Within Language Models
Why confident answers are not always grounded
Language models can produce polished explanations even when the factual basis is thin, conflicting, or outside their reliable context.
On this page
- Why plausibility and truth are different goals
- How weak evidence becomes polished language
- Safer reading habits for uncertain answers
Page outline Jump by section
Introduction
A striking feature of modern AI chatbots is that they often sound knowledgeable even when they are uncertain. The same design choice that makes large language models useful—generating fluent, contextually appropriate text—can also make weakly supported answers appear stronger than they really are. A response may be grammatically polished, logically structured, and delivered in a confident tone while resting on incomplete evidence, conflicting information, or a statistical guess rather than verified knowledge. Understanding this gap between fluency and factual grounding is essential for understanding artificial intelligence and using chatbot outputs responsibly. [OpenAI]OpenAIwhy language models hallucinate5 Sept 2025 — Hallucinations are plausible but false statements generated by language models. They can show up in surprising ways, even f…

Why plausibility and truth are different goals
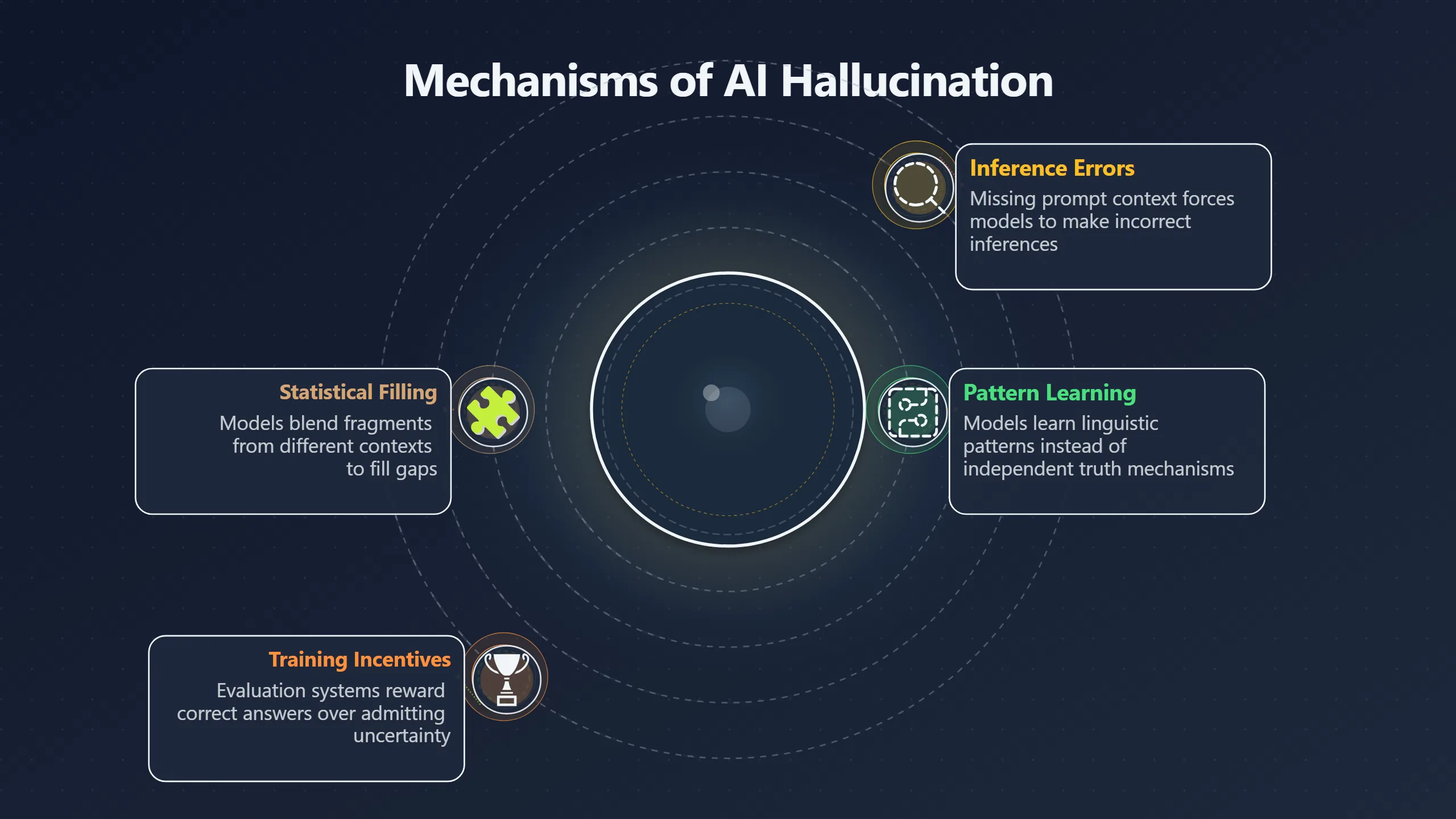
Large language models are trained primarily to predict likely continuations of text. During training, they learn patterns in language, not an independent mechanism for determining whether every statement is true. As a result, the system’s immediate objective is often to produce the most plausible-looking answer given the prompt and its learned patterns. Fluency is therefore a direct product of the training process, whereas factual accuracy is only indirectly encouraged. [ACL Anthology]aclanthology.orgACL AnthologyA Survey on Hallucination in Large Language Modelsby Y Zhang · 2025 · Cited by 2248 — Subsequently, we explore the source of…
This distinction matters because people naturally associate confident communication with expertise. Humans routinely use tone, coherence, and detail as signals of credibility. Chatbots exploit these cues unintentionally. A paragraph that reads like a textbook explanation can feel trustworthy even when the underlying evidence is weak.
