Within ELIZA effect
What does fooling a human really prove?
Turing-style tests reveal whether a machine can pass as human in conversation, not whether it truly understands.
On this page
- What the classic Turing test asks
- Why imitation can pass for intelligence
- Which abilities short chats fail to measure
Page outline Jump by section
Introduction
A machine that can convince people it is human in conversation has achieved something important, but not necessarily what many people assume. Turing-style chat tests show whether a system can produce language that people interpret as human-like under specific conditions. They do not, by themselves, prove that the system understands the world, reasons deeply, forms intentions, or possesses consciousness. This distinction sits at the heart of debates about artificial intelligence. The evidence from modern chatbot experiments suggests that conversational imitation is a real and increasingly impressive capability, yet many questions about intelligence remain open. [Wikipedia]WikipediaTuring testTuring test

What does the classic Turing test ask?
In 1950, Alan Turing proposed replacing the vague question “Can machines think?” with a practical experiment. A human judge would communicate through text with both a human and a machine. If the judge could not reliably tell them apart, the machine would succeed in the test. The focus was not on inspecting internal mechanisms but on observable conversational behaviour. [Wikipedia]WikipediaTuring testTuring test
This was a powerful idea because it shifted discussion away from abstract definitions of thought. Instead of arguing endlessly about what intelligence is, researchers could ask whether a machine could participate in human conversation convincingly enough to be mistaken for a person. That behavioural approach helped shape decades of AI research. [Wikipedia]WikipediaTuring testTuring test
Importantly, the original test was never a direct measurement of understanding. It was an imitation game. Success meant matching human conversational performance closely enough to fool a judge, not demonstrating every aspect of intelligence. [Wikipedia]WikipediaTuring testTuring test
Why imitation can pass for intelligence
Human beings naturally treat coherent language as evidence of a mind. The history of chatbots shows how powerful this tendency can be.
Even ELIZA, a comparatively simple program from the 1960s, persuaded some users that it understood them despite relying largely on pattern matching and scripted conversational techniques. This phenomenon became known as the ELIZA effect: people often attribute more understanding, empathy, or awareness to a system than the evidence warrants. [Artificial Intelligence Stack Exchange+2Springer Link]ai.stackexchange.comwhy was eliza able to induce delusional thinkingArtificial Intelligence Stack ExchangeWhy was ELIZA able to induce "delusional thinking"?23 Aug 2016 — Upon observation, researchers disc…
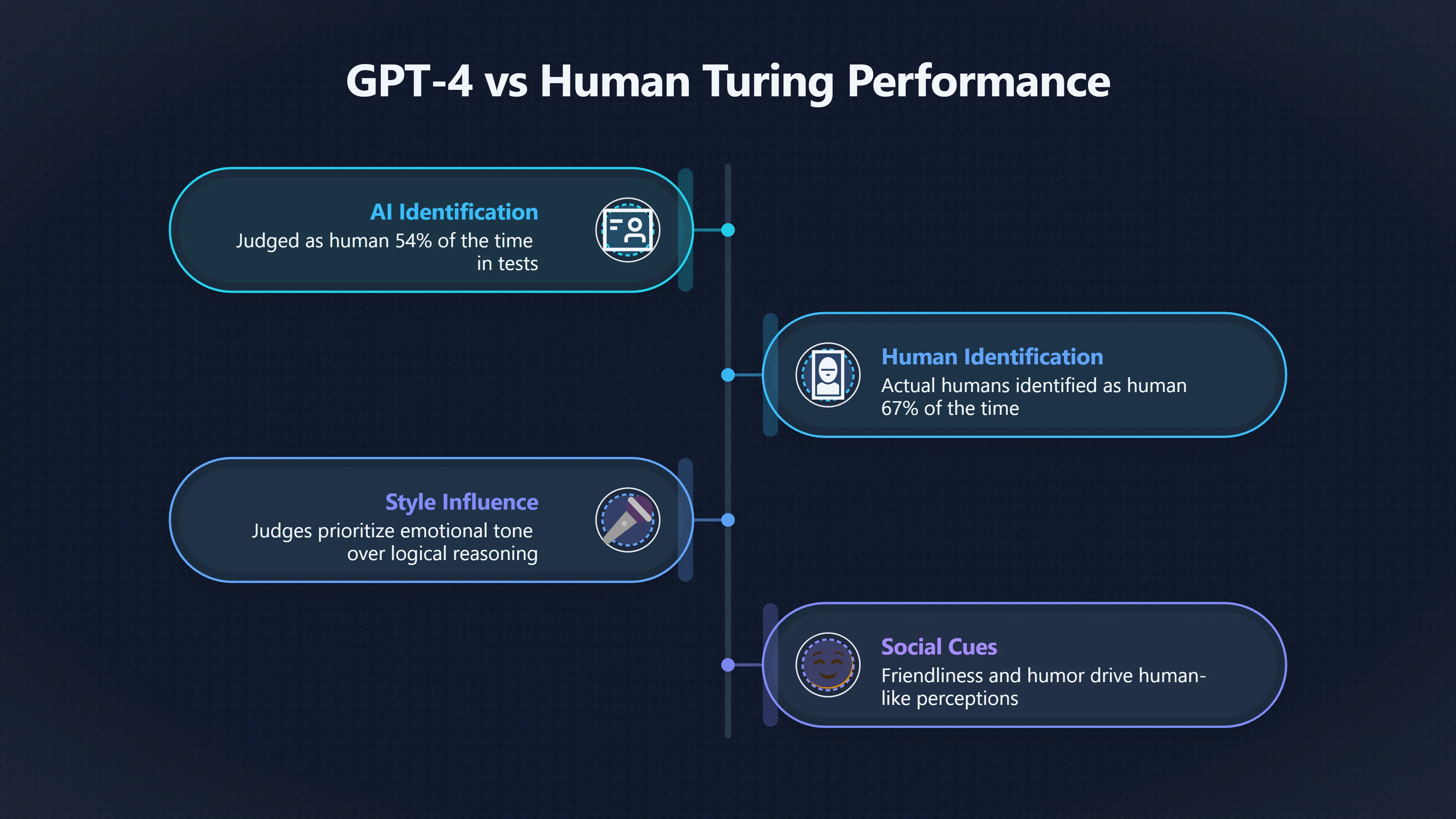
