Within Generation loop
Why the same prompt gets different answers
Decoding settings explain why the same chatbot can sound predictable, creative, cautious, or surprising without changing the model itself.
On this page
- Greedy decoding versus sampling
- How temperature changes token choice
- Why top p limits the candidate pool
Page outline Jump by section
Introduction
A chatbot does not reveal a pre-written answer. After calculating probabilities for possible next tokens, it must decide which token to output. That decision process is called decoding. Because there is often more than one plausible next token, different decoding settings can make the same model sound predictable, creative, cautious, repetitive, or surprising without changing the model itself. The underlying probabilities remain the same; decoding settings simply change how the system selects from those probabilities. [machinelearningplus]machinelearningplus.comDecoding Strategies — Greedy, BeamLLM Temperature, Top-P, and Top-K ExplainedTemperature, top-k, and top-p only reshape the probability distribution or…
 This is why the same prompt can produce different replies even when the model has not been retrained. The model generates a probability distribution over possible next tokens, and decoding determines how aggressively or conservatively it chooses from that distribution. [Hugging Face]huggingface.coHugging FaceGenerationThe class exposes generate, which can be used for: greedy decoding if num_beams=1 and do_sample=False; multinomia…
This is why the same prompt can produce different replies even when the model has not been retrained. The model generates a probability distribution over possible next tokens, and decoding determines how aggressively or conservatively it chooses from that distribution. [Hugging Face]huggingface.coHugging FaceGenerationThe class exposes generate, which can be used for: greedy decoding if num_beams=1 and do_sample=False; multinomia…
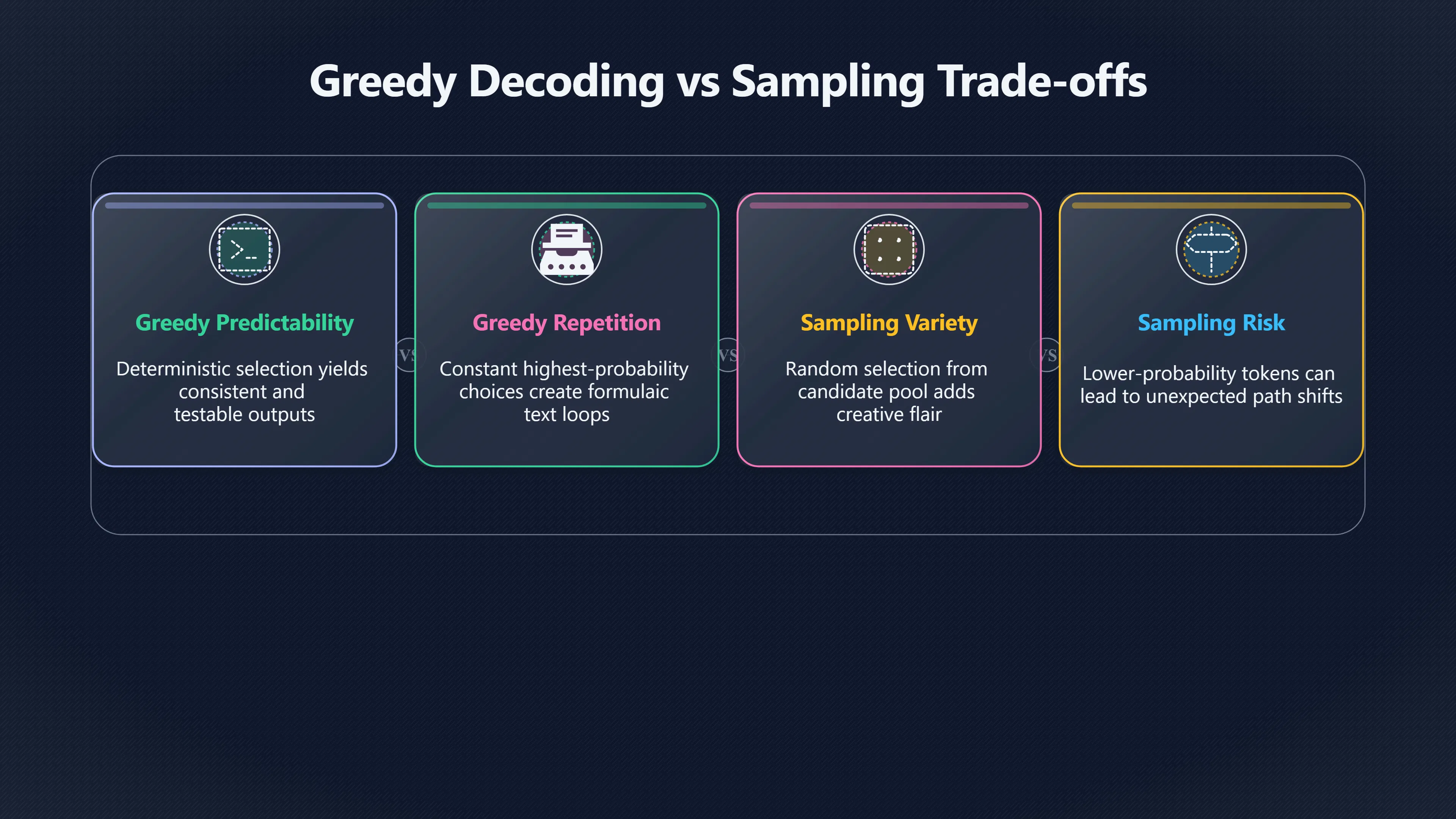
Greedy decoding versus sampling
The simplest decoding method is greedy decoding. At each step, the model chooses the token with the highest probability and moves on. If “Paris” has the highest probability after the phrase “The capital of France is”, greedy decoding selects “Paris” immediately. [Hugging Face]huggingface.coHugging FaceText generation strategiesThe default decoding strategy is greedy search, which is the simplest decoding strategy that picks…
Greedy decoding has an obvious advantage: it is deterministic. Given the same probabilities, it tends to produce the same output. This makes behaviour more predictable and easier to test. However, predictability comes with trade-offs. Researchers and practitioners have repeatedly observed that always selecting the most likely token can lead to repetitive, formulaic text, especially in longer generations. [Hugging Face+2arXiv]huggingface.coHugging FaceText generation strategiesThe default decoding strategy is greedy search, which is the simplest decoding strategy that picks…
