Within Self attention
How Attention Resolves Ambiguous Words
Attention weights help the same word lean toward different nearby or distant clues when its meaning depends on context.
On this page
- Why the same token can mean different things
- How query key scores become context weights
- The bank example and other meaning shifts
Page outline Jump by section
Introduction
When a word has multiple possible meanings, attention weights help a Transformer decide which meaning fits the current context. A word such as “bank” could refer to a financial institution or the side of a river. Rather than assigning one fixed meaning to the token, the model compares it with other tokens in the sentence and gives different amounts of attention to different contextual clues. The resulting attention weights act like a relevance map, indicating which surrounding words should influence the interpretation most strongly. This is one of the key ways self-attention turns a generic token into a context-sensitive representation. [arXiv+2ApX Machine Learning]arxiv.orgAttention Is All You NeedWe call our particular attention "Scaled Dot-Product Attention" (Figure 2). The input consists of queries a…
 In the broader mechanism of self-attention, every token can connect directly to nearby or distant words. For ambiguous words, the important question is not whether a connection exists, but which connections receive the greatest weight. Those weights help the model select the context that resolves uncertainty and supports the correct meaning. [arXiv]arxiv.orgAttention Is All You NeedWe call our particular attention "Scaled Dot-Product Attention" (Figure 2). The input consists of queries a…
In the broader mechanism of self-attention, every token can connect directly to nearby or distant words. For ambiguous words, the important question is not whether a connection exists, but which connections receive the greatest weight. Those weights help the model select the context that resolves uncertainty and supports the correct meaning. [arXiv]arxiv.orgAttention Is All You NeedWe call our particular attention "Scaled Dot-Product Attention" (Figure 2). The input consists of queries a…
Why the Same Token Can Mean Different Things
Many words are polysemous: they carry several related or unrelated meanings. Humans resolve this naturally through context. Modern language models do something similar by creating contextual representations rather than relying on a single stored definition for each word. Research on contextualised embeddings, including BERT-based systems, shows that the same word can occupy different regions of the model’s representation space depending on surrounding context, allowing distinct meanings to emerge from usage rather than from a fixed dictionary entry. [arXiv+2Pair Code]arxiv.orgDoes BERT Make Any Sense? Interpretable Word Sense Disambiguation with Contextualized EmbeddingsSeptember 23, 2019…
