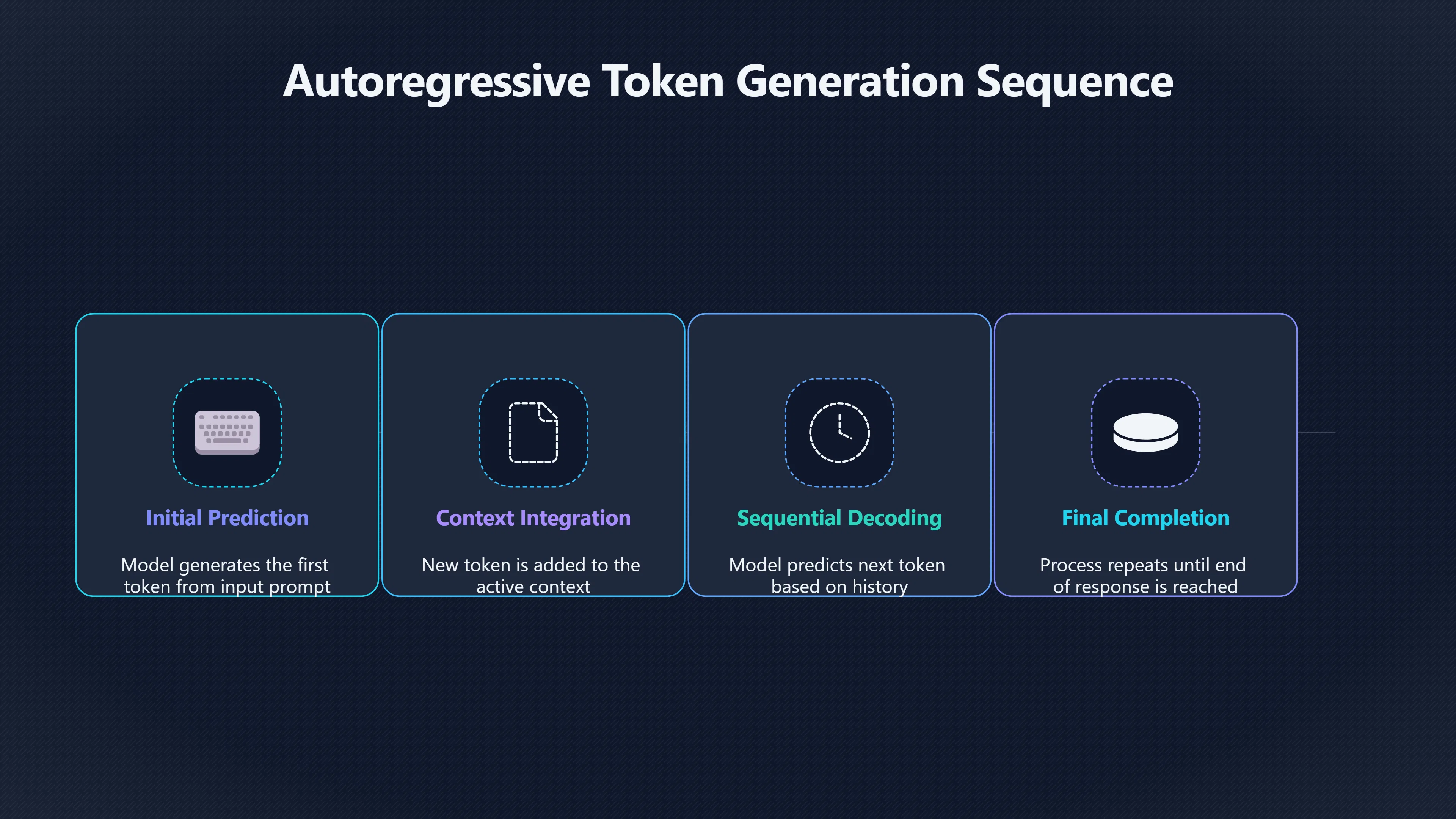
Within Generation loop
Why longer AI answers slow down
Long replies take more time because every extra token requires another prediction step using the growing context.
On this page
- The repeated cost of each new token
- Why the context keeps growing
- How hardware and optimization hide the loop
Page outline Jump by section
Introduction
Long AI answers take longer to appear for a simple reason: the model does not create the entire response at once. Instead, it generates one token at a time, and every additional token requires another prediction step. What appears on screen as a flowing paragraph is actually a rapid sequence of individual decisions, each based on the prompt and everything generated so far. Because generation is inherently sequential, a 500-token answer requires roughly five times as many generation steps as a 100-token answer. This token-by-token process is one of the main reasons output length has a strong effect on response time. [arXiv+2Wayland Zhang]arxiv.orgEnabling Autoregressive Models Multi-Token Generation8 Apr 2026 — Autoregressive (AR) language models spend the same compute on ever…
 Understanding this helps explain why chatbots often begin responding quickly but take noticeably longer to finish lengthy explanations, reports, stories, or code listings.
