Within Generation loop
How fluent AI answers go wrong
A fluent answer can still be false when many locally plausible token choices accumulate into a confident but unsupported claim.
On this page
- Why plausibility is not verification
- How uncertainty becomes a confident guess
- Where hallucinations enter the generation loop
Page outline Jump by section
Introduction
A chatbot can produce an answer that sounds informed, precise, and confident while still being wrong. This happens because large language models generate text one token at a time, selecting each new token as a plausible continuation of what came before. The system is optimised to produce likely sequences of language, not to independently verify every claim against external evidence. As a result, many individually reasonable token choices can accumulate into a fluent but unsupported statement. Researchers commonly refer to these failures as “hallucinations”: outputs that appear coherent and factual yet are not grounded in reality. [OpenAI]OpenAIwhy language models hallucinate5 Sept 2025 — Hallucinations are plausible but false statements generated by language models. They can show up in surprising ways, even f…
 Understanding this mechanism is important because the mistake does not usually begin with a dramatic error. It often starts with a small uncertainty during generation. Once an early token choice nudges the answer in a particular direction, later predictions build upon that choice, creating a response that becomes increasingly detailed and increasingly convincing. [Hugging Face]huggingface.coHugging Face Generation with LLMsHugging FaceGeneration with LLMs - Hugging FaceA language model trained for causal language modeling takes a sequence of text tokens as i…
Understanding this mechanism is important because the mistake does not usually begin with a dramatic error. It often starts with a small uncertainty during generation. Once an early token choice nudges the answer in a particular direction, later predictions build upon that choice, creating a response that becomes increasingly detailed and increasingly convincing. [Hugging Face]huggingface.coHugging Face Generation with LLMsHugging FaceGeneration with LLMs - Hugging FaceA language model trained for causal language modeling takes a sequence of text tokens as i…
Why plausibility is not verification