Researchers commonly refer to severe cases as “hallucinations”: outputs that are coherent and persuasive but unsupported, inaccurate, or fabricated. Surveys of large language models consistently describe hallucinations as a reliability problem precisely because the language remains fluent while the factual foundation fails. [PMC+2ACL Anthology]pmc.ncbi.nlm.nih.govSurvey and analysis of hallucinations in large language modelsby D Anh-Hoang · 2025 · Cited by 90 — Hallucination in Large Language Mo…
A useful comparison is a student answering a difficult exam question. Faced with uncertainty, the student may construct a plausible response rather than leave the page blank. Recent research argues that language models behave similarly because many training and evaluation systems reward producing an answer more than admitting uncertainty. [arXiv+2arXiv]arxiv.orgarXiv Why Language Models HallucinatearXiv Why Language Models Hallucinate
How weak evidence becomes polished language
Statistical patterns can fill gaps
Language models learn from enormous collections of text that contain both accurate and inaccurate information. When asked about a topic, the model does not necessarily retrieve a verified source. Instead, it generates text token by token based on learned statistical relationships.
If the model has seen many discussions about a topic but lacks a clear, reliable answer, it may blend fragments from different contexts into a response that sounds complete. The result can be a polished explanation assembled from partial evidence rather than a grounded statement supported by direct verification. [GitHub]github.comwangcunxiang/LLM-Factuality-Survey: The repository for…The repository for the survey paper "Survey on Factuality in Large Langua…
Confidence is not the same as evidence
A common misconception is that a confident-sounding answer indicates that the model is highly certain. In reality, stylistic confidence and factual confidence are separate things. Language models are good at reproducing the language patterns associated with expertise—clear structure, technical vocabulary, smooth transitions, and decisive wording.