Understanding this helps explain why chatbots often begin responding quickly but take noticeably longer to finish lengthy explanations, reports, stories, or code listings.
The repeated cost of each new token
When a language model generates text, it performs a prediction cycle for every token it outputs. After producing one token, it must immediately run another prediction to determine the next one. The process repeats until the answer is complete. Unlike many computing tasks, these prediction steps cannot simply be generated all at once because each new token depends on the tokens that came before it. [Wayland Zhang+2NVIDIA Developer]waylandz.comWayland Zhang Chapter 16: Training vs InferenceWayland ZhangChapter 16: Training vs Inference - Why Generation Is One…Training processes the full known sequence in parallel; inferen…
A useful way to think about it is as a chain:
- Generate token 1. [waylandz.com]waylandz.comWayland Zhang Chapter 16: Training vs InferenceWayland ZhangChapter 16: Training vs Inference - Why Generation Is One…Training processes the full known sequence in parallel; inferen…
- Add token 1 to the context.
- Generate token 2. [waylandz.com]waylandz.comWayland Zhang Chapter 16: Training vs InferenceWayland ZhangChapter 16: Training vs Inference - Why Generation Is One…Training processes the full known sequence in parallel; inferen…
- Add token 2 to the context.
- Repeat until the response ends.
If a model generates 50 tokens, it performs approximately 50 decoding steps. If it generates 500 tokens, it performs approximately 500 decoding steps. The relationship is not perfectly linear because of hardware and implementation details, but longer outputs generally require proportionally more work. [arXiv+2NVIDIA Developer]arxiv.orgEnabling Autoregressive Models Multi-Token Generation8 Apr 2026 — Autoregressive (AR) language models spend the same compute on ever…
This is why output length often dominates perceived latency. In production systems, the time spent generating completion tokens can exceed the time spent reading the original prompt. [Medium]medium.comThis has several practical implications.Read moreUnderstanding LLM Response Latency: A Deep Dive into…July 16, 2025 — The key insight is that output token latency is dramaticall…
Why generation cannot be fully parallelised
During training, models can process many positions in a sequence simultaneously because the correct text is already known. During inference—the stage where a chatbot is answering a user—future tokens do not yet exist. The model must wait for each prediction before it can make the next one. This serial dependency creates a fundamental speed limit. [Wayland Zhang]waylandz.comWayland Zhang Chapter 16: Training vs InferenceWayland ZhangChapter 16: Training vs Inference - Why Generation Is One…Training processes the full known sequence in parallel; inferen…
As a result, generating 1,000 tokens is not merely displaying more text. It requires roughly 1,000 successive prediction cycles.
Why the context keeps growing
Long replies involve more than just additional prediction steps. Every newly generated token becomes part of the context that future predictions must consider.
Suppose a chatbot has already produced several paragraphs. When it predicts the next token, it does not ignore those paragraphs. Instead, it incorporates the growing conversation history and generated response into its calculations. The effective sequence becomes longer with each step. [Codefinity]codefinity.comLearn Autoregressive Generation MechanismHidden states in transformers carry forward the context from earlier tokens at each ge…
Without optimisation techniques, this growth would become extremely expensive. A naive implementation would repeatedly recalculate information about all previous tokens during every generation step. Researchers often use examples where the amount of text that must be reconsidered grows continuously as generation progresses. [Michael Brenndoerfer]mbrenndoerfer.comThe first generated token requires processing 50 tokens.Read moreMichael BrenndoerferAutoregressive Generation: How GPT Generates Text…28 Jul 2025 — With naive generation, each step requires a full f…
The practical consequence is that:
- A short answer has a relatively small working context.
- A long answer creates a much larger working context.
- Larger contexts generally require more memory and data movement.
- More memory usage can reduce overall throughput and increase latency. [arXiv+2arXiv]arxiv.orgBoosting KV Cache Retrieval for Efficient LLM InferenceFeb 28, 2026 — However, long contexts pose significant deployment challenges…
Studies of long-context inference consistently find that latency tends to rise as sequence length increases, creating a trade-off between using more context and maintaining fast response times. [arXiv]arxiv.orgarXiv Is Long Context All You Need?Leveraging LLM's…Latency increases (near) linearly with context size, hence there is a clear trade-off between latency and better accu…

A practical example
Imagine two chatbot replies generated by the same model:
- Reply A: 100 tokens.