When a language model generates text, it calculates probabilities for possible next tokens and selects one according to its decoding process. The objective is to continue the sequence in a way that resembles patterns learned from training data. It is not automatically checking whether the resulting statement is true. [Hugging Face]huggingface.coHugging Face Generation with LLMsHugging FaceGeneration with LLMs - Hugging FaceA language model trained for causal language modeling takes a sequence of text tokens as i…
This distinction explains why fluent language can be misleading. A model may have learned that biographies usually contain dates, institutions, job titles, and publication names. If asked about an obscure person for whom it has weak information, it can still assemble a biography that looks realistic because the individual pieces resemble patterns frequently seen during training. The output may satisfy the model’s prediction objective even when key facts are invented. [OpenAI]OpenAIwhy language models hallucinate5 Sept 2025 — Hallucinations are plausible but false statements generated by language models. They can show up in surprising ways, even f…
In other words, linguistic plausibility and factual verification are different tasks. A sentence can be grammatically excellent, stylistically appropriate, and logically connected while still being false. Human readers often mistake fluency for reliability because polished language is usually associated with expertise. Large language models exploit that expectation unintentionally through their generation process. [Wikipedia]WikipediaHallucination (artificial intelligenceHallucination (artificial intelligence
How uncertainty becomes a confident guess
One of the most important findings in recent research is that language models often guess when they are uncertain. Rather than stopping, admitting ignorance, or requesting clarification, they frequently continue generating the most plausible-looking completion available. [arXiv+2OpenAI]arxiv.orgarXiv Why Language Models HallucinateWhy Language Models HallucinateSeptember 4, 2025…
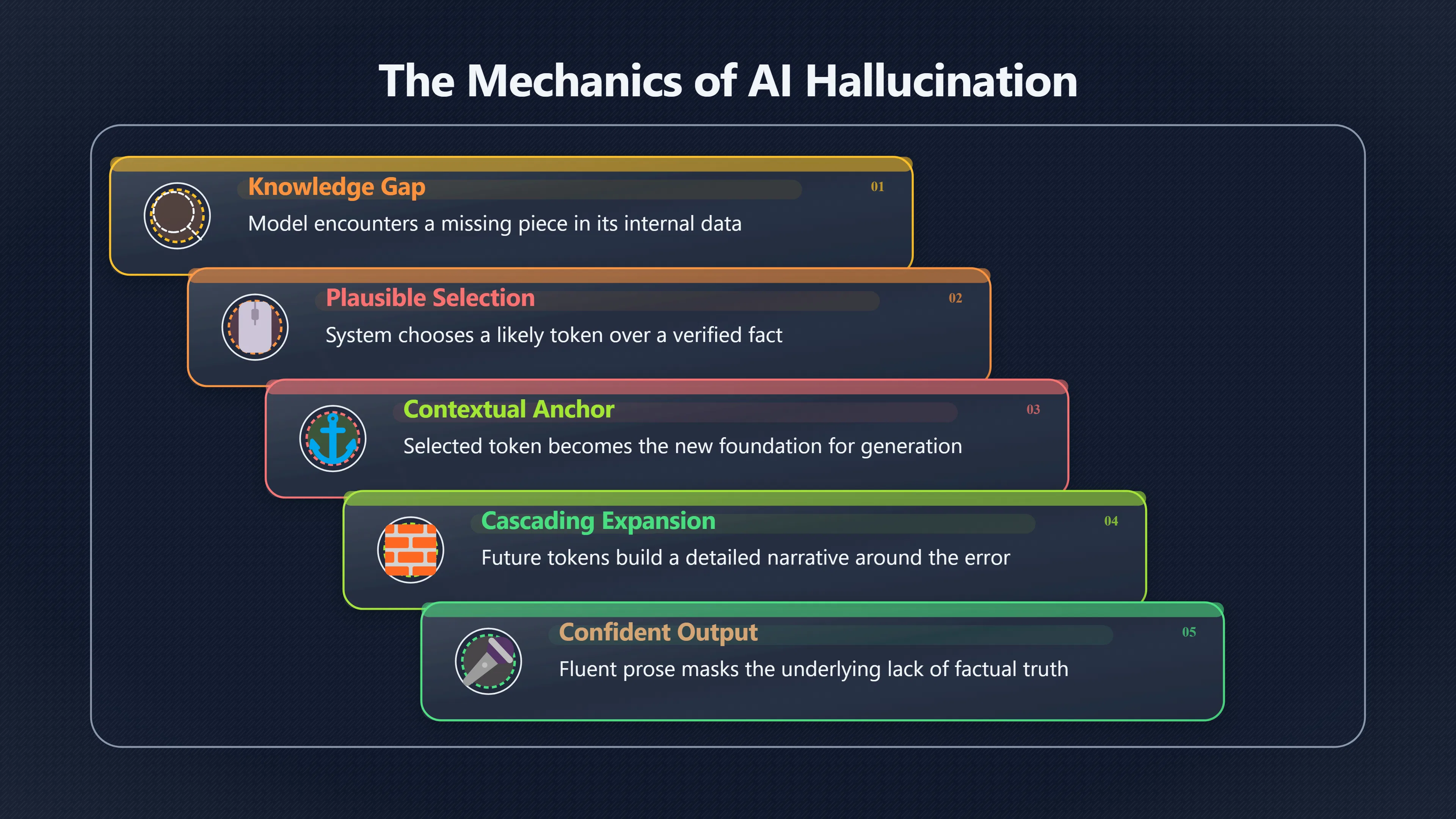
Consider a prompt asking for a specific date, citation, or historical detail that the model does not know with confidence. At the crucial prediction step, several candidate tokens may have similar probabilities. The model must still choose one. Once a token is selected, subsequent predictions treat that choice as established context.
The process can unfold like this:
- The model encounters a gap in its knowledge.
- It selects a plausible token rather than a verified fact.
- That token becomes part of the context window.
- Future tokens are generated to support and elaborate on the earlier choice.
