Within Transformer shift
Why a translation model powered chatbots
A model built for translation became the backbone of chatbots because its architecture suited large-scale self-supervised text prediction.
On this page
- What the original Transformer paper set out to solve
- Why translation efficiency transferred to language modelling
- How next token prediction became a general engine
Page outline Jump by section
Introduction
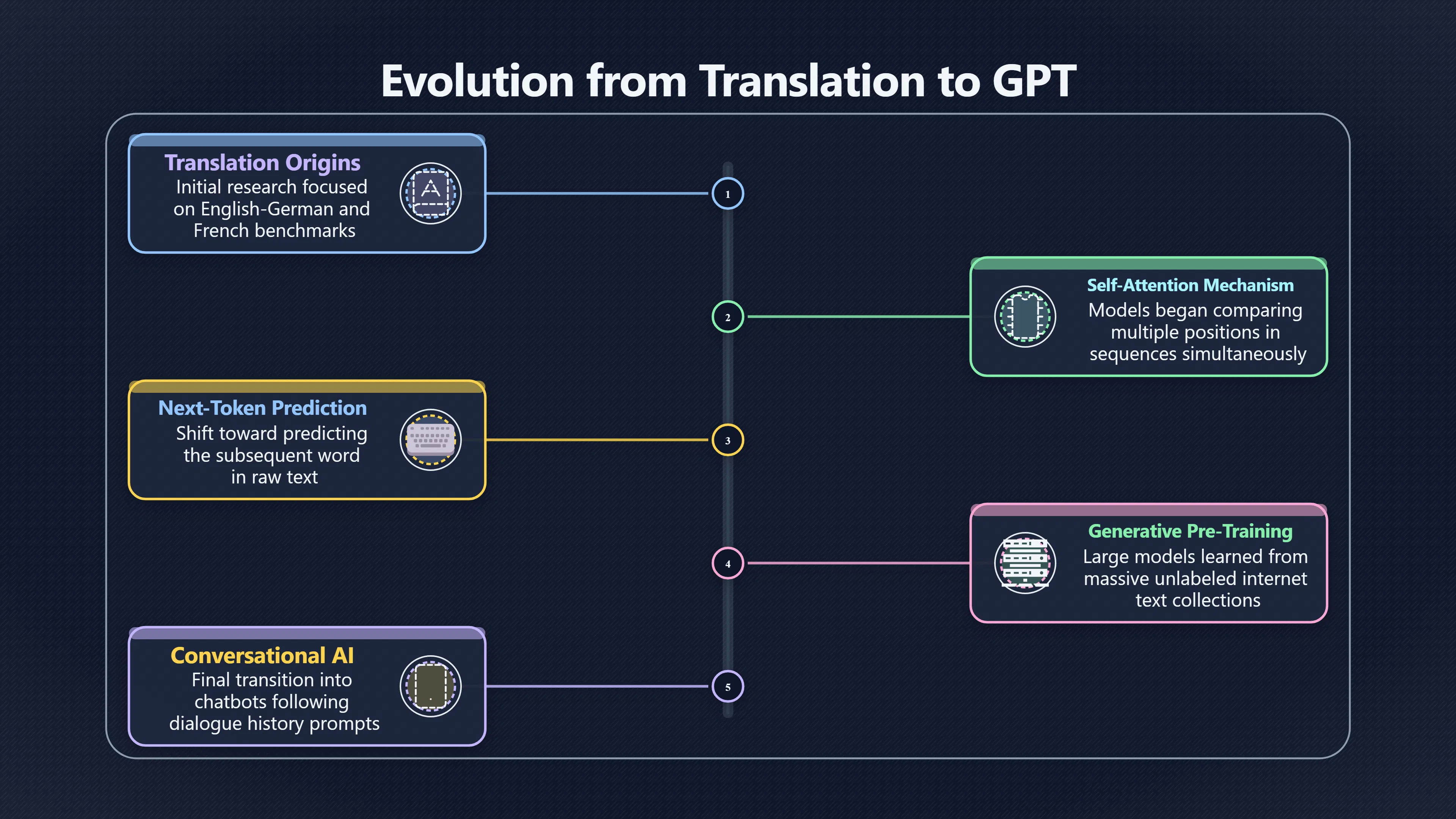
The Transformer was not originally introduced as a chatbot architecture. The 2017 paper Attention Is All You Need was aimed primarily at machine translation: converting sentences from one language into another more accurately and efficiently than earlier neural networks. Yet within a few years, the same architectural ideas became the foundation of systems such as GPT, ChatGPT, Claude and many other large language models. The reason was not that researchers set out to build conversational AI. Rather, the Transformer turned out to be exceptionally well suited to a different problem: predicting the next piece of text in enormous collections of unlabeled language data. Once that connection became clear, a translation breakthrough became the infrastructure behind modern chatbots. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…

What the original Transformer paper set out to solve
When the Transformer was introduced in 2017, the dominant challenge was improving sequence-to-sequence tasks such as translation. Existing systems typically used recurrent neural networks (RNNs) or convolutional architectures that processed language step by step. These methods could work well, but they were difficult to parallelise and often struggled to capture relationships between words that were far apart in a sentence. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
The Transformer replaced those mechanisms with self-attention. Instead of reading words strictly one after another, it allowed the model to compare many positions in a sequence simultaneously. The original paper demonstrated state-of-the-art results on English–German and English–French translation benchmarks while requiring significantly less training time. Translation was the headline application, but the underlying innovation was a more general way of processing sequences. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