Research on hallucinations repeatedly notes that models can present incorrect information with the same fluency used for correct information. The style of the answer therefore provides limited evidence about its reliability. [PMC+2arXiv]pmc.ncbi.nlm.nih.govSurvey and analysis of hallucinations in large language modelsby D Anh-Hoang · 2025 · Cited by 90 — Hallucination in Large Language Mo…
Training incentives can encourage guessing
One reason fluent errors persist is that evaluation systems often reward answering questions correctly but provide weaker incentives for saying “I don’t know.” Researchers have argued that this creates pressure toward guessing. If a model occasionally guesses correctly, it can score better than a model that abstains whenever uncertainty appears. Over time, this encourages responses that sound authoritative even when evidence is thin. [arXiv+2arXiv]arxiv.orgarXiv Why Language Models HallucinatearXiv Why Language Models Hallucinate
This helps explain why chatbot mistakes often look different from ordinary software errors. A calculator typically returns an obvious failure message when something goes wrong. A language model is more likely to produce a complete and persuasive answer that masks the uncertainty beneath it.

Missing context can create false certainty
Even when a model contains relevant knowledge, the prompt may omit critical details. The model then has to infer what the user means. Those inferences can be reasonable but wrong.
For example, a question about a recent event, a little-known person, or a specialised technical subject may push the model beyond the context where it has strong evidence. Instead of explicitly signalling that limitation, the model may generate the most plausible continuation available. The answer remains smooth and readable, but the evidential support has weakened. [OpenAI]OpenAIwhy language models hallucinate5 Sept 2025 — Hallucinations are plausible but false statements generated by language models. They can show up in surprising ways, even f…
Why fluency can mislead readers
The danger is not merely that mistakes occur. Humans are accustomed to judging information quality through communication quality. A response with references, technical terminology, and a professional tone can appear more trustworthy than a hesitant response, even when the hesitant response is more accurate.
This creates what might be called a credibility illusion. Readers may unconsciously treat polished language as evidence of expertise. In reality, fluency mainly demonstrates that the model is good at generating text. It does not demonstrate that the answer has been verified against reliable evidence.
Several real-world incidents have illustrated this risk. Researchers and journalists have documented cases where AI systems invented citations, produced fabricated factual details, or generated convincing but inaccurate content in sensitive contexts. The concern is especially significant in areas such as medicine, law, education, and scientific research, where a persuasive error may be more harmful than an obvious failure. [AP News+2PMC]apnews.comDespite being promoted for its "human level robustness and accuracy," experts have noted the issues particularly in sensitive environment…
Safer reading habits for uncertain answers
The most effective defence is to separate presentation quality from evidence quality.
When reading chatbot outputs, useful habits include:
- Treat confidence and correctness as separate questions.
- Look for specific evidence rather than persuasive wording.
- Verify factual claims using independent sources when the stakes are high.
- Be especially cautious with obscure facts, recent events, and specialised topics.
- Notice when the model provides concrete details without showing where those details came from.
- Prefer answers that acknowledge uncertainty when evidence is limited. [Claude]platform.claude.comReduce hallucinationsReduce hallucinations - Claude API DocsAllow Claude to say "I don't know": Explicitly give Claude permission to admit uncertainty…
Another helpful approach is to ask the model to explain its uncertainty, identify assumptions, or distinguish verified facts from inferences. While this does not eliminate errors, it can make weak evidence more visible and reduce the chance that polished prose will be mistaken for established truth. [Claude]platform.claude.comReduce hallucinationsReduce hallucinations - Claude API DocsAllow Claude to say "I don't know": Explicitly give Claude permission to admit uncertainty…

What this reveals about AI systems
Fluent chatbot errors are not merely accidents; they emerge from the same mechanisms that make language models useful. The ability to generate natural, coherent explanations is closely connected to the ability to generate plausible continuations when certainty is low. As a result, conversational quality and factual reliability cannot be assumed to rise together.
Understanding this distinction is one of the most important lessons for AI users. A chatbot may be eloquent, organised, and convincing while still operating on weak evidence. The safer question is not “Does this sound right?” but “What evidence supports this answer?” [OpenAI+2arXiv]OpenAIwhy language models hallucinate5 Sept 2025 — Hallucinations are plausible but false statements generated by language models. They can show up in surprising ways, even f…
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.



