Within Benchmark gaps
Why Long AI Answers Fail Differently
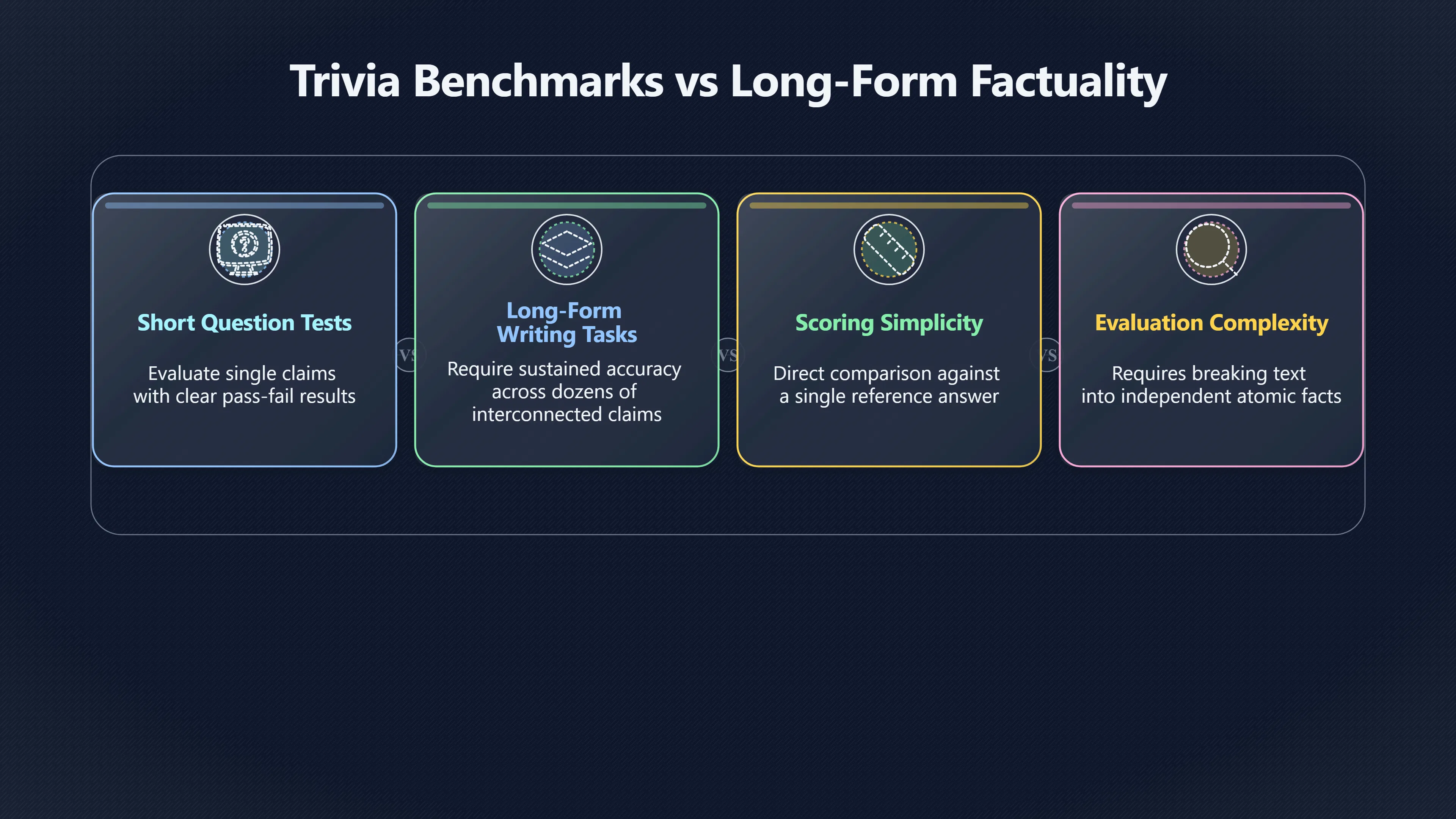
Short factual tests can hide the way errors accumulate when an AI answer contains many linked claims.
On this page
- Why single answer tests look cleaner than real tasks
- How small claim errors accumulate in reports
- What long form factuality checks try to measure
Page outline Jump by section
Introduction
A common way to test artificial intelligence is to ask short factual questions: a capital city, a historical date, a scientific definition, or a multiple-choice problem. These tests are useful, but they can create a misleading impression of reliability. Many of the most important AI failures do not appear in isolated questions. They emerge when a model must produce a long answer containing dozens of interconnected claims, citations, explanations, and inferences.