Consider these sentences:
- “She deposited money at the bank.”
- “They sat on the bank of the river.”
The token “bank” begins as the same vocabulary item in both cases. What changes is the context available around it. Words such as “deposited” and “money” provide evidence for one meaning, while “river” provides evidence for another. Self-attention allows the model to measure the relevance of these clues directly. [IBM]ibm.comWhat is an attention mechanism?An attention mechanism is a machine learning technique that directs deep learning models, like transfor…
The result is that the representation of “bank” after attention is no longer a generic word embedding. It becomes a context-dependent representation that reflects the specific meaning needed in that sentence. [arXiv]arxiv.orgDoes BERT Make Any Sense? Interpretable Word Sense Disambiguation with Contextualized EmbeddingsSeptember 23, 2019…
How Query-Key Scores Become Context Weights
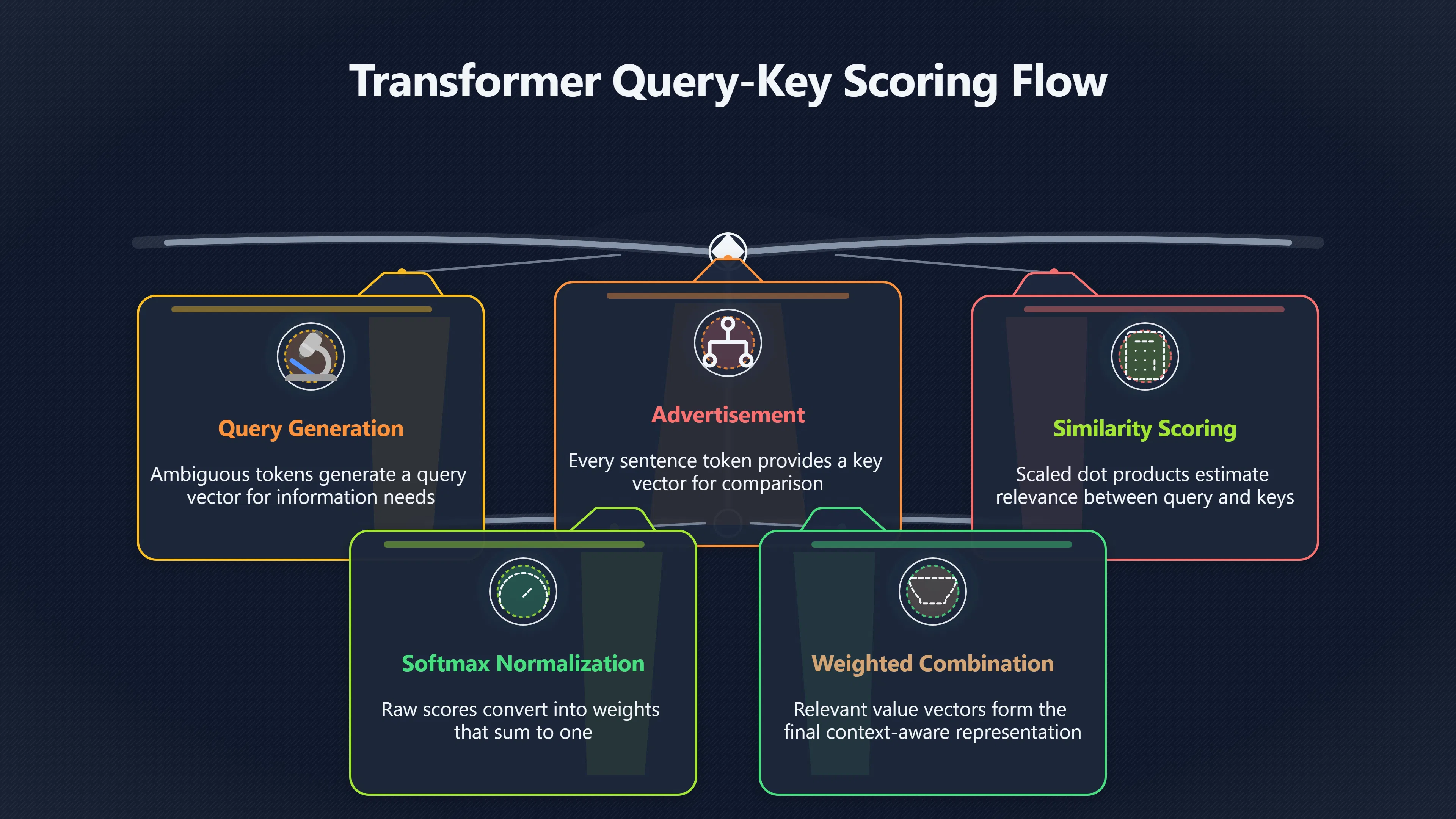
The mechanism begins when the ambiguous token generates a query vector. Every token in the sentence also provides a key vector and a value vector. The model compares the query with each key using a similarity calculation based on scaled dot products. Larger similarity scores indicate that a token may contain information useful for interpreting the current word. [arXiv+2Dive into Deep Learning]arxiv.orgAttention Is All You NeedWe call our particular attention "Scaled Dot-Product Attention" (Figure 2). The input consists of queries a…
The scores are then passed through a softmax function. This converts the raw scores into attention weights that sum to one. Tokens with higher relevance receive larger weights, while less relevant tokens receive smaller ones. The model then forms a weighted combination of the value vectors, allowing highly relevant context to contribute more strongly to the final representation. [DEV Community+3arXiv+3Medium]arxiv.orgAttention Is All You NeedWe call our particular attention "Scaled Dot-Product Attention" (Figure 2). The input consists of queries a…
A simplified interpretation is:
- The ambiguous word asks, “What information do I need?”
- Other words advertise, “Here is the information I contain.”
- Similarity scores estimate relevance.
- Attention weights determine influence.
- The weighted information is combined into a new context-aware representation.