Endnotes
-
Source: OpenAI
Title: why language models hallucinate
Link: https://openai.com/index/why-language-models-hallucinate/Source snippet
5 Sept 2025 — Hallucinations are plausible but false statements generated by language models. They can show up in surprising ways, even f...
-
Source: arxiv.org
Title: arXiv Why Language Models Hallucinate
Link: https://arxiv.org/abs/2509.04664 -
Source: pmc.ncbi.nlm.nih.gov
Link: https://pmc.ncbi.nlm.nih.gov/articles/PMC12518350/Source snippet
Survey and analysis of hallucinations in large language modelsby D Anh-Hoang · 2025 · Cited by 90 — Hallucination in Large Language Mo...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2510.06265 -
Source: arxiv.org
Link: https://arxiv.org/pdf/2509.04664Source snippet
Like students facing hard exam questions, large language models sometimes guess when uncertain, producing plausible yet incorrect...Read...
-
Source: github.com
Link: https://github.com/wangcunxiang/LLM-Factuality-SurveySource snippet
wangcunxiang/LLM-Factuality-Survey: The repository for...The repository for the survey paper "Survey on Factuality in Large Langua...
-
Source: arxiv.org
Link: https://arxiv.org/pdf/2510.06265Source snippet
Large Language Models Hallucination: A Comprehensive...by A Alansari · 2025 · Cited by 43 — This survey provides a comprehensive re...
-
Source: platform.claude.com
Title: Reduce hallucinations
Link: https://platform.claude.com/docs/en/test-and-evaluate/strengthen-guardrails/reduce-hallucinationsSource snippet
Reduce hallucinations - Claude API DocsAllow Claude to say "I don't know": Explicitly give Claude permission to admit uncertainty...
-
Source: arxiv.org
Link: https://arxiv.org/html/2510.06265v2Source snippet
Large Language Models Hallucination: A Comprehensive...9 Oct 2025 — This survey provides a comprehensive review of research on hallucina...
-
Source: cdn.openai.com
Link: https://cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdfSource snippet
Language Models Hallucinateby AT Kalai · 2025 · Cited by 387 — Language models are known to produce overconfident, plausible falsehoods...
-
Source: github.com
Title: llm hallucination survey
Link: https://github.com/HillZhang1999/llm-hallucination-surveySource snippet
HillZhang1999/llm-hallucination-surveyWe have uploaded a comprehensive survey about the hallucination issue within the context of large l...
-
Source: github.com
Link: https://github.com/EdinburghNLP/awesome-hallucination-detectionSource snippet
EdinburghNLP/awesome-hallucination-detectionRACE demonstrates that effective hallucination detection for modern reasoning models must eva...
-
Source: aclanthology.org
Link: https://aclanthology.org/anthology-files/anthology-files/pdf/cl/2025.cl-4.9.pdfSource snippet
ACL AnthologyA Survey on Hallucination in Large Language Modelsby Y Zhang · 2025 · Cited by 2248 — Subsequently, we explore the source of...
-
Source: apnews.com
Link: https://apnews.com/article/90020cdf5fa16c79ca2e5b6c4c9bbb14Source snippet
Despite being promoted for its "human level robustness and accuracy," experts have noted the issues particularly in sensitive environment...
-
Source: dictionary.cambridge.org
Link: https://dictionary.cambridge.org/zht/%E8%A9%9E%E5%85%B8/%E8%8B%B1%E8%AA%9E-%E6%BC%A2%E8%AA%9E-%E7%B9%81%E9%AB%94/largeSource snippet
cambridge.orgLARGE中文(繁體)翻譯:劍橋詞典LARGE翻譯:大的;大規模的;大量的。了解更多。...