Sampling takes a different approach. Instead of always choosing the highest-probability token, it treats the probability distribution as a pool of candidates and randomly selects among them according to their likelihoods. Highly probable tokens remain more likely to be chosen, but lower-probability alternatives can occasionally appear. [Hugging Face]huggingface.coHugging FaceGenerationThe class exposes generate, which can be used for: greedy decoding if num_beams=1 and do_sample=False; multinomia…
A useful way to think about the difference is:
- Greedy decoding: “Always pick the favourite.” [machinelearningplus.com]machinelearningplus.comDecoding Strategies — Greedy, BeamLLM Temperature, Top-P, and Top-K ExplainedTemperature, top-k, and top-p only reshape the probability distribution or…
- Sampling: “Usually pick the favourite, but sometimes choose another plausible option.”
Because every chosen token becomes part of the context for future predictions, even a small difference early in a response can send the generation down a completely different path. A single alternative word choice may lead to a different sentence, paragraph, or overall tone.
Research on neural text generation has shown that decoding strategy alone can substantially change output quality and diversity even when the language model itself remains unchanged. [arXiv+2OpenReview]arxiv.orgarXiv The Curious Case of Neural Text DegenerationarXiv The Curious Case of Neural Text Degeneration
How temperature changes token choice
Temperature is one of the most common decoding controls. It adjusts how sharply the model prefers high-probability tokens over lower-probability ones. [OpenAI Developer Community]community.openai.comOpen AI Developer Community Clarifications on setting temperature = 0· As T decreases, the probability differences between options are amplified. · At…Read more…
A low temperature exaggerates differences between probabilities. Tokens that are already likely become even more dominant, making the output more deterministic and conservative. At the extreme, temperature approaches behaviour similar to greedy decoding. [OpenAI Developer Community]community.openai.comOpen AI Developer Community Clarifications on setting temperature = 0· As T decreases, the probability differences between options are amplified. · At…Read more…
A high temperature flattens the probability distribution. Less likely tokens receive a greater chance of being selected, increasing variety and unpredictability. [OpenAI Developer Community]community.openai.comOpen AI Developer Community Clarifications on setting temperature = 0· As T decreases, the probability differences between options are amplified. · At…Read more…
Imagine the model assigns the following probabilities for the next token:
TokenProbability“good”60%“great”25%“excellent”10%“astonishing”5%
With a low temperature, “good” may dominate even more strongly. With a higher temperature, “excellent” or “astonishing” become more realistic possibilities.