Because every token can be considered simultaneously, the model is not restricted to immediate neighbours. A useful clue several words away can receive more weight than a nearby but irrelevant word. [arXiv+2PixelBank]arxiv.orgAttention Is All You NeedWe call our particular attention "Scaled Dot-Product Attention" (Figure 2). The input consists of queries a…

The Bank Example and Other Meaning Shifts
The “bank” example illustrates how attention can favour different clues in different contexts.
In “She deposited money at the bank”, attention may assign substantial weight to words such as “deposited” and “money”. These tokens strongly signal the financial sense. Their value vectors contribute heavily to the updated representation of “bank”. [arXiv]arxiv.orgAttention Is All You NeedWe call our particular attention "Scaled Dot-Product Attention" (Figure 2). The input consists of queries a…
In “They sat on the bank of the river”, attention can shift towards “river”. Even though the token is identical, the attention pattern changes because the query-key similarities change. The resulting representation moves towards the geographical meaning instead of the financial one. [ApX Machine Learning]apxml.comAp X Machine Learning Scaled Dot-Product Attention Mechanism Scaled Dot-Product Attention is the core calculation mechanism for self-atteIt computes how much each element in a sequence should attend to every …Read more
The same process helps with many other ambiguities:
- “Bat” can mean an animal or sports equipment.
- “Crane” can refer to a bird or a machine.
- “Pitch” can describe a musical tone, a sports field, or a sales presentation.
In each case, attention weights help identify which surrounding words contain the strongest evidence for the intended interpretation. [arXiv]arxiv.orgDoes BERT Make Any Sense? Interpretable Word Sense Disambiguation with Contextualized EmbeddingsSeptember 23, 2019…
Why Attention Is Helpful but Not the Whole Story
A common simplification is that attention alone performs word-sense disambiguation. In practice, the situation is more subtle. Research examining attention during machine translation found that attention does not always place most of its weight directly on the context words that humans might expect. Instead, important contextual information can already be encoded inside the hidden representations produced by earlier layers. [arXiv]arxiv.orgAn Analysis of Attention Mechanisms: The Case of Word Sense Disambiguation in Neural Machine TranslationOctober 17, 2018…
Studies of BERT and related models also show that some attention heads appear to specialise in linguistic relationships such as syntax, reference tracking, or structural dependencies. Different heads can focus on different aspects of the sentence, providing multiple perspectives that together support interpretation. [arXiv]arxiv.orgarXiv What Does BERT Look At? An Analysis of BERT's AttentionWhat Does BERT Look At? An Analysis of BERT's AttentionJune 11, 2019…
This means that attention weights are best understood as part of a larger system. They help route information from relevant context, but the model’s ability to resolve ambiguity also depends on the contextual representations learned throughout training. [arXiv]arxiv.orgAn Analysis of Attention Mechanisms: The Case of Word Sense Disambiguation in Neural Machine TranslationOctober 17, 2018…
What Changes After Attention Has Done Its Work
The most important outcome is that the model no longer treats a word as having one fixed meaning. After attention combines information from relevant context, the token becomes a contextualised representation tailored to its current usage. Two occurrences of the same word can therefore end up with very different internal representations even though they share the same vocabulary entry. [arXiv+2Pair Code]arxiv.orgDoes BERT Make Any Sense? Interpretable Word Sense Disambiguation with Contextualized EmbeddingsSeptember 23, 2019…
From the perspective of understanding artificial intelligence, this is one of the central strengths of self-attention. Attention weights allow a model to identify which contextual clues matter most for an ambiguous word and to use those clues when constructing meaning. Instead of relying on rigid definitions, the model continually reshapes word representations according to context, making language understanding far more flexible and precise. [arXiv+2IBM]arxiv.orgAttention Is All You NeedWe call our particular attention "Scaled Dot-Product Attention" (Figure 2). The input consists of queries a…

Amazon book picks
Further Reading
Books and field guides related to How Attention Resolves Ambiguous Words. Use these as the next step if you want deeper reading beyond the article.
Hands-On Large Language Models
Provides intuitive examples of contextual token interpretation.
Natural Language Processing with Transformers
Shows how transformers resolve meaning through context.
Speech and Language Processing: Pearson New International Edi...
Covers ambiguity, word meaning, and contextual interpretation.