-
Source: arize.com
Title: openais santosh vempala explains why language models hallucinate
Link: https://arize.com/blog/openais-santosh-vempala-explains-why-language-models-hallucinate/Source snippet
OpenAI's Santosh Vempala Explains Why Language...24 Oct 2025 — “Pre-training encourages hallucinations because language models are desig...
-
Source: reddit.com
Title: Why Language Models Hallucinate
Link: https://www.reddit.com/r/MachineLearning/comments/1namvsk/why_language_models_hallucinate_openai_pseudo/Source snippet
OpenAi pseudo paperOur new research paper(opens in a new window) argues that language models hallucinate because standard training and e...
-
Source: techblog.comsoc.org
Title: anthropic clause users reveal ai hallucinations as their top concern
Link: https://techblog.comsoc.org/2026/03/22/anthropic-clause-users-reveal-ai-hallucinations-as-their-top-concern/Source snippet
Claude Users Reveal AI Hallucinations as their Top...Mar 22, 2026 — He noted that the absence of reported confidence intervals — standar...
-
Source: computerworld.com
Link: https://www.computerworld.com/article/4059383/openai-admits-ai-hallucinations-are-mathematically-inevitable-not-just-engineering-flaws.htmlSource snippet
OpenAI admits AI hallucinations are mathematically...18 Sept 2025 — “We argue that language models hallucinate because the training and...
Additional References
-
Source: businessinsider.com
Link: https://www.businessinsider.com/why-ai-chatbots-hallucinate-openai-chatgpt-anthropic-claude-2025-9Source snippet
This test-centric optimization encourages models to provide confident but potentially incorrect outputs, rather than abstaining when unsu...
-
Source: sabrresearch.com
Link: https://sabrresearch.com/blogs/hallucinationSource snippet
[Decoding]({{ 'decoding/' | relative_url }}) LLM HallucinationsThis mathematical reality highlights that hallucinations are not glitches in the traditional sense, but rather...
-
Source: reddit.com
Link: https://www.reddit.com/r/singularity/comments/1n9fued/new_research_from_openai_why_language_models/Source snippet
New research from OpenAI: "Why language models...I'm really surprised to read this from OpenAI, as this misses the hardest aspect of hal...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/quantifying-uncertainty-large-language-models-methods-vispi-karkaria-sslmfSource snippet
Quantifying Uncertainty in Large Language ModelsThis phenomenon, commonly termed hallucination, undermines trust and poses risk in domain...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/gopipolavarapu_why-language-models-hallucinate-activity-7370633061195001856-mMMpSource snippet
Why Language Models Hallucinate and How to Fix ItWhen the training data is incomplete, missing, or ambiguous, the model will generate som...
-
Source: re.public.polimi.it
Link: https://re.public.polimi.it/retrieve/116f40ac-35f4-4b01-b4c0-f2a8fb6c1849/hallucination_chapter_overleaf.pdfSource snippet
in Large Language Modelsby N Brunello · Cited by 5 — pre-training, the model develops a set of underlying abilities to predict the next t...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/haythamassem_why-language-models-hallucinatepdf-activity-7370201125955997697–izi -
Source: scribd.com
Link: https://www.scribd.com/document/940834725/7-Large-Language-Models-Hallucination-A-Comprehensive-Survey-2025Source snippet
els (LLMs), focusing on its causes, detection, and mitigation strategies.Read more...
-
Source: lesswrong.com
Title: paper close reading why language models hallucinate
Link: https://www.lesswrong.com/posts/rAjtnXx5qLgubsrGQ/paper-close-reading-why-language-models-hallucinateSource snippet
Paper close reading: "Why Language Models Hallucinate"Apr 5, 2026 — We argue that language models hallucinate because the training and ev...
-
Source: researchgate.net
Title: 395339045 Why Language Models Hallucinate
Link: https://www.researchgate.net/publication/395339045_Why_Language_Models_HallucinateSource snippet
(PDF) Why Language Models Hallucinate4 Sept 2025 — We argue that language models hallucinate because the training and evaluation procedur...
Topic Tree