Modern language models are vastly more capable than ELIZA, making the effect stronger. Recent Turing-test-style studies found that participants frequently judged advanced AI systems to be human. In one controlled experiment, GPT-4 was identified as human 54% of the time during five-minute conversations, while actual humans were identified as human 67% of the time. Researchers described this as the first robust evidence that an artificial system could pass an interactive Turing-style test. [arXiv]arxiv.orgPeople cannot distinguish GPT-4 from a human in a Turing…9 May 2024 — GPT-4 was judged to be a human 54% of the time, outperformi…
The most revealing finding was not simply that people were fooled. Researchers found that conversational style, emotional tone, and social cues appeared to matter more than demonstrations of logical reasoning or specialised knowledge. Human judges often based decisions on whether a conversation felt natural rather than on whether it displayed deep understanding. [arXiv+2arXiv]arxiv.orgarXiv People cannot distinguish GPT-4 from a human in a Turing testarXiv People cannot distinguish GPT-4 from a human in a Turing test
This suggests that Turing-style chats can successfully measure a machine’s ability to participate in human social communication. They are much less direct measures of intelligence in a broader sense.

Which abilities short chats fail to measure?
A convincing conversation can hide important gaps. Several capabilities associated with intelligence are only weakly tested—or not tested at all—by brief chat exchanges.
Long-term reasoning. A system may generate plausible answers sentence by sentence without maintaining a coherent plan across hours, days, or complex projects. A five-minute conversation provides little opportunity to examine sustained reasoning. [Wikipedia]WikipediaTuring testTuring test
Grounding in the physical world. Human understanding is connected to perception, action, and lived experience. A text-only conversation does not reveal whether a system truly links words to physical reality or merely models patterns in language. [Science]science.orgThe Turing Test and our shifting conceptions of intelligenceby M Mitchell · 2024 · Cited by 79 — Turing imagined an “imitation gam…
Original problem-solving. Some forms of intelligence involve discovering new solutions, generating scientific insights, or solving unfamiliar problems. A chatbot can appear human by discussing such topics without actually demonstrating those abilities during the conversation. Turing-style tests focus on human likeness rather than exceptional performance. [Wikipedia]WikipediaTuring testTuring test
Planning and agency. Intelligence is often associated with pursuing goals over time. Short conversations rarely reveal whether a system can independently plan, adapt, and execute complex actions in changing environments. [Science]science.orgThe Turing Test and our shifting conceptions of intelligenceby M Mitchell · 2024 · Cited by 79 — Turing imagined an “imitation gam…
Truthfulness. A conversational system can sound confident, coherent, and human while producing inaccurate information. Human-like communication and factual reliability are separate qualities. Passing a Turing-style test does not guarantee correctness. [Wikipedia]WikipediaTuring testTuring test
Evidence from modern chatbot studies
Recent experiments sharpen the distinction between conversational success and broader intelligence.