 This matters because most real-world uses of AI involve extended outputs: reports, research summaries, briefings, analyses, and educational explanations. A system that performs well on trivia-style benchmarks may still make significant mistakes once it must sustain accuracy across an entire document. Researchers have increasingly developed long-form factuality evaluations precisely because traditional benchmarks often fail to capture this difference. [arXiv]arxiv.orgFActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text GenerationMay 23, 2023…
This matters because most real-world uses of AI involve extended outputs: reports, research summaries, briefings, analyses, and educational explanations. A system that performs well on trivia-style benchmarks may still make significant mistakes once it must sustain accuracy across an entire document. Researchers have increasingly developed long-form factuality evaluations precisely because traditional benchmarks often fail to capture this difference. [arXiv]arxiv.orgFActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text GenerationMay 23, 2023…
Why Single-Answer Tests Look Cleaner Than Real Tasks
Short factual benchmarks usually evaluate one claim at a time. The model either produces the correct answer or it does not. This creates a relatively simple measurement problem.
Real-world writing is different. A 1,000-word report may contain dozens of factual statements. Some may be correct, some partly correct, and some unsupported. The final document can sound coherent even when several individual claims are wrong.
This difference means that benchmark scores can hide a practical reliability problem. Imagine a model that is highly accurate on individual facts. If that model is asked to generate a long explanation containing many separate factual statements, each statement introduces another opportunity for error. The overall answer may therefore be less reliable than its short-question benchmark performance suggests. [arXiv]arxiv.orgFActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text GenerationMay 23, 2023…
Another reason trivia tests appear cleaner is that they usually have clearly defined answers. Real reports often require the model to:
- Combine information from multiple sources.
- Maintain consistency across paragraphs.
- Keep track of names, dates, and relationships.
- Distinguish established facts from uncertain claims.
- Avoid inventing details to fill gaps.
These demands rarely appear in simple question-answer benchmarks, even though they are central to practical use. [arXiv]arxiv.orgFActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text GenerationMay 23, 2023…
How Small Claim Errors Accumulate in Reports
The key mechanism is error accumulation.
A long answer is not one factual claim. It is a collection of many claims linked together. Each claim can fail independently.
For example, consider an AI-generated company profile. The model might correctly identify the company’s founder but incorrectly state the founding year. It might accurately describe a product line but invent a market-share statistic. It might correctly mention an acquisition while misstating its timing. Individually, these mistakes can seem minor. Together, they can substantially reduce the reliability of the document.
Researchers behind the FActScore evaluation framework argue that long-form factuality cannot be assessed adequately with a single pass-fail judgement because generated text often contains a mixture of supported and unsupported statements. Instead, they break outputs into “atomic facts” and evaluate each one separately. Their work showed that long answers frequently contain enough unsupported claims that coarse evaluation methods miss important weaknesses. [arXiv]arxiv.orgFActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text GenerationMay 23, 2023…
This accumulation effect creates a mathematical challenge for reliability measurement. Even if a model performs well on individual claims, the probability that every claim in a long report is correct decreases as the number of claims increases. A benchmark based on isolated facts may therefore overestimate how dependable the same model will be when writing an extended analysis.
Coherence Can Hide Errors
One reason these failures are difficult to detect is that language models are designed to produce fluent text.
Readers often judge answers by readability, structure, and confidence. A long report with good organisation can appear trustworthy even when several factual components are incorrect. The model’s ability to connect ideas smoothly may conceal individual inaccuracies.
This is especially important because many benchmark questions reward arriving at the correct final answer. In long-form writing, however, users often care about the accuracy of every supporting statement, not just the overall conclusion. A report containing ten correct claims and three fabricated ones may still be unacceptable for research, journalism, policy analysis, or education.

Why Benchmark Scoring Often Misses the Problem
Traditional benchmarks are attractive because they are easy to score. A model’s answer can often be compared directly against a reference answer.
Long-form outputs are much harder to evaluate. There may be hundreds of factual assertions in a single response. Some may be partially correct. Others may depend on interpretation or source quality. Human review becomes expensive and time-consuming.
As a result, benchmark designers have historically favoured shorter tasks with clearer scoring rules. This improves comparability between models but can reduce visibility into long-answer failure modes. [arXiv]arxiv.orgFActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text GenerationMay 23, 2023…
A related issue is that many evaluations reward accuracy without sufficiently rewarding appropriate uncertainty. Research discussed by OpenAI argues that systems can receive better scores by guessing than by admitting they do not know an answer. While this issue appears in short-question benchmarks, its consequences become more serious in long-form writing because a model has many opportunities to insert unsupported details throughout an answer. [OpenAI]OpenAIwhy language models hallucinateSeptember 5, 2025…
What Long-Form Factuality Checks Try to Measure
Long-form factuality evaluations were developed to address exactly these shortcomings.
Instead of asking whether an entire response is correct, they examine the factual components within the response. The goal is to measure how many individual claims are supported by reliable evidence. This shifts attention from final-answer accuracy to claim-level reliability. [arXiv]arxiv.orgFActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text GenerationMay 23, 2023…
Several modern approaches focus on questions such as:
- How many factual statements appear in the answer?
- Which statements can be verified?
