Within Transformers
Why can next token models do so much?
Many people first encounter artificial intelligence through chatbots, writing assistants, translation tools, or coding helpers. What makes these systems surprising is that they are often built on a remarkably simple training objective: predict the next piece of text. GPT-style models are trained to read a sequence of tokens and guess what comes next.
On this page
- Decoder only Transformers and prediction
- Pre training, prompting, and task flexibility
- What generation reveals and hides
Page outline Jump by section
Why can next-token prediction produce so many abilities?
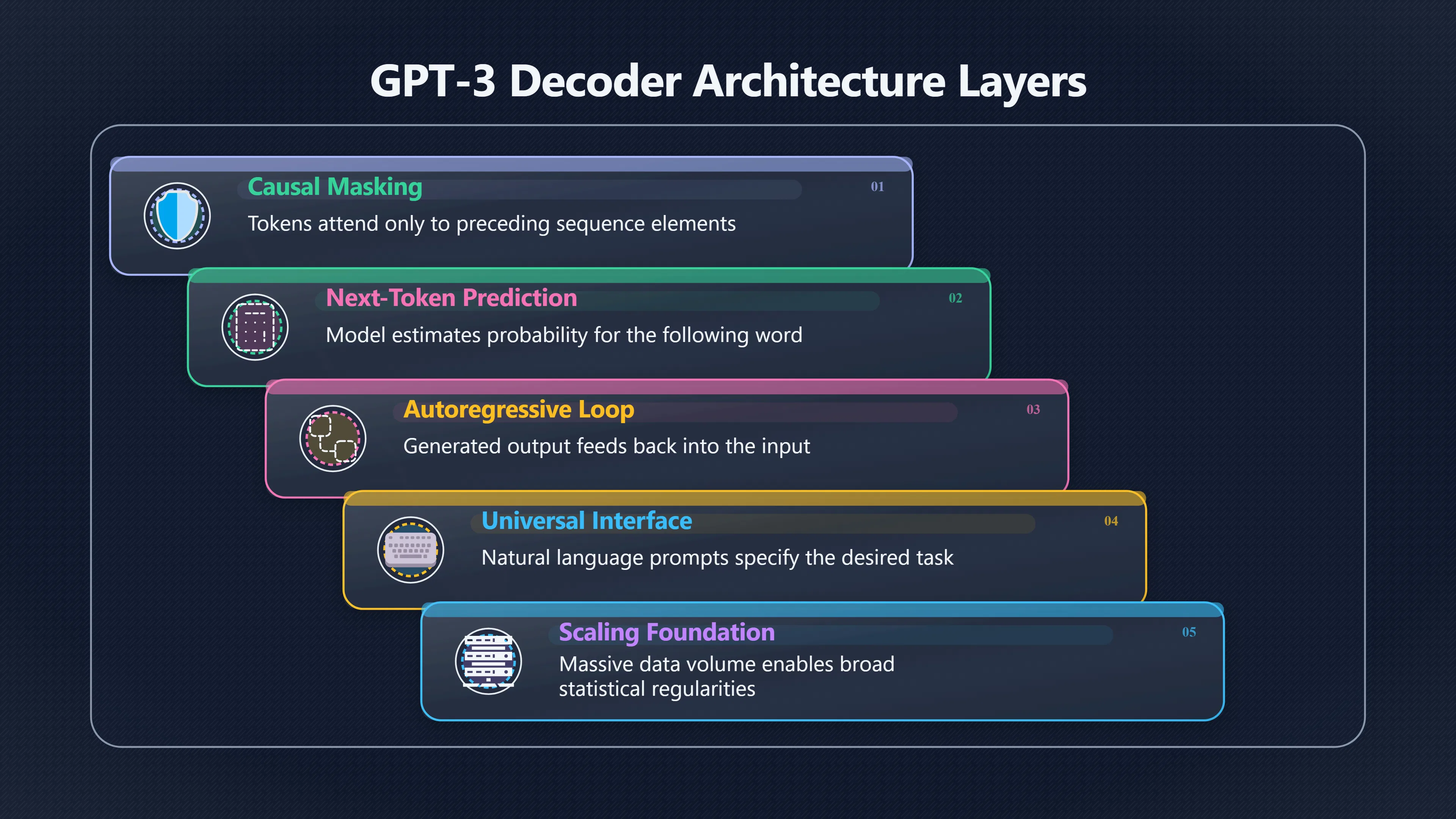
A GPT-style model is a decoder-only Transformer. Unlike the original encoder–decoder Transformer designed for translation, it uses causal or masked attention: each token can attend only to earlier tokens in the sequence. During training, the model repeatedly sees text and learns to predict the next token given everything that came before it. [arXiv+2Michael Brenndoerfer]arxiv.orgarXiv[1706.03762] Attention Is All You NeedJun 12, 2017 — We propose a new simple network architecture, the Transformer, based solely on…
 This setup creates a powerful learning signal. To predict the next word accurately, the model must absorb many patterns hidden in text:
This setup creates a powerful learning signal. To predict the next word accurately, the model must absorb many patterns hidden in text:
- Grammar and sentence structure.
