-deep-dive-into-the-revolutionary-transformer-architectureSource snippet
A Deep Dive into the Revolutionary Transformer Architecture10 Apr 2025 — The Transformer architecture, introduced in the seminal paper “A...
Topic Tree