- Which statements lack support?
- How often does the model invent details?
- Does factual accuracy remain stable throughout a long response?
These evaluations attempt to capture the reality that users often consume AI outputs as complete documents rather than isolated answers. A model that answers trivia questions well but struggles to maintain factual consistency across hundreds of words may score differently when evaluated at this finer level of detail. [arXiv]arxiv.orgFActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text GenerationMay 23, 2023…
Atomic Facts Versus Whole Answers
One influential idea is the use of atomic facts: individual factual statements that can be checked independently.
For example, a biography might contain separate claims about a person’s birth date, education, career milestones, awards, and publications. Evaluating each claim separately provides a much clearer picture of reliability than assigning a single score to the entire biography.
This approach recognises that long-form factuality is fundamentally different from answering a trivia question. The challenge is not merely retrieving one fact correctly. It is sustaining accuracy across a network of related claims while avoiding unsupported additions. [arXiv]arxiv.orgFActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text GenerationMay 23, 2023…
Why This Matters for Understanding AI Reliability
When people see benchmark leaderboards, it is easy to assume that a higher score means consistently reliable answers. Long-form factuality research suggests the picture is more complicated.
A model can perform impressively on short factual tests while still making enough small mistakes in extended writing to create misleading reports. The mechanism is not mysterious: every additional claim introduces another opportunity for error, and conventional benchmarks often measure claims individually rather than collectively.
Understanding this distinction helps explain why benchmark progress and user experience sometimes diverge. Trivia-style tests reveal part of a model’s capabilities, but many real-world failures only become visible when the system must maintain factual accuracy across a long, evidence-heavy answer. [arXiv]arxiv.orgFActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text GenerationMay 23, 2023…

Amazon book picks
Further Reading
Books and field guides related to Why Long AI Answers Fail Differently. Use these as the next step if you want deeper reading beyond the article.
The Alignment Problem
Explains why benchmark performance can diverge from real-world reliability.
The AI Revolution in Medicine
Highlights verification needs for long-form AI-generated content.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: arxiv.org
Link: https://arxiv.org/abs/2305.14251Source snippet
FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text GenerationMay 23, 2023...
Published: May 23, 2023
-
Source: OpenAI
Title: why language models hallucinate
Link: https://openai.com/index/why-language-models-hallucinateSource snippet
September 5, 2025...
Published: September 5, 2025
-
Source: OpenAI
Title: Open AIHow confessions can keep language models honest | Open AI
Link: https://openai.com/ja-JP/index/how-confessions-can-keep-language-models-honest/Source snippet
How confessions can keep language models honest | OpenAI...
-
Source: OpenAI
Title: why language models hallucinate
Link: https://openai.com/fr-FR/index/why-language-models-hallucinate/Source snippet
comModèles de langage: aux origines des [hallucinations]({{ 'hallucinations/' | relative_url }}) | OpenAISeptember 5, 2025...
Published: September 5, 2025
Additional References
-
Source: papers.lunadong.com
Link: https://papers.lunadong.com/paper/4449Source snippet
Paper RadarFactScore: Fine-grained atomic evaluation of factual precision in long form text generation - Paper Summary...
-
Source: computerworld.com
Link: https://www.computerworld.com/article/4059383/openai-admits-ai-hallucinations-are-mathematically-inevitable-not-just-engineering-flaws.htmlSource snippet
admits AI hallucinations are mathematically inevitable, not just engineering flaws – ComputerworldSeptember 18, 2025...
Published: September 18, 2025
-
Source: youtube.com
Title: Lost in Stories: Consistency Bugs in Long Story Generation by LLMs
Link: https://www.youtube.com/watch?v=FQuPOLz_M1USource snippet
Long-form factuality in large language models - YouTube Long-form factuality in large language models - YouTube...
-
Source: youtube.com
Title: AI Evals 101: How to Evaluate LLMs, Agentic AI & Gen AI Systems
Link: https://www.youtube.com/watch?v=SYVPCsW4DWcSource snippet
Lost in Stories: Consistency Bugs in Long Story Generation by LLMs...
-
Source: youtube.com
Title: Episodic Memory for AI Agents: Why Retrieval Beats [Long Context]({{ ‘long-context-cost/’ | relative_url }})
Link: https://www.youtube.com/watch?v=CDT6tn3gmh0Source snippet
AI Evals 101: How to Evaluate LLMs, Agentic AI & GenAI Systems...
-
Source: youtube.com
Title: Long-form factuality in large language models
Link: https://www.youtube.com/watch?v=-NvVXaRrx6QSource snippet
Episodic Memory for AI Agents: Why Retrieval Beats Long Context...
-
Source: sciencestack.ai
Link: https://www.sciencestack.ai/paper/2310.00741Source snippet
FELM: Benchmarking Factuality Evaluation of Large Language Models (arXiv:2310.00741v2) - ScienceStack...
Topic Tree