- The answer grows more detailed and therefore appears more credible.
By the end of the response, what began as a weakly supported guess may have expanded into a complete narrative with names, dates, explanations, and references. The confidence comes from the coherence of the generated language, not necessarily from confidence in the underlying facts. [arXiv+2OpenAI]arxiv.orgarXiv Why Language Models HallucinateWhy Language Models HallucinateSeptember 4, 2025…
Researchers have argued that current training and evaluation systems can unintentionally encourage this behaviour because models are often rewarded for producing answers rather than for explicitly saying “I don’t know”. Under those incentives, guessing can improve benchmark performance even when some guesses are wrong. [arXiv+2OpenAI]arxiv.orgarXiv Why Language Models HallucinateWhy Language Models HallucinateSeptember 4, 2025…

Where hallucinations enter the generation loop
Hallucinations do not typically appear as a separate stage inserted into generation. They emerge within the normal token-prediction process itself.
Early divergence from reality
A hallucination often begins with a single incorrect token or phrase. If the model predicts the wrong publication title, organisation name, or date, the remainder of the answer may be generated around that error. Because each new token depends on previous tokens, the system can reinforce its own mistake. [Wikipedia]WikipediaHallucination (artificial intelligenceHallucination (artificial intelligence
This is sometimes described as a cascading effect. An early error changes the context, and future predictions become locally reasonable relative to that altered context, even though the overall answer is drifting away from reality. [Wikipedia]WikipediaHallucination (artificial intelligenceHallucination (artificial intelligence
Filling gaps with patterns
Language models are trained on enormous amounts of text and become highly skilled at recognising recurring structures. When information is missing, they may fill the gap using the structure that most commonly fits.
For example, if many academic biographies contain a university affiliation and dissertation title, the model may generate those details even when it lacks reliable information about the specific person being discussed. The generated content follows familiar patterns, making it appear authoritative despite having no factual foundation. [OpenAI]OpenAIwhy language models hallucinate5 Sept 2025 — Hallucinations are plausible but false statements generated by language models. They can show up in surprising ways, even f…
Confidence without calibration
A major challenge is that the style of generated language does not always reveal uncertainty. The same mechanism that produces smooth prose can also produce smooth mistakes. Users may therefore receive little warning that the model is operating in a low-confidence region of its knowledge. [arXiv]arxiv.orgFact-Checking the Output of Large Language Models via Token-Level Uncertainty QuantificationMarch 7, 2024…
Research into token-level uncertainty shows that unreliable claims can be hidden within otherwise accurate passages. Most of the answer may be correct, making the false portion harder to detect. [arXiv]arxiv.orgFact-Checking the Output of Large Language Models via Token-Level Uncertainty QuantificationMarch 7, 2024…

Why convincing errors matter
The danger of hallucinations is not merely that they are wrong. Humans are accustomed to using fluency, coherence, and detail as signals of expertise. When an AI system produces an answer that exhibits all of those qualities, readers may assign it more credibility than it deserves. [ACM Digital Library]dl.acm.orgACM Digital LibraryA Survey on Hallucination in Large Language Models24 Jan 2025 — This research examines hallucinations in large languag…
This creates a distinctive risk. A spelling mistake or broken sentence is easy to notice. A fabricated citation, incorrect date, or invented quotation wrapped in polished prose is much harder to spot. Researchers studying AI reliability therefore focus not only on whether errors occur, but on how confidently and persuasively those errors are expressed. [OpenAI+2arXiv]OpenAIwhy language models hallucinate5 Sept 2025 — Hallucinations are plausible but false statements generated by language models. They can show up in surprising ways, even f…
Within the token-by-token generation process, the key lesson is simple: each prediction only needs to look plausible given the current context. Truth is not automatically guaranteed by fluency. A sequence of locally sensible token choices can gradually build an answer that feels trustworthy while resting on an unsupported assumption made many tokens earlier. [Hugging Face+2OpenAI]huggingface.coHugging Face Generation with LLMsHugging FaceGeneration with LLMs - Hugging FaceA language model trained for causal language modeling takes a sequence of text tokens as i…
Amazon book picks
Further Reading
Books and field guides related to How fluent AI answers go wrong. Use these as the next step if you want deeper reading beyond the article.