Transformers for Machine Learning
Explains attention-based contextual representations.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: arxiv.org
Link: https://arxiv.org/html/1706.03762v7Source snippet
Attention Is All You NeedWe call our particular attention "Scaled Dot-Product Attention" (Figure 2). The input consists of queries a...
-
Source: ibm.com
Link: https://www.ibm.com/think/topics/attention-mechanismSource snippet
What is an attention mechanism?An attention mechanism is a [machine learning]({{ 'machine-learning/' | relative_url }}) technique that directs [deep learning]({{ 'deep-learning/' | relative_url }})...
-
Source: pixelbank.dev
Link: https://pixelbank.dev/concepts/attentionSource snippet
Attention Is All You Need — TransformersSelf-attention is the core operation of the Transformer. It allows every token in a sequ...
-
Source: arxiv.org
Link: https://arxiv.org/abs/1909.10430Source snippet
Does BERT Make Any Sense? Interpretable Word Sense Disambiguation with Contextualized EmbeddingsSeptember 23, 2019...
Published: September 23, 2019
-
Source: medium.com
Link: https://medium.com/%40saraswatp/understanding-scaled-dot-product-attention-in-transformer-models-5fe02b0f150cSource snippet
ghts to compute a weighted sum of the values.Read more...
-
Source: dev.to
Title: decodingattention is all you need 2eog
Link: https://dev.to/kaustubhyerkade/decodingattention-is-all-you-need-2eogSource snippet
DEV CommunityDecoding the "Attention Is All You Need"......27 May 2025 — Scaled Dot-Product Attention For each token, attention scores ar...
Published: May 2025
-
Source: arxiv.org
Link: https://arxiv.org/abs/1810.07595Source snippet
An Analysis of Attention Mechanisms: The Case of Word Sense Disambiguation in Neural Machine TranslationOctober 17, 2018...
Published: October 17, 2018
-
Source: arxiv.org
Title: arXiv What Does BERT Look At? An Analysis of BERT’s Attention
Link: https://arxiv.org/abs/1906.04341Source snippet
What Does BERT Look At? An Analysis of BERT's AttentionJune 11, 2019...
Published: June 11, 2019
-
Source: arxiv.org
Title: arXiv Do Attention Heads in BERT Track Syntactic Dependencies?
Link: https://arxiv.org/abs/1911.12246 -
Source: jvgd.medium.com
Title: scaled dot product attention explained 3fb250f1acd1
Link: https://jvgd.medium.com/scaled-dot-product-attention-explained-3fb250f1acd1Source snippet
This key idea of this attention mechanism is to...Read more...
-
Source: medium.com
Title: The paper explicitly motivates this scaling. Step 3: softmax.Read more
Link: https://medium.com/%40adnanmasood/attention-is-all-you-need-explained-like-youre-smart-and-busy-2a3d7436144fSource snippet
Attention Is All You Need, explained like you're smart and...Because dot products grow with dimension; scaling keeps softmax gradients h...
-
Source: kumarshivam-66534.medium.com
Link: https://kumarshivam-66534.medium.com/mastering-attention-mechanisms-how-transformers-understand-context-in-[generative-aiSource snippet
Attention Mechanisms: How Transformers...Words are converted into numerical vectors that capture semantic meaning. These vectors can com...
-
Source: medium.com
Link: https://medium.com/%40kavierim/transformers-from-scratch-part-2-scaled-dot-product-attention-6c0634ce79afSource snippet
uld attend to every other element.Read more...
-
Source: medium.com
Link: https://medium.com/synapse-dev/understanding-bert-transformer-attention-isnt-all-you-need-5839ebd396dbSource snippet
Understanding BERT Transformer: Attention isn't all you needBERT uses 12 separate attention mechanism for each layer. In other cases, a g...
-
Source: arxiv.org
Link: https://arxiv.org/html/2312.00680v1Source snippet
Contextualized Word Senses: From Attention to...The neural architectures of language models are becoming increasingly complex, especiall...
-
Source: apxml.com
Link: https://apxml.com/courses/introduction-to-transformer-models/chapter-2-self-attention-[multi-headSource snippet
It computes how much each element in a sequence should attend to every...Read more...
