Within Over compression
When Medical AI Summaries Miss the Exception
A standard treatment summary can sound safe while leaving out allergies, pregnancy, drug interactions, or rare risks that change the decision.
On this page
- How standard pathways become overconfident advice
- Patient details that change the risk calculation
- Questions to ask before trusting a medical summary
Page outline Jump by section
Introduction
Artificial intelligence can produce medical summaries that sound clear, balanced and reassuring while quietly omitting the details that determine whether a treatment is safe for a particular person. In medicine, those details are often contraindications: allergies, pregnancy status, existing conditions, drug interactions, age-related risks, or uncommon but serious adverse effects. A treatment that is appropriate for most patients may be dangerous for a specific patient because of one overlooked factor.
 This problem sits at the centre of a broader concern about AI over-compressing risk. Large language models are designed to condense information into concise answers. In doing so, they can preserve the main treatment pathway while dropping the exceptions that clinicians use to decide whether the pathway applies at all. Research has repeatedly found that AI systems tend to overgeneralise scientific and medical findings and may omit critical safety qualifications even when the overall answer appears accurate. [Live Science]livescience.comLive ScienceChatbots gloss over critical details in summaries of scientific studies, say scientists | Live ScienceJuly 5, 2025…
This problem sits at the centre of a broader concern about AI over-compressing risk. Large language models are designed to condense information into concise answers. In doing so, they can preserve the main treatment pathway while dropping the exceptions that clinicians use to decide whether the pathway applies at all. Research has repeatedly found that AI systems tend to overgeneralise scientific and medical findings and may omit critical safety qualifications even when the overall answer appears accurate. [Live Science]livescience.comLive ScienceChatbots gloss over critical details in summaries of scientific studies, say scientists | Live ScienceJuly 5, 2025…
When Medical AI Summaries Miss the Exception
Medical decision-making is not simply a matter of matching a diagnosis to a treatment. It involves asking whether a standard treatment should be avoided because of patient-specific circumstances.
A human clinician may mentally process questions such as:
- Is the patient pregnant or breastfeeding?
- Does the patient have kidney or liver disease?
- Is there a known allergy?
- Are there medications that could interact dangerously?
- Is the patient unusually young, elderly, or immunocompromised?
- Does the patient have a rare condition that changes the risk profile?
An AI summary often focuses on the average case because the average case is easier to compress into a short answer. The resulting recommendation can sound correct while failing to communicate the conditions under which it stops being correct.
This is especially important because readers frequently interpret a concise answer as a complete answer. Researchers studying AI-generated summaries of scientific papers found that large language models were substantially more likely than human experts to overgeneralise findings, turning qualified conclusions into broader claims than the underlying evidence justified. [Live Science]livescience.comLive ScienceChatbots gloss over critical details in summaries of scientific studies, say scientists | Live ScienceJuly 5, 2025…
How Standard Pathways Become Overconfident Advice
The structure of medical knowledge encourages this failure mode.
Clinical guidelines are often written in a form that resembles:
For most patients with condition X, treatment Y is recommended.
However, the practical decision process may actually be:
For most patients with condition X, treatment Y is recommended unless factors A, B, C, D or E are present.
The exceptions are frequently less prominent than the main recommendation. When AI systems generate summaries, they tend to prioritise the dominant pattern in the source material rather than the edge cases.
The result is a subtle transformation:
- “Often recommended” becomes “recommended”.
- “Generally safe” becomes “safe”.
- “Effective in studied populations” becomes “effective”.
- “Avoid in certain circumstances” disappears entirely.
Researchers have described a tendency for newer language models to produce authoritative answers rather than decline uncertain questions. This can make omissions harder to notice because the response sounds confident and complete even when important qualifications have been removed. [Live Science]livescience.comLive ScienceChatbots gloss over critical details in summaries of scientific studies, say scientists | Live ScienceJuly 5, 2025…
The danger is not necessarily that the model invents a treatment. The danger is that it presents a treatment without preserving the conditions that make the treatment appropriate.