- Reply B: 1,000 tokens.
Reply B requires roughly ten times as many generation steps. In addition, the later stages of Reply B operate over a much larger accumulated context. Even though modern optimisations reduce the cost dramatically, the model still performs substantially more work overall. [arXiv+2Hugging Face]arxiv.orgEnabling Autoregressive Models Multi-Token Generation8 Apr 2026 — Autoregressive (AR) language models spend the same compute on ever…
This is why lengthy essays, detailed reports, and long code outputs usually stream for longer than short factual answers.
How hardware and optimisation hide the loop
If every generation step required a complete recomputation of all previous work, chatbot responses would be far slower than they are today. Modern systems rely on several engineering techniques to reduce the cost.
The most important is key-value (KV) caching. Instead of recalculating internal representations for previously generated tokens every time a new token is produced, the model stores reusable information from earlier steps. When generating the next token, it can reuse those cached values rather than starting from scratch. [Hugging Face+2Introl]huggingface.coHugging FaceKV Caching Explained: Optimizing Transformer Inference…Jan 30, 2025 — Key-Value caching is a technique that helps speed up…
KV caching significantly speeds up autoregressive generation, but it introduces its own trade-off. The cache grows as the context becomes longer, increasing memory requirements and placing pressure on memory bandwidth. For very long contexts, cache management becomes a major engineering challenge. [arXiv+2arXiv]arxiv.orgarXiv KV Cache Optimization Strategies for Scalable and Efficient LLM InferencearXiv KV Cache Optimization Strategies for Scalable and Efficient LLM Inference
Researchers and hardware vendors therefore invest heavily in techniques such as:
- Cache compression.
- More efficient memory layouts. [medium.com]medium.comy 2–3× · The 2.6GB rule: Each 1K tokens per concurrent…Read more…
- Faster GPU memory access.
- Speculative decoding, which attempts to generate multiple likely tokens ahead of time.
- Specialised inference hardware and batching strategies. [NVIDIA Developer+2NVIDIA Developer]developer.nvidia.comNVIDIA DeveloperAn Introduction to Speculative Decoding for Reducing…17 Sept 2025 — The core latency bottleneck in standard autoregres…
These optimisations can make generation feel much faster, but they do not eliminate the underlying sequential loop. The model still needs to produce the final answer token by token. [NVIDIA Developer]developer.nvidia.comNVIDIA DeveloperAn Introduction to Speculative Decoding for Reducing…17 Sept 2025 — The core latency bottleneck in standard autoregres…

What the user experiences
From a user’s perspective, a chatbot often appears to “type” its answer. That visible stream is a direct reflection of the generation process.
A short response may complete in a fraction of a second because relatively few prediction steps are needed. A long response may continue streaming for several seconds because hundreds or thousands of tokens must be generated one after another. Even on powerful hardware, each extra token adds another prediction cycle and slightly enlarges the context that future predictions must consider. [Medium+2Databricks]medium.comThis has several practical implications.Read moreUnderstanding LLM Response Latency: A Deep Dive into…July 16, 2025 — The key insight is that output token latency is dramaticall…
The key idea is that a long answer is not a single object waiting to be revealed. It is the result of many fast but sequential prediction steps. The more tokens a chatbot produces, the more times it must repeat that loop, which is why longer AI answers generally take longer to appear. [arXiv+2Wayland Zhang]arxiv.orgEnabling Autoregressive Models Multi-Token Generation8 Apr 2026 — Autoregressive (AR) language models spend the same compute on ever…
Amazon book picks
Further Reading
Books and field guides related to Why longer AI answers slow down. Use these as the next step if you want deeper reading beyond the article.
Natural Language Processing with Transformers
Provides technical background for generation speed and context.
Build a Large Language Model (From Scratch)
Covers inference mechanics and performance trade-offs.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.



Endnotes
-
Source: arxiv.org
Link: https://arxiv.org/html/2604.07023v1Source snippet
Enabling Autoregressive Models Multi-Token Generation8 Apr 2026 — Autoregressive (AR) [language models]({{ 'language-models/' | relative_url }}) spend the same compute on ever...
-
Source: developer.nvidia.com
Link: https://developer.nvidia.com/blog/an-introduction-to-speculative-decoding-for-reducing-latency-in-ai-inference/Source snippet
NVIDIA DeveloperAn Introduction to Speculative Decoding for Reducing...17 Sept 2025 — The core latency bottleneck in standard autoregres...