- Facts and common associations.
- Styles of writing.
- Question-and-answer formats.
- Programming syntax.
- Translation correspondences between languages.
- Patterns of reasoning expressed in text.
The model is never explicitly told, “this is a translation task” or “this is a coding task”. Instead, those activities appear within the training data. Predicting the next token forces the model to model the structures that generate language in many different contexts. [arXiv]arxiv.orgarXiv Language Models are Few-Shot LearnersLanguage Models are Few-Shot LearnersMay 28, 2020…
An important consequence is that generation and understanding become closely linked. To continue text correctly, the model often needs to infer what the preceding text means. Although this is not the same as human understanding, it allows a single architecture to support many language-related activities.
Decoder-only Transformers and prediction
The decoder-only design proved particularly well suited to large-scale text generation. Because the model generates text one token at a time while conditioning on everything already written, the same mechanism can support many different outputs without changing the underlying architecture. [Michael Brenndoerfer]mbrenndoerfer.comMichael BrenndoerferDecoder Architecture: Causal Masking & Autoregressive…Jun 17, 2025 — A decoder-only model consists of a stack of t…
Consider a prompt such as:
Translate to French: “Good morning”
The model does not switch into a dedicated translation module. It simply continues the text in a way that resembles translation examples seen during training. Likewise, a prompt beginning with a programming problem encourages continuation in the style of code, while a prompt beginning with a question encourages an answer.
This flexibility comes from treating all tasks as text completion. Translation, summarisation, dialogue, classification, and coding become variations of the same operation: predict the most plausible continuation of the current context. GPT-3 demonstrated that sufficiently large autoregressive models could perform many such tasks without gradient updates or task-specific fine-tuning, relying instead on text prompts and examples supplied in the input itself. [arXiv+2NeurIPS Proceedings]arxiv.orgarXiv Language Models are Few-Shot LearnersLanguage Models are Few-Shot LearnersMay 28, 2020…
Pre-training, prompting, and task flexibility
The crucial step was pre-training at scale. GPT-style models are exposed to enormous amounts of text from books, articles, websites, code repositories, and other sources. During this stage they are not learning a specific application. They are learning broad statistical regularities about language and information. [arXiv]arxiv.orgarXiv Language Models are Few-Shot LearnersLanguage Models are Few-Shot LearnersMay 28, 2020…
Once pre-training is complete, prompting provides a way to activate different behaviours. A prompt acts as a temporary specification of the task. For example:
- A question prompt encourages question answering.
- Input-output examples encourage translation or classification.
- A partially written program encourages code completion.
- A conversation transcript encourages dialogue.
Researchers described this behaviour as zero-shot, one-shot, and few-shot learning. In zero-shot use, only an instruction is given. In one-shot or few-shot use, the prompt includes one or more examples. GPT-3 showed that larger language models became increasingly capable of adapting to new tasks through prompting alone. [arXiv+2NeurIPS Proceedings]arxiv.orgarXiv Language Models are Few-Shot LearnersLanguage Models are Few-Shot LearnersMay 28, 2020…
This phenomenon is often called in-context learning. Rather than updating its parameters during the interaction, the model uses patterns contained in the prompt itself to infer what kind of continuation is expected. Subsequent research has explored how this capability emerges and how much of it can be explained through the interaction of pre-training, memory, and pattern matching within context. [OpenReview+2ACL Anthology]openreview.netWhy In-Context Learning Models are Good Few-Shot…by S Wu · Cited by 20 — Our findings show that ICL with transformers can ef…
A useful way to think about prompting is that it turns natural language into a universal interface. Instead of creating separate systems for each task, users describe the task using text, and the model responds by continuing that text appropriately.