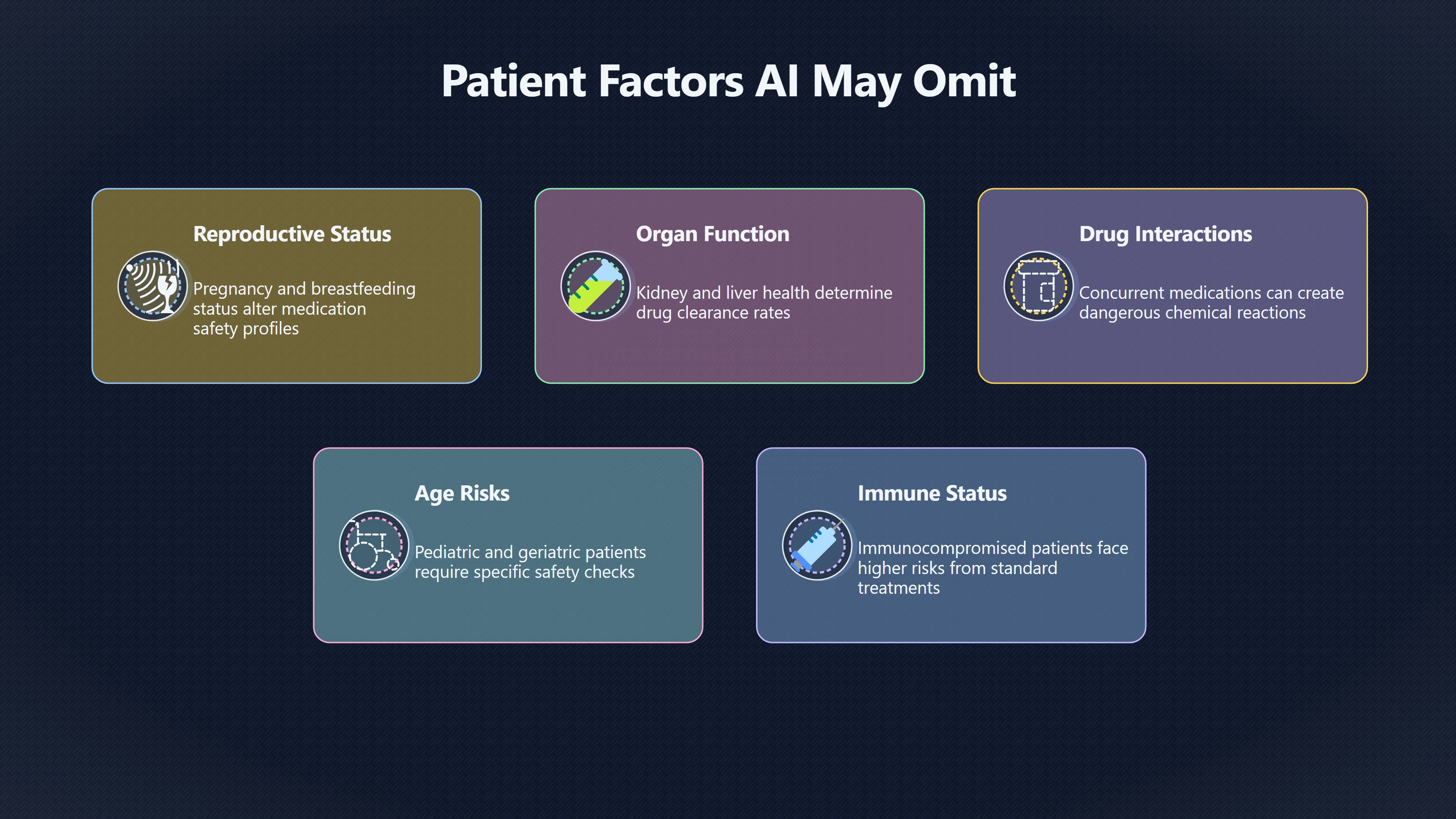
Patient Details That Change the Risk Calculation
Pregnancy and reproductive health
Pregnancy illustrates why contraindications matter.
A medication considered routine for the general population may carry warnings, restrictions or additional considerations during pregnancy. A study evaluating ChatGPT’s responses about over-the-counter medicines in pregnancy found generally high accuracy but also identified critical safety omissions, including failures to warn about known pregnancy-related risks in some cases. Researchers concluded that such omissions could create significant patient-safety concerns if users relied on the chatbot as a standalone source. [MDPI]mdpi.comAccuracy and Safety of ChatGPT-3.5 in Assessing Over-the-Counter Medication Use During Pregnancy: A Descriptive Comparative Study…
The problem is not unique to pregnancy. Similar issues arise with breastfeeding, fertility treatments and medicines that affect foetal development.
Drug interactions
Many medical risks emerge only when two or more medications are combined.
A treatment summary that correctly describes a drug’s intended effect may still be incomplete if it does not account for interactions with anticoagulants, antidepressants, heart medications or other therapies. Detecting clinically important drug–drug interactions remains an active area of research for healthcare AI systems, reflecting the complexity of preserving these relationships in automated outputs. [Sage Journals]journals.sagepub.comJustine Sicard, François Montastruc, Coline Achalme, Annie Pierre Jonville-Bera, Paul Songue, Marina Babin, Thomas Soeiro, Pauline Schiro…
A patient reading a short AI answer may see only the recommendation, not the interaction warning that would have changed the decision.