This distinction matters historically. The paper did not claim to have invented a conversational agent. It introduced a flexible architecture for handling language relationships. Translation happened to be the first major demonstration that showed the approach worked at scale. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
Why translation efficiency transferred to language modelling
The qualities that made Transformers effective for translation also made them attractive for language modelling.
Translation requires understanding how words relate across an entire sentence or paragraph. A model translating a phrase from English to French may need to connect a pronoun with a noun that appeared much earlier. Self-attention provided a direct mechanism for making those connections. The same capability is useful when predicting the next word in a passage of text. In both cases, the model must identify which earlier tokens matter most for the current prediction. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
An even more important advantage was computational. Because Transformer computations can be parallelised far more effectively than recurrent networks, researchers could train much larger models on much larger datasets. That scalability became crucial once the field began exploring self-supervised learning, where models learn from vast quantities of ordinary text rather than manually labelled examples. [arXiv+2LessWrong]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
Machine translation datasets are limited in size because every example requires paired human translations. By contrast, internet text is abundant. A next-token objective can generate training targets automatically: every word in a document becomes a prediction task for the model. The Transformer’s efficiency allowed researchers to exploit this abundance in ways that earlier architectures struggled to match. [LessWrong+2OpenAI]lesswrong.comLess Wrong How did 'large' language models get that way?The role of…3 May 2026 — How transformers overcame a scaling problem. The benefit of self-supervised learning — a huge, largely automa…
In retrospect, the architecture’s biggest contribution was not merely improving translation quality. It made large-scale learning from raw text practical.

How next-token prediction became a general engine
The turning point came when researchers realised that the Transformer could be adapted from translation into pure language modelling.