Why scaling mattered
Early language models could generate coherent sentences but struggled to generalise beyond narrow patterns. As model size, training data, and computation increased, researchers observed substantial improvements across a wide range of tasks. GPT-3 became influential not simply because it was larger, but because it showed that a single next-token predictor could display useful performance on translation, question answering, text generation, and other tasks without task-specific retraining. [arXiv+2NeurIPS Papers]arxiv.orgarXiv Language Models are Few-Shot LearnersLanguage Models are Few-Shot LearnersMay 28, 2020…
Researchers later described some newly appearing capabilities as “emergent abilities”, meaning behaviours that seemed absent in smaller models but became visible in larger ones. Examples included stronger reasoning performance, improved instruction following, and more effective in-context learning. However, there remains active debate about how these behaviours arise and whether they are truly emergent or the result of more gradual scaling effects combined with prompting methods. [arXiv+2OpenReview]arxiv.orgarXiv Emergent abilities of large language modelsEmergent abilities of large language modelsJune 15, 2022 — by J Wei · 2022 · Cited by 5470 — We first discuss emergent abilities in…
What is clear is that scale transformed next-token prediction from a specialised language-modelling task into a practical foundation for general-purpose text systems.
What generation reveals and hides
The success of GPT-style models can create the impression that they possess a unified understanding of the world. In reality, users observe only the generated output. The underlying process remains a sequence of probability estimates over possible next tokens. [arXiv]arxiv.orgarXiv Language Models are Few-Shot LearnersLanguage Models are Few-Shot LearnersMay 28, 2020…
This leads to both strengths and weaknesses.
Generation reveals:
- Broad knowledge acquired during pre-training.
- The ability to imitate formats and styles.
- Adaptation to instructions and examples in prompts.
- Flexible use across many language tasks. [researchgate.net]researchgate.netAre Emergent Abilities in Large Language Models just In-…Sep 4, 2023 — Large language models have exhibited emergent abilities, demons…
Generation can also hide:
- Gaps in factual knowledge.
- Uncertainty that is not always expressed explicitly.
- Failures of reasoning behind fluent language.
- Dependence on patterns learned from training data rather than genuine comprehension.
Because the model’s objective is to produce a plausible continuation, fluent output does not guarantee correctness. The same mechanism that enables creativity and flexibility can also produce confident mistakes.
The central lesson is that GPT-style systems became flexible generators not because engineers built separate modules for every task, but because large decoder-only Transformers learned an exceptionally broad predictive model of text. Once language itself became the interface, next-token prediction turned into a surprisingly general way of drafting, answering, translating, coding, and conversing. [arXiv+2NeurIPS Proceedings]arxiv.orgarXiv Language Models are Few-Shot LearnersLanguage Models are Few-Shot LearnersMay 28, 2020…

Amazon book picks
Further Reading
Books and field guides related to Why can next token models do so much?. Use these as the next step if you want deeper reading beyond the article.
Hands-On Large Language Models
Directly explains GPT-style models, transformers, pretraining, and generation.
Build a Large Language Model (From Scratch)
Shows how next-token prediction systems are built and why they work.
Natural Language Processing with Transformers
Covers transformer architectures and language model capabilities.
Deep Learning
Rating: 3.5/5 from 6 Google Books ratings
Provides theoretical foundations behind representation learning and generative models.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: arxiv.org
Title: arXiv Language Models are Few-Shot Learners
Link: https://arxiv.org/abs/2005.14165Source snippet
Language Models are Few-Shot LearnersMay 28, 2020...
Published: May 28, 2020
-
Source: arxiv.org
Link: https://arxiv.org/abs/1706.03762Source snippet
arXiv[1706.03762] Attention Is All You NeedJun 12, 2017 — We propose a new simple network architecture, the Transformer, based solely on...
-
Source: proceedings.neurips.cc
Title: 1457c0d6bfcb4967418bfb8ac142f64a Paper
Link: https://proceedings.neurips.cc/paper_files/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdfSource snippet
NeurIPS ProceedingsLanguage Models are Few-Shot Learnersby T Brown · 2020 · Cited by 74705 — We demonstrate that scaling up language mode...
-
Source: openreview.net
Link: https://openreview.net/forum?id=iLUcsecZJpSource snippet
Why In-Context Learning Models are Good Few-Shot...by S Wu · Cited by 20 — Our findings show that ICL with transformers can ef...
-
Source: arxiv.org
Title: arXiv Are Emergent Abilities in Large Language Models just In-Context Learning?
Link: https://arxiv.org/abs/2309.01809 -
Source: arxiv.org
Title: arXiv Emergent abilities of large language models
Link: https://arxiv.org/pdf/2206.07682Source snippet
Emergent abilities of large language modelsJune 15, 2022 — by J Wei · 2022 · Cited by 5470 — We first discuss emergent abilities in...
Published: June 15, 2022
-
Source: openreview.net
Link: https://openreview.net/pdf?id=yzkSU5zdwDSource snippet
Emergent Abilities of Large Language Modelsby J Wei · Cited by 5337 — Brown et al. (2020) proposed few-shot prompting, which in...