Chronic conditions and individual history
Many contraindications depend on information that never appears in the user’s prompt.
For example, a medication’s safety may depend on:
- Kidney function.
- Liver function.
- Previous adverse reactions.
- Cardiovascular disease.
- Autoimmune disorders.
- Cancer history.
Large language models have limited understanding of information that was never supplied to them. Even when relevant details are mentioned, healthcare reviews note that current systems can struggle to integrate subtle clinical context and appropriately weigh competing risk factors. [MDPI+2Springer Link]mdpi.comLarge Language Models in Healthcare and Medical Applications: A Review | MDPIJune 10, 2025…
The summary therefore reflects the information visible to the model, not necessarily the information that would matter to a clinician.
Why Omissions Are Harder to Detect Than Mistakes
A fabricated medical fact can sometimes be spotted because it directly contradicts known information. An omitted contraindication is more difficult.
Consider two responses:
- A wrong dosage recommendation.
- A correct dosage recommendation that omits a dangerous interaction.
The first contains an identifiable error. The second may appear flawless unless the reader already knows what is missing.
This creates what some researchers describe as an illusion of reliability. Users may receive several accurate answers, build trust in the system, and then fail to recognise when a later response is incomplete in a medically significant way. The pregnancy-medication study specifically highlighted this risk, noting that omissions can become dangerous precisely because they occur within otherwise credible responses. [MDPI]mdpi.comAccuracy and Safety of ChatGPT-3.5 in Assessing Over-the-Counter Medication Use During Pregnancy: A Descriptive Comparative Study…
Recent research on AI-generated clinical summaries has similarly found that omissions are often more common than outright fabrications. In physician-reviewed hospital summaries, omitted information appeared more frequently than hallucinated content. [JAMA Network]jamanetwork.comJAMA NetworkPhysician-Reported Safety Outcomes of AI-Generated Hospital Course SummariesMay 8, 2026…

Why the Problem Persists Even as Models Improve
Many people assume that better-performing models automatically solve this issue. The evidence suggests the problem is more complicated.
Modern systems are increasingly fluent, coherent and knowledgeable. Yet greater fluency can make missing caveats less visible. Researchers have found that newer models may produce more polished overgeneralisations rather than refusing uncertain requests. [Live Science]livescience.comLive ScienceChatbots gloss over critical details in summaries of scientific studies, say scientists | Live ScienceJuly 5, 2025…
Another challenge is that healthcare conversations are highly sensitive to wording. Studies have shown that subtle changes in phrasing can alter model outputs, while misleading information presented in an authoritative medical style can sometimes be accepted more readily than casual misinformation. [Reuters+2Live Science]reuters.comMedical misinformation more likely to fool AI if source appears legitimate, study showsResearchers tested 20 AI models with over 1 million user prompts, using three types of content: realistic hospital discharge notes with a…
In practice, this means that a model may not merely miss a contraindication because it lacks knowledge. It may miss it because the prompt did not highlight the relevant risk factor, because the wording steered attention elsewhere, or because the summary process compressed away information that seemed secondary but was clinically decisive.
Questions to Ask Before Trusting a Medical Summary
A short AI-generated medical explanation becomes safer when readers actively look for the missing exceptions.
Before relying on a medical summary, it is worth asking:
- Who might this recommendation not apply to? Children, older adults, pregnant patients, or people with chronic diseases often have different risk profiles.
- What information about me was not included? Existing medications, allergies and previous adverse reactions can change the recommendation.
- Are there interaction risks? Even routine medicines may interact with other treatments.
- What rare but serious harms were left out? Low-probability risks may still be important when the consequences are severe.
- Was uncertainty discussed? Medical evidence is often probabilistic rather than absolute.
The most important shift is conceptual: treat an AI medical summary as a compressed overview, not as a complete risk assessment. In medicine, the exception is often the most important part of the answer. When AI systems compress information, that exception is frequently the first thing to disappear.
Amazon book picks
Further Reading
Books and field guides related to When Medical AI Summaries Miss the Exception. Use these as the next step if you want deeper reading beyond the article.
The Checklist Manifesto
Demonstrates why exceptions, overlooked details and safety checks matter in medical decisions.
Being Mortal
Highlights the importance of individual patient circumstances rather than generic pathways.
How Doctors Think
Explores diagnostic reasoning, exceptions and sources of medical error.
The Emperor of All Maladies
Shows the complexity of evidence, treatment decisions and patient-specific factors.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: mdpi.com
Link: https://www.mdpi.com/2226-4787/13/4/104/htmlSource snippet
Accuracy and Safety of ChatGPT-3.5 in Assessing Over-the-Counter Medication Use During Pregnancy: A Descriptive Comparative Study...