In 2018, OpenAI’s first GPT model used a Transformer decoder architecture trained with a simple objective: predict the next token in a sequence. Rather than learning from specialised translation pairs, the model learned from large collections of text. After this pre-training stage, it could be adapted to a variety of downstream tasks. [OpenAI CDN+2OpenAI]cdn.openai.comOpenAI CDNImproving Language Understanding by Generative Pre-…by A Radford · Cited by 18947 — In our experiments, we use a multi-layer…
This shift changed the economics of AI development. Instead of building separate models for translation, summarisation, question answering and other tasks, researchers could train a single large model on general text and then reuse it in many contexts. The same prediction engine often acquired capabilities that had not been explicitly programmed. [OpenAI]OpenAIImproving language understanding with unsupervised…Jun 11, 2018 — This provides some insight into why generative pre-training can impr…
Several factors made the combination especially powerful:
- Self-supervised data availability: almost any text source could be used for training because the next-token target is generated automatically. [OpenAI]OpenAIImproving language understanding with unsupervised…Jun 11, 2018 — This provides some insight into why generative pre-training can impr…
- Architectural scalability: Transformer-based systems continued improving as parameter counts, data volumes and computing resources increased. [arXiv]arxiv.orgarXiv OPT: Open Pre-trained Transformer Language ModelsOPT: Open Pre-trained Transformer Language ModelsMay 2, 2022…
- Flexible task transfer: many language tasks can be expressed as text prediction, allowing one architecture to support numerous applications. [OpenAI CDN]cdn.openai.comlanguage models are unsupervised multitask learnersOpenAI CDNLanguage Models are Unsupervised Multitask Learnersby A Radford · Cited by 24907 — Our largest model, GPT-2, is a 1.5B paramete…
- Long-range context handling: self-attention allowed models to use information spread across broader contexts than many earlier systems. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
The result was a gradual transition from task-specific language systems to increasingly general language models.
Why chatbots emerged from language models rather than translation systems
A translation system has a narrow goal: transform one sequence into another language. A chatbot faces a broader challenge: continue a conversation, answer questions, follow instructions and generate new text.
Once large Transformer models became good at predicting text, conversation could be represented as another text-generation problem. A prompt containing dialogue history became the context, and the model’s reply became the next sequence to generate. From the model’s perspective, a conversation is simply another pattern in language. [Amazon Web Services, Inc.]aws.amazon.comWeb Services, Inc.What is GPT AI?Generative Pre-Trained Transformers…GPT models give applications the ability to create human-like text and content (images, music, and…
This was a crucial conceptual shift. Researchers no longer needed a specialised chatbot architecture. They could take a general-purpose language model and train or fine-tune it on conversational data. The chatbot behaviour emerged from the same prediction machinery originally developed for language modelling. [OpenAI CDN]cdn.openai.comlanguage models are unsupervised multitask learnersOpenAI CDNLanguage Models are Unsupervised Multitask Learnersby A Radford · Cited by 24907 — Our largest model, GPT-2, is a 1.5B paramete…
The lineage remains visible in the name GPT itself: Generative Pre-Trained Transformer. The architecture traces back to a translation paper, but its defining use became generation rather than translation. [OpenAI CDN]cdn.openai.comOpenAI CDNImproving Language Understanding by Generative Pre-…by A Radford · Cited by 18947 — In our experiments, we use a multi-layer…

The historical lesson: architecture mattered more than the original task
Many influential technologies begin in one domain and become transformative elsewhere. The Transformer is a prominent example. Its creators designed it to improve sequence transduction tasks such as machine translation, yet the most consequential impact came from a different use case entirely. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
What transferred was not the translation objective itself. It was the architecture’s ability to model relationships across text efficiently, scale to enormous datasets and exploit self-supervised learning. Those properties aligned almost perfectly with next-token prediction. Once researchers combined the two, the path from translation research to conversational AI became clear. [arXiv+2OpenAI CDN]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
Modern chatbots therefore owe their existence to an unexpected historical transition: a model built to translate languages became the engine for predicting language, and that prediction engine became the foundation of conversational artificial intelligence. [arXiv+2OpenAI CDN]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
Amazon book picks
Further Reading
Books and field guides related to Why a translation model powered chatbots. Use these as the next step if you want deeper reading beyond the article.
Understanding Deep Learning
Helps readers understand architectures and concepts that underpin Transformers.
Deep Learning
Rating: 3.5/5 from 6 Google Books ratings
Explains sequence models, neural networks, and the foundations that led to Transformer-era language models.
Hands-on Machine Learning with Scikit-Learn, Keras, and Tenso...
Provides accessible context for modern deep learning and language-model development.