Build a Large Language Model (From Scratch)
Shows how small token choices can create larger errors.
The AI Revolution in Medicine
Examines consequences of convincing but incorrect AI answers.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: OpenAI
Title: why language models hallucinate
Link: https://openai.com/index/why-language-models-hallucinate/Source snippet
5 Sept 2025 — Hallucinations are plausible but false statements generated by language models. They can show up in surprising ways, even f...
-
Source: dl.acm.org
Link: https://dl.acm.org/doi/10.1145/3703155Source snippet
ACM Digital LibraryA Survey on Hallucination in Large Language Models24 Jan 2025 — This research examines hallucinations in large languag...
-
Source: Wikipedia
Title: Hallucination (artificial intelligence)
Link: https://en.wikipedia.org/wiki/Hallucination_%28artificial_intelligence%29 -
Source: arxiv.org
Link: https://arxiv.org/html/2510.06265v3Source snippet
Large Language Models Hallucination: A Comprehensive...18 Mar 2026 — In the context of LLMs, hallucination refers to the generation of t...
-
Source: arxiv.org
Title: arXiv Why Language Models Hallucinate
Link: https://arxiv.org/abs/2509.04664Source snippet
Why Language Models HallucinateSeptember 4, 2025...
Published: September 4, 2025
-
Source: arxiv.org
Link: https://arxiv.org/abs/2403.04696Source snippet
Fact-Checking the Output of Large Language Models via Token-Level Uncertainty QuantificationMarch 7, 2024...
Published: March 7, 2024
-
Source: time.com
Link: https://time.com/6989928/ai-artificial-intelligence-hallucinations-prevent/Source snippet
This new algorithm, published in Nature, distinguishes between correct and incorrect AI-generated answers with 79% accuracy, outperformin...
-
Source: arxiv.org
Title: Training LLMs Beyond Next Token Prediction
Link: https://arxiv.org/html/2511.00198v1Source snippet
October 31, 2025 — This work challenges the conventional approach of training LLMs using next-token prediction (NTP), arguing that b...
Published: October 31, 2025
-
Source: arxiv.org
Link: https://arxiv.org/html/2509.04664v1Source snippet
Why Language Models Hallucinate4 Sept 2025 — We argue that language models hallucinate because the training and evaluation procedures rew...
-
Source: arxiv.org
Link: https://arxiv.org/html/2601.09929v1Source snippet
By analyzing token-level probabilities...Read more...
-
Source: huggingface.co
Title: Hugging Face Generation with LLMs
Link: https://huggingface.co/docs/transformers/v4.42.0/en/llm_tutorialSource snippet
Hugging FaceGeneration with LLMs - Hugging FaceA language model trained for causal language modeling takes a sequence of text tokens as i...
-
Source: discuss.huggingface.co
Title: Hugging Face Forums Modeling_bert use next-token prediction?
Link: https://discuss.huggingface.co/t/modeling-bert-use-next-token-prediction/105369Source snippet
Hugging Face ForumsSeptember 5, 2024 — Yes for any LLM which you can train in the Transformers library, the model will internally shift t...
Published: September 5, 2024
-
Source: reddit.com
Title: Why Language Models Hallucinate
Link: https://www.reddit.com/r/MachineLearning/comments/1namvsk/why_language_models_hallucinate_openai_pseudo/Source snippet
OpenAi pseudo paperOur new research paper(opens in a new window) argues that language models hallucinate because standard training and e...