-
Source: mdpi.com
Link: https://www.mdpi.com/3350980Source snippet
Large Language Models in Healthcare and Medical Applications: A Review | MDPIJune 10, 2025...
Published: June 10, 2025
-
Source: link.springer.com
Link: https://link.springer.com/article/10.1007/s10462-024-10921-0Source snippet
Springer LinkLarge language models in medical and healthcare fields: applications, advances, and challenges | Artificial Intelligence Rev...
-
Source: mdpi.com
Title: Large Language Models in Healthcare and Medical Applications: A Review
Link: https://www.mdpi.com/2306-5354/12/6/631Source snippet
Large Language Models in Healthcare and Medical Applications: A Review...
-
Source: reuters.com
Link: https://www.reuters.com/[businessSource snippet
Researchers tested 20 AI models with over 1 million user prompts, using three types of content: realistic hospital discharge notes with a...
-
Source: livescience.com
Link: https://www.livescience.com/technology/artificial-intelligence/ai-chatbots-oversimplify-scientific-studies-and-gloss-over-critical-details-the-newest-models-are-especially-guiltySource snippet
Live ScienceChatbots gloss over critical details in summaries of scientific studies, say scientists | Live ScienceJuly 5, 2025...
Published: July 5, 2025
-
Source: journals.sagepub.com
Link: https://journals.sagepub.com/doi/10.1177/20420986251339358Source snippet
Justine Sicard, François Montastruc, Coline Achalme, Annie Pierre Jonville-Bera, Paul Songue, Marina Babin, Thomas Soeiro, Pauline Schiro...
-
Source: journals.sagepub.com
Link: https://journals.sagepub.com/doi/abs/10.1177/20420986251339358Source snippet
Justine Sicard, François Montastruc, Coline Achalme, Annie Pierre Jonville-Bera, Paul Songue, Marina Babin, Thomas Soeiro, Pauline Schiro...
-
Source: jamanetwork.com
Link: https://jamanetwork.com/journals/jamanetworkopen/fullarticle/2848785Source snippet
JAMA NetworkPhysician-Reported Safety Outcomes of AI-Generated Hospital Course SummariesMay 8, 2026...
Published: May 8, 2026
-
Source: livescience.com
Link: https://www.livescience.com/health/rectal-garlic-insertion-for-immune-support-medical-chatbots-confidently-give-disastrously-misguided-advice-experts-saySource snippet
Researchers found that large language models (LLMs) like ChatGPT and Gemini confidently provide incorrect health recommendations when pre...
Additional References
-
Source: timesofindia.indiatimes.com
Link: https://timesofindia.indiatimes.com/technology/tech-news/ai-chatbots-like-chatgpt-can-be-dangerous-for-doctors-as-well-as-patients-as-warns-mit-research/articleshow/122076203.cmsSource snippet
Researchers found that Large Language Models (LLMs) can be influenced by nonclinical elements in patient messages—such as typos, extra sp...
-
Source: reddit.com
Link: https://www.reddit.com/r/LocalLLaMA/comments/1e7bw7eSource snippet
www.reddit.comMedical/Healthcare AI Experts: Where do Clinical LLMs Mostly Fail?July 19, 2024...
Published: July 19, 2024
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=ry3R7k6x1PgSource snippet
The Hidden Dangers of AI-Generated Medical Advice, With Girish Nadkarni, MD, MPH...
-
Source: youtube.com
Title: Study: AI Chatbots Give Misleading Medical Tips | WION
Link: https://www.youtube.com/watch?v=_r4xByD2uPYSource snippet
The Limits of Chatbots in Clinical Decision‑Making - YouTube The Limits of Chatbots in Clinical Decision‑Making - YouTube...
-
Source: youtube.com
Title: The Hidden Dangers of AI-Generated Medical Advice, With Girish Nadkarni, MD, MPH
Link: https://www.youtube.com/watch?v=5c5jGCXki1oSource snippet
Is AI Safe for Medical Advice? What Parents Need to Know | Healthy Kids...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2606.07237 -
Source: youtube.com
Title: Is AI Safe for Medical Advice? What Parents Need to Know | Healthy Kids
Link: https://www.youtube.com/watch?v=H3DE2dwTvAQSource snippet
Study: AI Chatbots Give Misleading Medical Tips | WION...
-
Source: youtube.com
Title: The Limits of Chatbots in Clinical Decision‑Making
Link: https://www.youtube.com/watch?v=oinwf25rIMcSource snippet
Assessing the Limitations of Large Language Models in Clinical Fact Decomposition...
Topic Tree