This affects style as much as content. Lower temperatures often produce:
- More consistent wording
- More predictable phrasing
- Less variation between runs
Higher temperatures often produce:
- More varied vocabulary
- More creative phrasing
- Greater response diversity
- Increased risk of unusual or less appropriate choices
Importantly, temperature does not teach the model new facts or alter its knowledge. It changes how confidently the model follows its existing probability estimates. [machinelearningplus]machinelearningplus.comDecoding Strategies — Greedy, BeamLLM Temperature, Top-P, and Top-K ExplainedTemperature, top-k, and top-p only reshape the probability distribution or…

Why top-p limits the candidate pool
Temperature changes the shape of the probability distribution. Top-p, also called nucleus sampling, changes which tokens are eligible for selection in the first place. [OpenAI Developer Community]community.openai.comOpen AI Developer Community Mastering Temperature and Top_p in Chat GPT API· For example, if top_p is set to 0.1, GPT-3 will consider only the tokens that make up…Read more…
The model first sorts candidate tokens from most likely to least likely. It then keeps only the smallest set of tokens whose combined probability reaches a chosen threshold, such as 0.9 or 0.95. Everything outside that nucleus is discarded before sampling occurs. [Chip Huyen+2OpenAI Developer Community]huyenchip.comChip HuyenGeneration configurations: temperature, top-k, top-p, and…16 Jan 2024 — In top-p sampling, the model sums the probabilities…
For example: [community.openai.com]community.openai.comOpen AI Developer Community Mastering Temperature and Top_p in Chat GPT API· For example, if top_p is set to 0.1, GPT-3 will consider only the tokens that make up…Read more…
TokenProbabilityA50%B25%C15%D5%E5%
If top-p is set to 0.9, tokens A, B and C already account for 90% of the probability mass. Tokens D and E are excluded from consideration. Sampling then occurs only among A, B and C. [Chip Huyen]huyenchip.comChip HuyenGeneration configurations: temperature, top-k, top-p, and…16 Jan 2024 — In top-p sampling, the model sums the probabilities…
Unlike fixed-size approaches such as top-k sampling, nucleus sampling adapts to the situation. When the model is highly confident, the candidate pool may be very small. When uncertainty is greater, the pool expands automatically. [Hugging Face]huggingface.codecoding strategiesHugging FaceDecoding Strategies in Large Language ModelsOct 29, 2024 — Top-k sampling diversifies the text generation by randomly selecti…
This dynamic behaviour is one reason nucleus sampling became influential in language generation research. Studies found that restricting generation to the most plausible portion of the distribution could improve diversity while avoiding many low-quality choices from the long tail of unlikely tokens. [arXiv+2OpenReview]arxiv.orgarXiv The Curious Case of Neural Text DegenerationarXiv The Curious Case of Neural Text Degeneration
Why decoding settings matter more than many people realise
A common misconception is that different answers imply different knowledge inside the model. Often, the difference comes from decoding rather than from the model’s underlying understanding.
Consider a prompt asking for a story opening. The model may assign meaningful probability to several valid continuations. One decoding configuration might consistently choose the safest continuation, while another allows exploration of less likely but still reasonable alternatives. Both outputs arise from the same probability distribution. [machinelearningplus]machinelearningplus.comDecoding Strategies — Greedy, BeamLLM Temperature, Top-P, and Top-K ExplainedTemperature, top-k, and top-p only reshape the probability distribution or…
This means decoding settings influence:
- Creativity versus consistency
- Diversity versus predictability
- Repetition versus variation
- Exploration versus caution
Researchers studying text generation have shown that output quality can change dramatically depending on decoding choices. In some cases, poor decoding produces bland or repetitive text despite the model having learned rich language patterns during training. [arXiv+2Hugging Face]arxiv.orgarXiv The Curious Case of Neural Text DegenerationarXiv The Curious Case of Neural Text Degeneration
The key insight is that a language model does not produce a single inevitable answer. It produces a probability distribution over many possible next tokens. Decoding settings act as the rules for navigating that distribution. Change the rules, and the chatbot’s personality and behaviour can appear to change—even though the underlying model remains exactly the same. [machinelearningplus+2Hugging Face]machinelearningplus.comDecoding Strategies — Greedy, BeamLLM Temperature, Top-P, and Top-K ExplainedTemperature, top-k, and top-p only reshape the probability distribution or…

Amazon book picks
Further Reading
Books and field guides related to Why the same prompt gets different answers. Use these as the next step if you want deeper reading beyond the article.
Build a Large Language Model (From Scratch)
Covers token prediction and generation settings.
Natural Language Processing with Transformers
Includes generation strategies and model behavior.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: machinelearningplus.com
Title: Decoding Strategies — Greedy, Beam
Link: https://machinelearningplus.com/gen-ai/llm-temperature-top-p-top-k-explained/Source snippet
LLM Temperature, Top-P, and Top-K ExplainedTemperature, top-k, and top-p only reshape the probability distribution or...