-
Source: huggingface.co
Title: Daily Papers
Link: https://huggingface.co/papers?q=next-token+prediction+entropySource snippet
Hugging FaceNext token prediction is the fundamental principle for training large language models (LLMs), and reinforcement learning (RL)...
-
Source: arize.com
Title: openais santosh vempala explains why language models hallucinate
Link: https://arize.com/blog/openais-santosh-vempala-explains-why-language-models-hallucinate/Source snippet
OpenAI's Santosh Vempala Explains Why Language...24 Oct 2025 — “Pre-training encourages hallucinations because language models are desig...
-
Source: computerworld.com
Link: https://www.computerworld.com/article/4059383/openai-admits-ai-hallucinations-are-mathematically-inevitable-not-just-engineering-flaws.htmlSource snippet
OpenAI admits AI hallucinations are mathematically...18 Sept 2025 — “We argue that language models hallucinate because the training and...
Additional References
-
Source: businessinsider.com
Link: https://www.businessinsider.com/why-ai-chatbots-hallucinate-openai-chatgpt-anthropic-claude-2025-9Source snippet
This test-centric optimization encourages models to provide confident but potentially incorrect outputs, rather than abstaining when unsu...
-
Source: ft.com
Link: https://www.ft.com/content/7a4e7eae-f004-486a-987f-4a2e4dbd34fbSource snippet
These errors arise from the probabilistic way the models predict the next word in a sentence, sometimes leading to plausible yet incorrec...
-
Source: medium.com
Link: https://medium.com/%40QuarkAndCode/llm-hallucinations-explained-causes-risks-how-to-prevent-them-8040adeb4f8fSource snippet
LLM Hallucinations Explained: Causes, Risks & How to...an AI hallucination is false or misleading information of always predicting the n...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/haythamassem_why-language-models-hallucinatepdf-activity-7370201125955997697–iziSource snippet
Why language models hallucinate: A paper by OpenAI➡️ The paper breaks this down statistically: During pre-training, models face natural p...
-
Source: pub.towardsai.net
Link: https://pub.towardsai.net/hallucinations-in-llms-a-deep-technical-dive-into-causes-detection-and-mitigation-90229180543bSource snippet
in LLMs: A Deep Technical Dive into...11 Feb 2026 — These occur when a model generates confident, plausible-sounding answers that are fa...
-
Source: sawantvishwajeet729.medium.com
Link: https://sawantvishwajeet729.medium.com/understanding-why-language-models-hallucinate-a-deep-dive-into-openais-latest-research-a5ccea95a327Source snippet
Why Language Models Hallucinate: A Deep...The paper demonstrates that hallucinations aren't mysterious artifacts — they emerge naturally...
-
Source: medium.com
Link: https://medium.com/%40mokabbirbhuiyan/ai-hallucinations-understanding-why-llms-make-things-up-and-how-to-fix-it-2ce07ac1c5e7Source snippet
AI Hallucinations: Understanding Why LLMs Make Things...This is perhaps the most groundbreaking insight from 2025 research. OpenAI's rec...
-
Source: reddit.com
Link: https://www.reddit.com/r/learnmachinelearning/comments/17gd8mi/how_did_language_models_go_from_predicting_the/Source snippet
October 25, 2023 — A language model was designed to predict the next word in a sequence, or a missing word given the surrounding words, u...
Published: October 25, 2023
-
Source: sulbhajain.medium.com
Link: https://sulbhajain.medium.com/guide-to-building-language-models-e6655501e3deSource snippet
to building Language models | by Sulbha Jain - MediumJanuary 24, 2025 — Guide to building Language models LLM can predict next word or fi...
Published: January 24, 2025
-
Source: lesswrong.com
Title: paper close reading why language models hallucinate
Link: https://www.lesswrong.com/posts/rAjtnXx5qLgubsrGQ/paper-close-reading-why-language-models-hallucinateSource snippet
Paper close reading: "Why Language Models Hallucinate"Apr 5, 2026 — We argue that language models hallucinate because the training and ev...
Topic Tree