-
Source: pair-code.github.io
Link: https://pair-code.github.io/interpretability/context-atlas/blogpost/Source snippet
Language, Context, and Geometry in Neural NetworksThe crisp clusters seen in the visualizations above suggest that BERT may create simple...
-
Source: d2l.ai
Title: Dive into Deep Learning11.3
Link: https://d2l.ai/chapter_attention-mechanisms-and-transformers/attention-scoring-functions.htmlSource snippet
11.3. Attention Scoring FunctionsTo ensure that the variance of the dot product still remains 1 regardless of vector length, we use the s...
-
Source: jaketae.github.io
Link: https://jaketae.github.io/study/transformer/Source snippet
Attention is All You Need20 Jan 2021 — The short answer is that multi-head self-attention is nothing but a parallel repetition of self-at...
Additional References
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/334117983_An_Analysis_of_Attention_Mechanisms_The_Case_of_Word_Sense_Disambiguation_in_Neural_Machine_TranslationSource snippet
(PDF) An Analysis of Attention Mechanisms: The Case of...1 Nov 2018 — Existing research on the interpretability of Transformers in machi...
-
Source: youtu.be
Link: https://youtu.be/1il-s4mgNdI?si=XaVxj6bsdy3VkgEXSource snippet
If you're interested in the herculean task of interpreting what these large networks might actually be doing, the Transformer Circuits po...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=0PjHri8tc1cSource snippet
L19.4.2 Self-Attention and Scaled Dot-Product AttentionWe are now introducing three trainable weight matrices that are multiplied with th...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=eMlx5fFNoYc&vl=enSource snippet
Attention in transformers, step-by-step | Deep Learning...The attention block allows the model to move information encoded in one embedd...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=mlk0rddP3L4&list=PLuhqtP7jdD8CftMk831qdE8BlIteSaNzD&t=0sSource snippet
"✔ Complete Logistic Regression Playlist: [https://www.youtube.com/watch?v=U1omz0B9FTw&list=PLuhqtP7jdD8Chy7QIo5U0zzKP8-emLdny&t=0s..."](https://www.youtube.com/watch?v=U1omz0B9FTw&list=PLuhqtP7jdD8Chy7QIo5U0zzKP8-emLdny&t=0s...")...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=U1omz0B9FTw&list=PLuhqtP7jdD8Chy7QIo5U0zzKP8-emLdny&t=0sSource snippet
"✔ Complete Linear Regression Playlist: [https://www.youtube.com/watch?v=nwD5U2WxTdk&list=PLuhqtP7jdD8AFocJuxC6_Zz0HepAWL9cF&t=0s..."](https://www.youtube.com/watch?v=nwD5U2WxTdk&list=PLuhqtP7jdD8AFocJuxC6_Zz0HepAWL9cF&t=0s...")...
-
Source: aryanupadhyay.com
Title: scaled dot product attention explained why we divide by dₖ in transformers
Link: https://www.aryanupadhyay.com/post/scaled-dot-product-attention-explained-why-we-divide-by-d%E2%82%96-in-transformersSource snippet
In the original research paper Attention Is All You Need, the core idea remains the same, but there is...Read more...
-
Source: reddit.com
Link: https://www.reddit.com/r/MachineLearning/comments/qidpqx/d_how_to_truly_understand_attention_mechanism_in/Source snippet
However it is not that easy to fully understand, and in my opinion, somewhat unintuitive...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=E5Z7FQp7AQQ&list=PLuhqtP7jdD8CD6rOWy20INGM44kULvrHu&t=0sSource snippet
"✔ Complete Neural Network: [https://www.youtube.com/watch?v=mlk0rddP3L4&list=PLuhqtP7jdD8CftMk831qdE8BlIteSaNzD&t=0s..."](https://www.youtube.com/watch?v=mlk0rddP3L4&list=PLuhqtP7jdD8CftMk831qdE8BlIteSaNzD&t=0s...")...
-
Source: stats.stackexchange.com
Title: I’ve tried searching online, but all the resources
Link: https://stats.stackexchange.com/questions/421935/what-exactly-are-keys-queries-and-values-in-attention-mechanismsSource snippet
exactly are keys, queries, and values in attention...13 Aug 2019 — How should one understand the keys, queries, and values that are ofte...
Topic Tree