-
Source: codefinity.com
Link: https://codefinity.com/courses/v2/54a749e2-1829-4bce-b9b7-1fedaaa1fd65/3fa311cb-f2e0-4fb1-ae9b-c5baee8d11ad/635bf5e1-1149-4701-88c8-0c36baa69e7bSource snippet
Learn Autoregressive Generation MechanismHidden states in transformers carry forward the context from earlier tokens at each ge...
-
Source: databricks.com
Title: llm inference performance engineering best practices
Link: https://www.databricks.com/blog/llm-inference-performance-engineering-best-practicesSource snippet
LLM Inference Performance Engineering: Best Practices12 Oct 2023 — Output length dominates overall response latency: For average latency...
-
Source: medium.com
Title: This has several practical implications.Read more
Link: https://medium.com/%40gezhouz/understanding-llm-response-latency-a-deep-dive-into-input-vs-output-processing-2d83025b8797Source snippet
Understanding LLM Response Latency: A Deep Dive into...July 16, 2025 — The key insight is that output token latency is dramaticall...
Published: July 16, 2025
-
Source: introl.com
Title: kv cache optimization memory efficiency production llms guide
Link: https://introl.com/blog/kv-cache-optimization-memory-efficiency-production-llms-guideSource snippet
KV Cache Optimization: Memory Efficiency for Production LLMsMar 13, 2026 — Memory consumption grows linearly with sequence length and bat...
-
Source: arxiv.org
Link: https://arxiv.org/html/2505.13109v4Source snippet
Boosting KV Cache Retrieval for Efficient LLM InferenceFeb 28, 2026 — However, long contexts pose significant deployment challenges...
-
Source: arxiv.org
Title: arXiv KV Cache Optimization Strategies for Scalable and Efficient LLM Inference
Link: https://arxiv.org/abs/2603.20397 -
Source: arxiv.org
Link: https://arxiv.org/pdf/2603.20397Source snippet
kv cache optimization strategies for scalableby Y Xu · 2026 · Cited by 1 — Because [attention]({{ 'attention/' | relative_url }}) requires storing keys and values for every p...
-
Source: arxiv.org
Title: arXiv Is Long Context All You Need?
Link: https://arxiv.org/html/2501.12372v6Source snippet
Leveraging LLM's...Latency increases (near) linearly with context size, hence there is a clear trade-off between latency and better accu...
-
Source: developer.nvidia.com
Title: optimizing inference for long context and large batch sizes with nvfp4 kv cache
Link: https://developer.nvidia.com/blog/optimizing-inference-for-long-context-and-large-batch-sizes-with-nvfp4-kv-cache/Source snippet
We observe an accuracy loss of less than 1%, compared to BF16 and FP8 baselines, on modern LLM...Read more...
-
Source: developer.nvidia.com
Title: mastering llm techniques inference optimization
Link: https://developer.nvidia.com/blog/mastering-llm-techniques-inference-optimization/Source snippet
LLM Techniques: Inference Optimization17 Nov 2023 — This is because for each request in a batch, the LLM may generate a different number...
-
Source: medium.com
Link: https://medium.com/%40nraman.n6/estimating-llm-inference-memory-requirements-3ab599b7284bSource snippet
y 2–3× · The 2.6GB rule: Each 1K tokens per concurrent...Read more...
-
Source: medium.com
Link: https://medium.com/advanced-[deep-learningSource snippet
it is the context window of a model!Read more...
-
Source: medium.com
Link: https://medium.com/%40mustafa.gencc94/transformers-llms-part-13-kv-cache-pagedattention-and-mla-e9cec8744345Source snippet
Part 13: KV Cache, PagedAttention, and MLAKV caching trades compute for memory. And the memory cost is substantial. For each token in the...
-
Source: medium.com
Link: https://medium.com/%40plienhar/llm-inference-series-4-kv-caching-a-deeper-look-4ba9a77746c8Source snippet
LLM Inference Series: 4. KV caching, a deeper lookOne of the first challenges of the KV cache appears: it grows linearly with the batch s...
-
Source: arxiv.org
Link: https://arxiv.org/html/2412.05896v1Source snippet
XKV: Personalized KV Cache Memory Reduction for Long-...Dec 8, 2024 — When the batch size is 1, FullKV takes 1436 seconds to complete al...
-
Source: codefinity.com
Link: https://codefinity.com/courses/v2/54a749e2-1829-4bce-b9b7-1fedaaa1fd65/5d9ff07b-9724-4a70-a190-4eec4d81c6eb/7938d5b0-5485-49aa-9a64-fa6ce7f5757dSource snippet
The KV-cache stores the computed key and value tensors for each past token. When generating a...Read more...