Natural Language Processing with Transformers
Directly covers Transformer models and modern NLP workflows.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: arxiv.org
Title: arXiv Attention Is All You Need
Link: https://arxiv.org/abs/1706.03762Source snippet
Attention Is All You NeedJune 12, 2017...
Published: June 12, 2017
-
Source: lesswrong.com
Title: Less Wrong How did ‘large’ language models get that way?
Link: https://www.lesswrong.com/posts/gcKhnqysxj9bBvbWD/how-did-large-language-models-get-that-way-the-role-ofSource snippet
The role of...3 May 2026 — How transformers overcame a scaling problem. The benefit of self-supervised learning — a huge, largely automa...
Published: May 2026
-
Source: OpenAI
Link: https://openai.com/index/language-unsupervised/Source snippet
Improving language understanding with unsupervised...Jun 11, 2018 — This provides some insight into why generative pre-training can impr...
-
Source: cdn.openai.com
Link: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdfSource snippet
OpenAI CDNImproving Language Understanding by Generative Pre-...by A Radford · Cited by 18947 — In our experiments, we use a multi-layer...
-
Source: cdn.openai.com
Title: language models are unsupervised multitask learners
Link: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdfSource snippet
OpenAI CDNLanguage Models are Unsupervised Multitask Learnersby A Radford · Cited by 24907 — Our largest model, GPT-2, is a 1.5B paramete...
-
Source: arxiv.org
Title: arXiv OPT: Open Pre-trained Transformer Language Models
Link: https://arxiv.org/abs/2205.01068Source snippet
OPT: Open Pre-trained Transformer Language ModelsMay 2, 2022...
Published: May 2, 2022
-
Source: aws.amazon.com
Title: Web Services, Inc.What is GPT AI?
Link: https://aws.amazon.com/what-is/gpt/Source snippet
Generative Pre-Trained Transformers...GPT models give applications the ability to create human-like text and content (images, music, and...
-
Source: OpenAI
Link: https://openai.com/Source snippet
comOpenAI | Research & DeploymentWe believe our research will eventually lead to artificial general intelligence, a system that can solve...
-
Source: OpenAI
Link: https://openai.com/gpt-5/Source snippet
comGPT-5 is hereGPT‑5 excels at writing, research, analysis, coding, and problem-solving. It delivers more accurate, professional respons...
-
Source: arxiv.org
Link: https://arxiv.org/pdf/1810.04805Source snippet
1810.04805v2 [cs.CL] 24 May 201924 May 2019 — For example, in OpenAI GPT, the authors use a left-to- right architecture, where ever...
Published: May 2019
-
Source: Wikipedia
Title: Generative pre-trained transformer
Link: https://en.wikipedia.org/wiki/Generative_pre-trained_transformerSource snippet
Generative pre-trained transformerOpenAI was the first to apply generative pre-training to the transformer architecture, introducing t...
-
Source: Wikipedia
Title: Open AI
Link: https://en.wikipedia.org/wiki/OpenAISource snippet
OpenAIOpenAI Group PBC, doing [business]({{ 'business-adoption/' | relative_url }}) as OpenAI, is an American artificial intelligence (AI) research organization headquartered in S...
-
Source: dmqa.korea.ac.kr
Title: 20181123 강현구 Attention is All You Need 배포용
Link: https://dmqa.korea.ac.kr/uploads/seminar/20181123%EA%B0%95%ED%98%84%EA%B5%AC_Attention-is-All-You-Need%EB%B0%B0%ED%8F%AC%EC%9A%A9.pdfSource snippet
Transformer: Attention is All You NeedNov 23, 2019 — Effective approaches to attention-based neural machine translation...
-
Source: medium.com
Title: Attention Is All You Need!
Link: https://medium.com/data-science-collective/attention-is-all-you-need-661cb8db5f21Source snippet
Demystifying the Transformer…Self-attention is the cornerstone of the Transformer architecture — the mechanism that allows the model to f...
