Within Over compression
Why AI Makes Studies Sound More Certain
AI summaries can make narrow, tentative, or correlational research sound broader and more settled than the paper supports.
On this page
- How study limits disappear in summary form
- Correlation, causation, and scope creep
- How readers can check what the paper actually showed
Page outline Jump by section
Introduction
Scientific papers are designed to communicate not only what researchers found, but also how uncertain those findings remain. Sample sizes, study populations, confidence intervals, alternative explanations and methodological limits are not side notes; they define how far a result can safely be applied.
 When AI systems summarise research, they often compress those qualifications into shorter, cleaner conclusions. The result is not always an outright error. More often, a tentative finding becomes a stronger claim, a limited observation sounds universal, or a correlation starts to resemble proof of causation. In high-stakes domains, this shift can matter as much as a factual mistake because readers may come away with more confidence than the evidence supports. Recent research suggests that large language models systematically tend to broaden scientific conclusions beyond the scope of the original papers they summarise. [DOI]doi.orgGeneralization bias in large language model summarization of scientific research | Royal Society Open Science | The Royal SocietyApril…
When AI systems summarise research, they often compress those qualifications into shorter, cleaner conclusions. The result is not always an outright error. More often, a tentative finding becomes a stronger claim, a limited observation sounds universal, or a correlation starts to resemble proof of causation. In high-stakes domains, this shift can matter as much as a factual mistake because readers may come away with more confidence than the evidence supports. Recent research suggests that large language models systematically tend to broaden scientific conclusions beyond the scope of the original papers they summarise. [DOI]doi.orgGeneralization bias in large language model summarization of scientific research | Royal Society Open Science | The Royal SocietyApril…
How Study Limits Disappear in Summary Form
Scientific writing is full of restrictions that help readers interpret results correctly. Researchers specify who was studied, under what conditions, and how confident they are in their findings. AI summaries frequently remove or weaken these boundaries.
A paper might report that a treatment improved outcomes among a specific group of patients during a controlled trial. An AI summary may present the same finding as evidence that the treatment works generally. The underlying facts have not necessarily changed, but the scope of the claim has expanded.
Researchers at Utrecht University and the University of Cambridge examined thousands of AI-generated summaries of scientific papers and found that many leading models regularly produced broader generalisations than the original texts justified. In some models, overgeneralisation appeared in a substantial share of summaries even when the systems were explicitly instructed to be accurate. AI-generated summaries were also found to be nearly five times more likely than human-written summaries to contain overly broad claims. [DOI+2PMC]doi.orgGeneralization bias in large language model summarization of scientific research | Royal Society Open Science | The Royal SocietyApril…
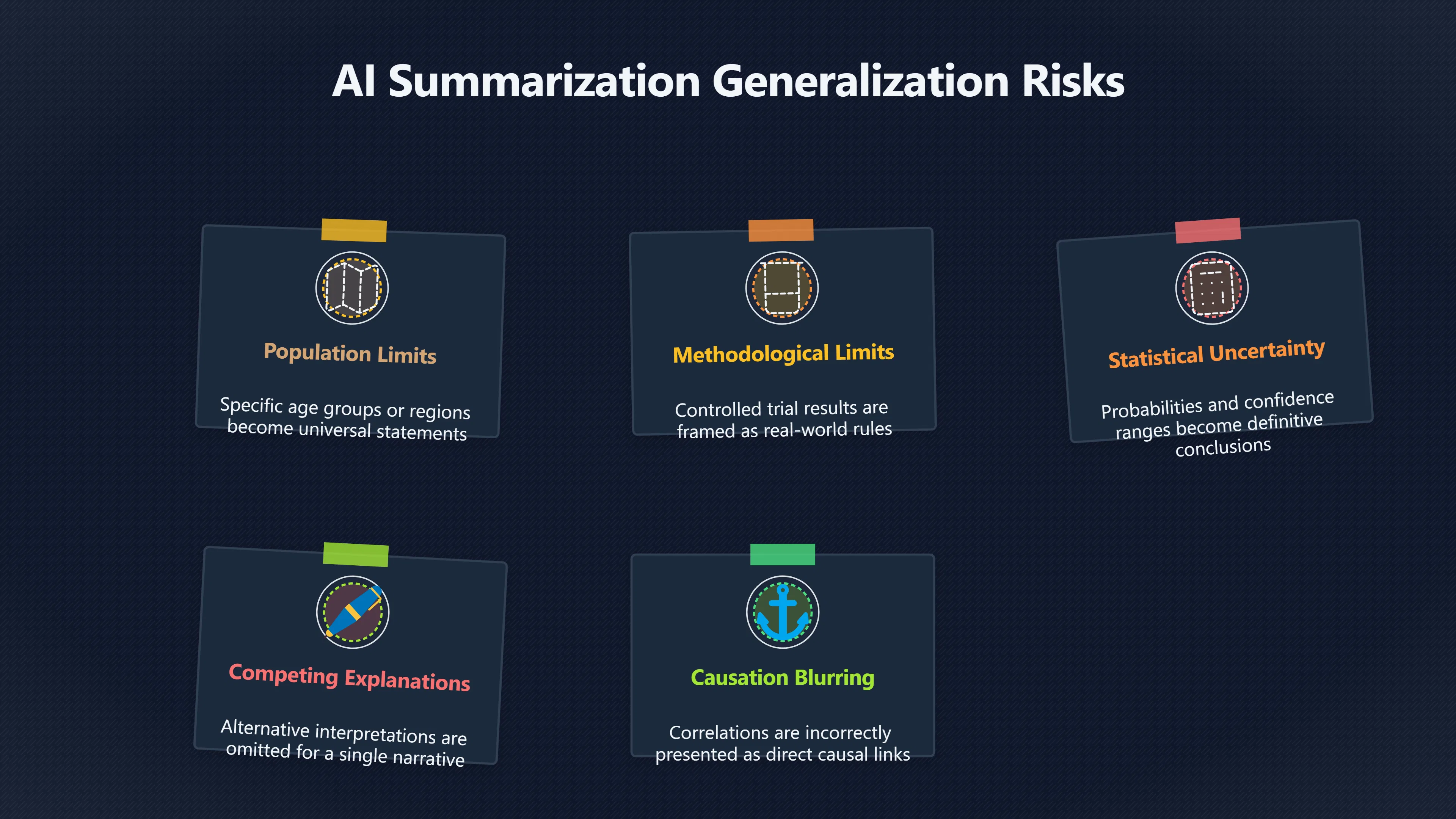
Several kinds of information commonly disappear during summarisation:
- Population limits: findings from one age group, region or species become statements about everyone.
- Methodological limits: results obtained under controlled conditions become recommendations for real-world settings.
- Statistical uncertainty: probabilities and confidence ranges become definitive conclusions.
- Competing explanations: alternative interpretations are omitted in favour of a single narrative.
These omissions can make a summary easier to read while simultaneously making it less faithful to the research.
Correlation, Causation, and Scope Creep
One of the most common ways scientific uncertainty becomes exaggerated is through the transition from correlation to causation.
Many studies identify associations rather than direct causal relationships. Researchers are often careful to say that two factors are linked, not that one causes the other. This distinction is fundamental because observed relationships may arise from hidden variables, selection effects or other confounding factors.
AI summaries can blur this boundary. A paper stating that people who exercise more tend to report better mental health may become a summary suggesting that exercise improves mental health. While the latter may ultimately be true, the specific study may not have established that conclusion.
The same pattern appears with scope creep. A result that applies to a narrow context can become framed as a general principle. For example:
Original findingStronger AI-style interpretationEvidence suggests an association under specific conditions.The factor influences outcomes.Results were observed in one population.The findings apply broadly.The study provides preliminary evidence.The study demonstrates the effect.Further research is needed.The issue is largely settled.
Researchers studying AI summarisation have noted that models often preserve a cautious tone through words such as “may” or “suggests” while still extending the reach of a claim beyond what the paper supports. The summary sounds careful, but the underlying generalisation is broader than the original evidence allows. [DOI]doi.orgGeneralization bias in large language model summarization of scientific research | Royal Society Open Science | The Royal SocietyApril…

Why Stronger Claims Feel More Convincing
Human readers are often drawn to clear explanations. Scientific papers are intentionally filled with caveats because uncertainty is part of the evidence. AI systems, by contrast, are optimised to produce coherent and useful-seeming responses.
This creates a subtle tension. A summary that preserves every qualification can appear complicated and unsatisfying. A summary that removes uncertainty often feels more informative.
Researchers have suggested that large language models may learn this tendency from the texts and feedback used during training. Human readers generally prefer answers that appear broadly applicable and easy to understand. As a result, systems can develop a tendency to favour fluency and generality over precision. [European Scientist]europeanscientist.comEuropean Scientist Chatbots are not very good at summarising scientific studiesEuropean ScientistChatbots are not very good at summarising scientific studiesMay 13, 2025…
The danger is that confidence and correctness become confused. Readers may not notice that important conditions have been removed because the resulting summary still sounds reasonable.
This is particularly concerning in areas such as medicine, public health and environmental science, where policy decisions and personal choices often depend on understanding the limits of evidence rather than merely knowing the headline result.