-
Source: waylandz.com
Title: Wayland Zhang Chapter 16: Training vs Inference
Link: https://waylandz.com/llm-transformer-book-en/chapter-16-training-vs-inference/Source snippet
Wayland ZhangChapter 16: Training vs Inference - Why Generation Is One...Training processes the full known sequence in parallel; inferen...
-
Source: mbrenndoerfer.com
Title: The first generated token requires processing 50 tokens.Read more
Link: https://mbrenndoerfer.com/writing/autoregressive-generation-gpt-text-generationSource snippet
Michael BrenndoerferAutoregressive Generation: How GPT Generates Text...28 Jul 2025 — With naive generation, each step requires a full f...
-
Source: huggingface.co
Link: https://huggingface.co/blog/not-lain/kv-cachingSource snippet
Hugging FaceKV Caching Explained: Optimizing Transformer Inference...Jan 30, 2025 — Key-Value caching is a technique that helps speed up...
-
Source: mbrenndoerfer.com
Title: kv cache memory calculation llm inference gpu
Link: https://mbrenndoerfer.com/writing/kv-cache-memory-calculation-llm-inference-gpuSource snippet
KV Cache Memory: Calculating GPU Requirements for...7 Jan 2026 — Learn to calculate KV cache memory requirements for transformer models...
-
Source: huggingface.co
Title: kv cache quantization
Link: https://huggingface.co/blog/kv-cache-quantizationSource snippet
Unlocking Longer Generation with Key-Value Cache...16 May 2024 — KV Cache Quantization reduces memory usage for long-context text genera...
Published: May 2024
-
Source: huggingface.co
Link: https://huggingface.co/papers?q=end-to-end+per+token+latencySource snippet
Daily Papers5 Jun 2026 — Autoregressive Transformers rely on Key-Value (KV) caching to accelerate inference. However, the linear growth o...
Additional References
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/ankit-gole_llms-diffusionmodels-nlp-activity-7427067922067484672-YfbeSource snippet
Diffusion Models for Text Generation: A New ApproachIf you do not use KV caching, each refinement step can require another full forward p...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/techsachinkumar_scope-kv-cache-optimization-framework-for-activity-7278994363387457536-W6w1Source snippet
Sachin Kumar's PostKey-Value (KV) cache has become a bottleneck of LLMs for long-context generation, with... Add KV cache (session memor...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=RGC-azaTXsISource snippet
KV Cache Demystified: Speeding Up Large Language ModelsIn this video, I break down the Key-Value (KV) Cache a crucial optimization used i...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=IDwTiS4_bKoSource snippet
Key Value Cache from Scratch: The good side and the bad sideThe KV cache speeds up things, but comes with a dark side: memory overload! W...
-
Source: discos.sogang.ac.kr
Link: https://discos.sogang.ac.kr/file/2025/intl_conf/CLOUD_2025_K_Kim.pdfSource snippet
A common technique to mitigate this issue is KV cache offloading, which offloads KV...Read more...
-
Source: sebastianraschka.com
Link: https://sebastianraschka.com/faq/docs/why-context-length-matters.htmlSource snippet
r KV caches during autoregressive generation; higher latency and memory usage.Read more...
-
Source: download.semiconductor.samsung.com
Title: scaling ai inference with kv cache offloading
Link: https://download.semiconductor.samsung.com/resources/white-paper/scaling_ai_inference_with_kv_cache_offloading.pdfSource snippet
AI Inference with KV Cache OffloadingAs context lengths increase and multi-turn interactions become more frequent, GPU memory limitations...
-
Source: reddit.com
Link: https://www.reddit.com/r/Bard/comments/1hd6ww9/prompts_using_over_30k_tokens_have_dramatically/Source snippet
sponse is fast, but with over 30k, it's dramatically slower.Read more...
-
Source: machinelearningmastery.com
Title: kv caching in llms a guide for developers
Link: https://machinelearningmastery.com/kv-caching-in-llms-a-guide-for-developers/Source snippet
KV Caching in LLMs: A Guide for DevelopersFeb 27, 2026 — In this article, you will learn how key-value (KV) caching eliminates redundant...
-
Source: pub.towardsai.net
Link: https://pub.towardsai.net/why-llm-inference-slows-down-with-longer-contexts-c73c686ab517Source snippet
LLM Inference Slows Down with Longer Contexts2 Apr 2026 — It slows down because of how tokens interact, and how those interactions evolve...
Topic Tree