-
Source: arxiv.org
Title: arXiv The Curious Case of Neural Text Degeneration
Link: https://arxiv.org/abs/1904.09751 -
Source: openreview.net
Link: https://openreview.net/forum?id=rygGQyrFvHSource snippet
The Curious Case of Neural Text Degenerationby A Holtzman · Cited by 4838 — Our approach avoids text degeneration by truncating the unrel...
-
Source: community.openai.com
Title: Open AI Developer Community Clarifications on setting temperature = 0
Link: https://community.openai.com/t/clarifications-on-setting-temperature-0/886447Source snippet
· As T decreases, the probability differences between options are amplified. · At...Read more...
-
Source: community.openai.com
Title: Open AI Developer Community Mastering Temperature and Top_p in Chat GPT API
Link: https://community.openai.com/t/cheat-sheet-mastering-temperature-and-top-p-in-chatgpt-api/172683Source snippet
· For example, if top_p is set to 0.1, GPT-3 will consider only the tokens that make up...Read more...
-
Source: arxiv.org
Title: arXiv Closing the Curious Case of Neural Text Degeneration
Link: https://arxiv.org/abs/2310.01693 -
Source: openreview.net
Link: https://openreview.net/pdf?id=rygGQyrFvHSource snippet
“unlikelihood loss”, which decreases training loss on repeated tokens and thus...Read more...
-
Source: OpenAI
Link: https://openai.com/[businessSource snippet
comHugging FaceConnect to the Hugging Face Hub in ChatGPT to explore models, datasets, and metadata and inspect options without manual br...
-
Source: ar5iv.labs.arxiv.org
Link: https://ar5iv.labs.arxiv.org/html/1904.09751Source snippet
arxiv.org[1904.09751] The Curious Case of Neural Text DegenerationOur approach avoids text degeneration by truncating the unreliable tail...
-
Source: arxiv.org
Link: https://arxiv.org/pdf/1904.09751Source snippet
The Curious Case of Neural Text Degenerationby A Holtzman · 2019 · Cited by 5127 — To address this we propose Nucleus Sampling, a simple...
-
Source: huggingface.co
Link: https://huggingface.co/docs/transformers/en/main_classes/text_generationSource snippet
Hugging FaceGenerationThe class exposes generate, which can be used for: greedy decoding if num_beams=1 and do_sample=False; multinomia...
-
Source: huggingface.co
Link: https://huggingface.co/docs/transformers/v4.44.0/en/generation_strategiesSource snippet
Hugging FaceText generation strategiesThe default decoding strategy is greedy search, which is the simplest decoding strategy that picks...
-
Source: huggingface.co
Title: Hugging Face Paper page
Link: https://huggingface.co/papers/1904.09751Source snippet
Paper page - The Curious Case of Neural Text DegenerationApr 22, 2019 — Despite considerable advancements with deep neural language model...
-
Source: huggingface.co
Link: https://huggingface.co/manueldeprada/samplingSource snippet
manueldeprada/samplingThe implementation supports both sampling and greedy decoding modes, with optional temperature scaling and top-k/to...
-
Source: huyenchip.com
Link: https://huyenchip.com/2024/01/16/sampling.htmlSource snippet
Chip HuyenGeneration configurations: temperature, top-k, top-p, and...16 Jan 2024 — In top-p sampling, the model sums the probabilities...
-
Source: huggingface.co
Title: decoding strategies
Link: https://huggingface.co/blog/mlabonne/decoding-strategiesSource snippet
Hugging FaceDecoding Strategies in Large Language ModelsOct 29, 2024 — Top-k sampling diversifies the text generation by randomly selecti...
-
Source: huggingface.co
Title: how to generate
Link: https://huggingface.co/blog/how-to-generateSource snippet
text: using different decoding methods for...Mar 1, 2020 — As ad-hoc decoding methods, top-p and top-K sampling seem to produce more flu...
-
Source: huggingface.co
Link: https://huggingface.co/Source snippet
The platform where the [machine learning]({{ 'machine-learning/' | relative_url }}) community collaborates on models, datasets, and applications. Explore AI Apps.Read more...
-
Source: discuss.huggingface.co
Title: model produces chaotic repetitive output when top k is higher how to fix this
Link: https://discuss.huggingface.co/t/model-produces-chaotic-repetitive-output-when-top-k-is-higher-how-to-fix-this/170966Source snippet
Produces Chaotic / Repetitive Output When `top_k`...Nov 29, 2025 — Hugging Face blog, “How to generate text: using different decoding me...
-
Source: huggingface.co
Link: https://huggingface.co/spacesSource snippet
SpacesSpaces · Reachy. new · Image Generation · Video Generation · Text Generation · Language Translation · Speech Synthesis · 3D Modelin...