Researchers studying GPT-4 and related models found that judges frequently relied on friendliness, personality, humour, and emotional responsiveness when deciding whether they were speaking to a human. These are genuine conversational skills, but they are not equivalent to comprehensive reasoning ability. [arXiv]arxiv.orgarXiv People cannot distinguish GPT-4 from a human in a Turing testarXiv People cannot distinguish GPT-4 from a human in a Turing test
Follow-up studies found that people sometimes struggled to distinguish AI-generated conversations even when reading transcripts rather than participating directly. In some experimental conditions, AI-generated dialogue was judged more human than genuine human responses. The findings highlight how strongly people respond to conversational style. [arXiv]arxiv.orgGPT-4 is judged more human than humans in displaced and inverted Turing testsJuly 11, 2024…
At the same time, researchers continue to caution against interpreting these results as proof of general intelligence. The experiments demonstrate success at human imitation in specific conversational settings. They do not settle questions about understanding, consciousness, or the full range of cognitive abilities associated with intelligence. [Science+2Wikipedia]science.orgThe Turing Test and our shifting conceptions of intelligenceby M Mitchell · 2024 · Cited by 79 — Turing imagined an “imitation gam…

What fooling a human really proves
The strongest conclusion supported by the evidence is narrower than either enthusiasts or sceptics sometimes claim.
A successful Turing-style performance proves that a machine can participate in conversation well enough to be mistaken for a human under particular conditions. That achievement is significant because language is one of humanity’s most sophisticated social abilities. Modern systems clearly demonstrate capabilities that earlier generations of AI lacked. [arXiv]arxiv.orgarXiv People cannot distinguish GPT-4 from a human in a Turing testarXiv People cannot distinguish GPT-4 from a human in a Turing test
However, the same evidence shows that conversational indistinguishability leaves major questions unanswered. A machine may appear understanding without possessing human-like understanding. It may generate persuasive language without having goals, experiences, or a grounded model of reality. It may imitate intelligent behaviour without demonstrating every capability people associate with intelligence. [Wikipedia+2Science]WikipediaTuring testTuring test
The lasting lesson of Turing-style chats is therefore twofold: conversational behaviour is an important form of intelligence worth studying, but sounding human and fully understanding are not necessarily the same thing. [Wikipedia+2Stanford Encyclopedia of Philosophy]WikipediaTuring testTuring test
Amazon book picks
Further Reading
Books and field guides related to What does fooling a human really prove?. Use these as the next step if you want deeper reading beyond the article.
The Most Human Human
Directly examines what passing a Turing-style conversation test means and does not mean.
Artificial Intelligence
Rating: 4.5/5 from 10 Google Books ratings
Covers AI evaluation, intelligence, and the historical role of the Turing Test.
Godel, Escher, Bach
Explores intelligence, symbols, minds, and the limits of imitation.
Human Compatible
Discusses what genuine intelligence and alignment involve beyond conversational performance.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: Wikipedia
Title: Turing test
Link: https://en.wikipedia.org/wiki/Turing_test -
Source: plato.stanford.edu
Title: turing test
Link: https://plato.stanford.edu/entries/turing-test/Source snippet
Stanford Encyclopedia of PhilosophyThe Turing Test (Stanford Encyclopedia of Philosophy)by G Oppy · 2003 · Cited by 430 — One claim holds...
-
Source: link.springer.com
Link: https://link.springer.com/article/10.1007/s00146-023-01793-zSource snippet
AI researchers have tended to treat...
-
Source: arxiv.org
Link: https://arxiv.org/html/2405.08007v1Source snippet
People cannot distinguish GPT-4 from a human in a Turing...9 May 2024 — GPT-4 was judged to be a human 54% of the time, outperformi...