-
Source: arxiv.org
Link: https://arxiv.org/html/2503.05788v2Source snippet
Emergent Abilities in Large Language Models: A SurveySummarizes in-context learning (ICL), the capability for few-shot generalization to...
-
Source: mbrenndoerfer.com
Link: https://mbrenndoerfer.com/writing/decoder-architecture-causal-masking-autoregressive-transformersSource snippet
Michael BrenndoerferDecoder Architecture: Causal Masking & Autoregressive...Jun 17, 2025 — A decoder-only model consists of a stack of t...
-
Source: papers.nips.cc
Link: https://papers.nips.cc/paper_files/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.htmlSource snippet
Models are Few-Shot Learnersby T Brown · 2020 · Cited by 74011 — We demonstrate that scaling up language models greatly improves task-agn...
-
Source: aclanthology.org
Title: 2024.acl long.279
Link: https://aclanthology.org/2024.acl-long.279.pdfSource snippet
Are Emergent Abilities in Large Language Models just In-...by S Lu · 2024 · Cited by 202 — In-Context Learning ICL is a learning paradig...
-
Source: Wikipedia
Link: https://en.wikipedia.org/wiki/LanguageSource snippet
LanguageLanguage is a structured system of communication that consists of grammar and vocabulary. It is the primary means by which hum...
-
Source: mbrenndoerfer.com
Title: gpt 3 scale few shot in context learning
Link: https://mbrenndoerfer.com/writing/gpt-3-scale-few-shot-in-context-learningSource snippet
GPT-3: Scale, Few-Shot Learning & In-Context...Jul 19, 2025 — The paper introducing GPT-3, "Language Models are Few-Shot Learners" by Br...
Additional References
-
Source: medium.com
Link: https://medium.com/%40alejandro.itoaramendia/attention-is-all-you-need-a-complete-guide-to-transformers-8670a3f09d02Source snippet
Attention Is All You Need: A Complete Guide to TransformersAt each of these steps, the model is auto-regressive, meaning that previously...
-
Source: medium.com
Link: https://medium.com/%40qmsoqm2/auto-regressive-vs-sequence-to-sequence-d7362eda001eSource snippet
Encoder-Decoder vs. Decoder-OnlyThe straightforward answer is that the auto-regressive one only features a decoder stack (dec-only), whil...
-
Source: medium.com
Link: https://medium.com/%40akankshasinha247/few-shot-prompting-teaching-ai-with-just-a-few-examples-6819273fd6e2Source snippet
Few-Shot Prompting: Teaching AI With Just a Few ExamplesFew-shot prompting is one of the most practical and powerful prompt engineering t...
-
Source: slideshare.net
Link: https://www.slideshare.net/slideshow/llm-gpt-3-language-models-are-few-shot-learners/268660713Source snippet
LLM GPT-3: Language models are few-shot learners | PPTXThe document outlines the evolution and capabilities of the GPT language models fr...
-
Source: medium.com
Link: https://medium.com/%40manindersingh120996/hands-on-with-transformers-recreating-attention-is-all-you-need-in-pytorch-step-by-step-ecfbf3e1985bSource snippet
Recreating 'Attention Is All You Need' in PyTorch, Step by...In this blog, I'll walk you through everything I built, step by step, in Py...
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/341724146_Language_Models_are_Few-Shot_LearnersSource snippet
(PDF) Language Models are Few-Shot LearnersHere we show that scaling up language models greatly improves task-agnostic, few-shot performa...
-
Source: reddit.com
Link: https://www.reddit.com/r/MachineLearning/comments/gsivhg/r_language_models_are_fewshot_learners/Source snippet
[R] Language Models are Few-Shot LearnersThe performance on few-shot and zero-shot tasks improves dramatically as they increase model siz...
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/392255772_In-Context_Learning_in_Large_Language_Models_LLMs_Mechanisms_Capabilities_and_Implications_for_Advanced_Knowledge_Representation_and_ReasoningSource snippet
In-Context Learning in Large Language Models (LLMs)Mar 16, 2026 — We investigate how LLMs encode and use knowledge via ICL, the evolving...
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/373686518_Are_Emergent_Abilities_in_Large_Language_Models_just_In-Context_LearningSource snippet
Are Emergent Abilities in Large Language Models just In-...Sep 4, 2023 — Large language models have exhibited emergent abilities, demons...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=5i-SC-roENMSource snippet
GPT-3: Language Models are Few-shot Learnerstpt-3 achieves promising results under the regimes of zero shot one shot and few shot learnin...
Topic Tree