-
Source: medium.com
Link: https://medium.com/dataseries/openai-gpt-generative-pre-training-for-language-understanding-bbbdb42b7ff4Source snippet
OpenAI GPT: Generative Pre-Training for Language...The Architecture. Open AI GPT uses a Transformer Decoder architecture as opposed to B...
-
Source: ktvu.com
Link: https://www.ktvu.com/video/fmc-gptplu2br6m5qyw0 -
Source: nanonets.com
Title: attention is all you need
Link: https://nanonets.com/chat-pdf/attention-is-all-you-needSource snippet
(PDF) Attention is All you Need (2017) | Chat PDFThe paper "Attention Is All You Need" introduces the Transformer, a revolutionary neural...
-
Source: foxbusiness.com
Link: https://www.foxbusiness.com/technology/openai-backs-creation-global-ai-governance-body-led-u-s-would-include-china-member -
Source: letsdatascience.com
Title: Open A I Backs U.S.-Led Global AI Governance Including China
Link: https://letsdatascience.com/news/openai-backs-us-led-global-ai-governance-including-china-b188ac21 -
Source: ibm.com
Link: https://www.ibm.com/think/topics/gptSource snippet
What is GPT (generative pretrained transformer)?AI research firm OpenAI introduced the first GPT model, dubbed GPT-1, in 2018. Since then...
-
Source: en.bioerrorlog.work
Title: openai first gpt paper
Link: https://en.bioerrorlog.work/entry/openai-first-gpt-paper
Additional References
-
Source: indrasol.com
Link: https://indrasol.com/resources/whitepaper/advancements-in-transformer-architectures-for-large-language-model-from-bert-to-gpt-3-and-beyondSource snippet
AI, Cloud & Data Engineering ExpertsThe scalability of transformer architectures provides possibilities for even larger and more powerful...
-
Source: Wikipedia
Link: https://en.wikipedia.org/wiki/Attention_Is_All_You_NeedSource snippet
Attention Is All You NeedThe paper introduced a new [deep learning]({{ 'deep-learning/' | relative_url }}) architecture known as the transformer, based on the attention mechan...
-
Source: research.google
Link: https://research.google/blog/transformer-a-novel-neural-network-architecture-for-language-understanding/Source snippet
Google ResearchTransformer: A Novel Neural Network Architecture for...In our paper, we show that the Transformer outperforms both recurr...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/transformers-self-attention-rise-self-supervised-learning-jha-jwfbfSource snippet
Unlocking the Potential of Versatile AI ModelsThe synergy between the transformer architecture and self-supervised learning has been a dr...
-
Source: sebastianraschka.com
Link: https://sebastianraschka.com/books/ml-q-and-ai-chapters/ch08/Source snippet
Sebastian Raschka, PhDMachine Learning Q and AIThe self-attention mechanism found in transformers is one of the key design components tha...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/vikashkodati_the-paper-attention-is-all-you-need-presents-activity-7260335194543423489-pulA -
Source: semanticscholar.org
Link: https://www.semanticscholar.org/paper/Attention-is-All-you-Need-Vaswani-Shazeer/204e3073870fae3d05bcbc2f6a8e263d9b72e776 -
Source: linkedin.com
Link: https://www.linkedin.com/posts/alexxubyte_the-most-important-paper-attention-is-all-activity-7404924500187865088-7LDpSource snippet
Transformer Model Explained: Attention Is All You NeedThe transformer architecture, introduced in the 2017 paper "Attention Is All You Ne...
-
Source: towardsai.net
Link: https://towardsai.net/p/[machine-learningSource snippet
A Deep Dive into the Revolutionary Transformer Architecture10 Apr 2025 — This paper introduced the Transformer architecture, a novel appr...
-
Source: researchgate.net
Title: 394522965 Transformer Architecture Evolution in Large Language Models A Survey
Link: https://www.researchgate.net/publication/394522965_Transformer_Architecture_Evolution_in_Large_Language_Models_A_SurveySource snippet
Transformer Architecture Evolution in Large Language...17 Aug 2025 — We examine architectural innovations including attention mechanisms...
Topic Tree