Published: May 2024
-
Source: arxiv.org
Title: arXiv People cannot distinguish GPT-4 from a human in a Turing test
Link: https://arxiv.org/abs/2405.08007 -
Source: arxiv.org
Title: arXiv Does GPT-4 pass the Turing test?
Link: https://arxiv.org/abs/2310.20216 -
Source: arxiv.org
Link: https://arxiv.org/abs/2407.08853Source snippet
GPT-4 is judged more human than humans in displaced and inverted Turing testsJuly 11, 2024...
Published: July 11, 2024
-
Source: arxiv.org
Link: https://arxiv.org/html/2511.20699v1Source snippet
In Defense of the Turing Test and its Legacy †24 Nov 2025 — The Turing test encourages fooling people; · Turing overestimated human intel...
-
Source: science.org
Link: https://www.science.org/doi/10.1126/science.adq9356Source snippet
The Turing Test and our shifting conceptions of intelligenceby M Mitchell · 2024 · Cited by 79 — Turing imagined an “imitation gam...
-
Source: ai.stackexchange.com
Title: why was eliza able to induce delusional thinking
Link: https://ai.stackexchange.com/questions/1716/why-was-eliza-able-to-induce-delusional-thinkingSource snippet
Artificial Intelligence Stack ExchangeWhy was ELIZA able to induce "delusional thinking"?23 Aug 2016 — Upon observation, researchers disc...
Additional References
-
Source: semanticscholar.org
Link: https://www.semanticscholar.org/paper/People-cannot-distinguish-GPT-4-from-a-human-in-a-Jones-Rathi/505c7b471457ac447efdb9abc714247dd10dbef8Source snippet
People cannot distinguish GPT-4 from a human in a Turing...Analysis of participants' strategies and reasoning suggests that stylistic an...
-
Source: qymatix.de
Link: https://qymatix.de/en/afraid-of-ai-eliza-effect/Source snippet
The ELIZA Effect: Why We Attribute Human Traits...The ELIZA effect explains why people anthropomorphize ChatGPT and other AI systems. Le...
-
Source: today.ucsd.edu
Title: ai can seem more human than real humans in a classic turing test study finds
Link: https://today.ucsd.edu/story/ai-can-seem-more-human-than-real-humans-in-a-classic-turing-test-study-findsSource snippet
UC San Diego TodayAI Can Seem More Human Than Real Humans in a Classic...19 May 2026 — A new UC San Diego study unveils the first empiri...
Published: May 2026
-
Source: reddit.com
Link: https://www.reddit.com/r/Futurology/comments/1cur89h/majority_of_humans_fooled_by_gpt4_in_turing_test/Source snippet
6. 5... ChatGPT-4 outperforms human psychologists in test of social intelligence...Read more...
-
Source: repository.cam.ac.uk
Link: https://www.repository.cam.ac.uk/bitstreams/b18ed201-b70a-4dab-bc52-c78f49e882b8/downloadSource snippet
bridge RepositoryTuring's Test, a Beautiful Thought Experimentby B Gonalves · 2024 · Cited by 7 — Turing's imitation game extended the...
-
Source: growkudos.com
Link: https://www.growkudos.com/publications/10.1073%25252Fpnas.2524472123/readerSource snippet
People can't tell the difference between humans and LLMs in...For 75 years, the Turing test has been a benchmark for machine intelligence...
-
Source: facebook.com
Link: https://www.facebook.com/groups/lifeboatfoundation/posts/10162727236753455/Source snippet
le #GPT-3.5 models fooled them only 5% to 14% of the time.Read more...
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/375117569_Does_GPT-4_Pass_the_Turing_TestSource snippet
of games, outperforming ELIZA (22%) and GPT-3.5 (20%).Read more...
-
Source: catalyzex.com
Link: https://www.catalyzex.com/paper/people-cannot-distinguish-gpt-4-from-a-humanSource snippet
People cannot distinguish GPT-4 from a human in a Turing...GPT-4 was judged to be a human 54% of the time, outperforming ELIZA (22%) but...
-
Source: aclanthology.org
Title: 2025.genaidetect 1.7
Link: https://aclanthology.org/2025.genaidetect-1.7.pdfSource snippet
ACL AnthologyGPT-4 is Judged More Human than Humans in Displaced...by IM Rathi · 2025 · Cited by 22 — Recent empirical work has found th...
Topic Tree