-
Source: huggingface.co
Link: https://huggingface.co/learn/llm-course/ko/chapter1/1 -
Source: dictionary.cambridge.org
Link: https://dictionary.cambridge.org/dictionary/english/huggingSource snippet
English meaning - Cambridge DictionaryHUGGING definition: 1. present participle of hug 2. present participle of hug. Learn more...
-
Source: promptingguide.ai
Link: https://www.promptingguide.ai/introduction/settingsSource snippet
LLM Settings1 Feb 2026 — Top P - A sampling technique with temperature, called nucleus sampling, where you can control how deterministic...
-
Source: azure.microsoft.com
Title: hugging face on azure
Link: https://azure.microsoft.com/ko-kr/solutions/hugging-face-on-azureSource snippet
microsoft.comAzure의 Hugging Face - Huggingface TransformersHugging Face는 최신 기계 학습 모델을 빌드할 수 있는 최고의 오픈 소스 라이브러리인 Transformers를 만든 회사입니다. A...
-
Source: Wikipedia
Title: Hugging Face
Link: https://en.wikipedia.org/wiki/Hugging_FaceSource snippet
Hugging FaceHugging Face, Inc., is an American company based in New York City that develops computation tools for building application...
-
Source: incodom.kr
Title: Hugging Face
Link: https://incodom.kr/Hugging_FaceSource snippet
인코덤, 생물정보 전문위키Apr 12, 2026 — Hugging Face는 머신러닝 모델과 데이터셋을 공유·배포·운영할 수 있는 오픈소스 플랫폼이다. 학습이 끝난 AI 모델을 공유하는 GitHub에 해당한다고 이해...Read more...
Additional References
-
Source: apxml.com
Link: https://apxml.com/courses/prompt-engineering-llm-application-development/chapter-1-foundations-prompt-engineering/llm-temperature-parametersSource snippet
ApX Machine LearningUnderstanding LLM Temperature and Other ParametersLearn how parameters like temperature, top-p, and max tokens influe...
-
Source: aussieai.com
Link: https://www.aussieai.com/research/top-k-decodingSource snippet
Top-k and Top-p DecodingTop-p sampling aims to exclude such very unlikely words from the output by reducing the 50 tokens from top-k if t...
-
Source: machinelearning-basics.com
Link: https://machinelearning-basics.com/chatgpt-api-temperature-and-top_p/Source snippet
Hanane D.ChatGPT API Temperature and Top_pOpenAI [documentation]({{ 'paper-safety/' | relative_url }}) recommends modifying either temperature or top_p, but not both. Top_p samp...
-
Source: kunalganglani.com
Link: https://www.kunalganglani.com/learning-paths/ai-software-developer/aidev-llm-concepts-sampling/Source snippet
Temperature, top-p sampling & output qualityThis code's job is to demonstrate how to interact with a Large Language Model (LLM) and contr...
-
Source: medium.com
Link: https://medium.com/%401511425435311/understanding-openais-temperature-and-top-p-parameters-in-[language-modelsSource snippet
Understanding OpenAI's “Temperature” and “Top_p”...“Temperature” and “top_p” are crucial tools for shaping language generation in models...
-
Source: iclr.cc
Link: https://iclr.cc/virtual_2020/poster_rygGQyrFvH.html -
Source: reddit.com
Title: I understand that both are related to sampling, but why are there two parameters
Link: https://www.reddit.com/r/GPT3/comments/qujerp/what_is_the_difference_between_temperature_and/Source snippet
What is the difference between temperature and top p...Hi, I'm interested in hearing how you interpret these model parameters...
-
Source: mention.network
Title: demystifying ai model parameters a guide to temperature top p and more
Link: https://mention.network/learn/demystifying-ai-model-parameters-a-guide-to-temperature-top-p-and-more/Source snippet
Demystifying AI Model Parameters13 Aug 2025 — While temperature affects the entire probability distribution, "top_p" (also known as nucle...
-
Source: tomarcher.io
Title: Signal & Syntax Temperature and Top-P: The Creativity Knobs
Link: https://tomarcher.io/posts/temperature-top-p-creativity-knobs/Source snippet
Signal & SyntaxTemperature and Top-P: The Creativity Knobs - Signal & Syntax24 Dec 2025 — This post explores the mathematical foundations...
-
Source: dsba.snu.ac.kr
Link: https://dsba.snu.ac.kr/?kboard_content_redirect=1345Source snippet
snu.ac.kr[Paper Review] The Curious Case of Neural Text DegenerationOct 12, 2020 — [Paper Review] The Curious Case of Neural Text Degener...
Topic Tree