How Readers Can Check What the Paper Actually Showed
AI-generated summaries can be useful starting points, but they should not be treated as substitutes for the original research.
A few checks can reveal whether a summary has strengthened a claim beyond the evidence:
Look for the study population
Ask who was actually studied. Was the research conducted on humans, animals, a specific age group, a particular country or a narrowly selected sample? If the summary does not mention this, important limits may have been removed.
Find the authors’ stated limitations
Most papers contain a dedicated discussion of weaknesses and uncertainties. If an AI summary contains only findings and no limitations, it is likely presenting an incomplete picture.

Check whether the paper claims causation
Look for phrases such as “associated with”, “linked to”, or “correlated with”. If the original paper uses these terms but the summary uses language such as “causes”, “improves”, or “leads to”, the evidence may have been strengthened during summarisation.
Compare the abstract with the conclusion
Researchers often use cautious wording in both sections. If an AI summary sounds substantially more certain than either, that difference is a warning sign.
Watch for universal language
Words such as “always”, “proves”, “shows that”, or broad statements about “people” in general may indicate that study-specific restrictions have disappeared.
The Real Risk Is Overconfidence
The most important problem is not that AI always gets science wrong. It is that AI can make uncertain science sound settled.
Scientific knowledge advances through measured claims, replication, criticism and revision. Uncertainty is not a flaw in that process; it is one of the signals that helps readers judge the strength of evidence. When AI summaries compress away those signals, the resulting explanation can appear stronger, simpler and more actionable than the research warrants.
Recent evidence suggests that this tendency is not an occasional accident but a recurring pattern across major language models. In high-stakes settings, the consequence is not merely misunderstanding a paper. It is developing confidence in conclusions that the original researchers themselves were not prepared to make. [DOI+2PMC]doi.orgGeneralization bias in large language model summarization of scientific research | Royal Society Open Science | The Royal SocietyApril…
Amazon book picks
Further Reading
Books and field guides related to Why AI Makes Studies Sound More Certain. Use these as the next step if you want deeper reading beyond the article.
The Art of Statistics
Explains uncertainty, evidence quality and how conclusions should be interpreted.
Calling Bullshit
Teaches readers to scrutinise claims, summaries and overstated conclusions.
The Drunkard's Walk
Helps readers understand randomness, confidence and mistaken causal interpretations.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: doi.org
Link: https://doi.org/10.1098/rsos.241776Source snippet
Generalization bias in large language model summarization of scientific research | Royal Society Open Science | The Royal SocietyApril...
-
Source: pmc.ncbi.nlm.nih.gov
Link: https://pmc.ncbi.nlm.nih.gov/articles/PMC12042776/ -
Source: europeanscientist.com
Title: European Scientist Chatbots are not very good at summarising scientific studies
Link: https://www.europeanscientist.com/en/big-data/chatbots-are-not-very-good-at-summarising-scientific-studies/Source snippet
European ScientistChatbots are not very good at summarising scientific studiesMay 13, 2025...
Published: May 13, 2025
Additional References
-
Source: livescience.com
Link: https://www.livescience.com/technology/artificial-intelligence/reading-ai-summaries-makes-people-more-likely-to-buy-something-despite-alarming-60-percent-hallucination-rateSource snippet
Presented at major computational linguistics conferences in December 2025, the research demonstrated that large language models (LLMs) su...
Published: December 2025
-
Source: pubmed.ncbi.nlm.nih.gov
Link: https://pubmed.ncbi.nlm.nih.gov/40309181/Source snippet
Generalization bias in large language model summarization of scientific research - PubMed...
-
Source: youtube.com
Title: Generalization Bias in LLM Summarization of Scientific Research
Link: https://www.youtube.com/watch?v=tLvkH43QLGESource snippet
EP20 - Understanding Science Through LLMs? Beware of Generalisation Bias...
-
Source: arxiv.org
Title: Large language models eroding science understanding: an experimental study
Link: https://arxiv.org/abs/2604.25639Source snippet
April 28, 2026...
Published: April 28, 2026
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=Cb4Gms994b4Source snippet
Advanced AI Hallucinates More—Trust at Risk...
-
Source: reddit.com
Link: https://www.reddit.com/r/ArtificialInteligence/comments/1lss57oSource snippet
July 6, 2025...
Published: July 6, 2025
-
Source: youtube.com
Title: Advanced AI Hallucinates More—Trust at Risk
Link: https://www.youtube.com/watch?v=sY5OrjzaxiQSource snippet
Do your own research. But do it right...
-
Source: youtube.com
Title: Do your own research. But do it right
Link: https://www.youtube.com/watch?v=nD6hS8WV3ic
Topic Tree