Within Deep Learning
How do speech models hear through noise?
Deep speech models can learn internal acoustic cues that stay useful across speakers, accents, microphones and background noise.
On this page
- Why raw speech is so variable
- How deeper acoustic models build stable cues
- Where speech models still struggle to extrapolate
Page outline Jump by section
Introduction
One of the most impressive features of modern artificial intelligence is that speech recognition systems can often understand words even when recordings are noisy, speakers have different accents, microphones vary in quality, or background sounds interfere with the signal. This is possible because deep learning models do not merely memorise raw audio patterns. Instead, they learn internal representations that emphasise the parts of speech that remain useful across many conditions while reducing sensitivity to irrelevant variation. Research over the past decade has shown that deeper acoustic models can develop increasingly stable speech cues, helping recognition systems perform far better than earlier approaches in noisy environments. At the same time, noise robustness remains incomplete, and speech systems still struggle when confronted with conditions that differ substantially from their training experience. [Microsoft+2Opus Augsburg]microsoft.comIn this paper, we have evaluated the performance of a DNN-based acoustic model for noise…

Why raw speech is so variable
Speech is an unusually difficult signal for artificial intelligence because the same word can sound dramatically different from one recording to the next. Changes in speaker age, accent, speaking speed, microphone placement, room acoustics, background conversations, traffic noise, wind, reverberation and recording equipment can all alter the waveform reaching the system. Yet humans generally perceive the underlying word as the same.
Early speech-recognition systems relied heavily on hand-engineered acoustic features and often degraded sharply when conditions changed. Deep neural networks improved this situation because they could learn directly from large amounts of speech data and discover patterns that remained informative despite environmental variation. Studies on standard speech-recognition benchmarks found that deep acoustic models exhibited surprisingly strong robustness to environmental distortion even without elaborate noise-compensation pipelines that older systems often required. [Microsoft]microsoft.comIn this paper, we have evaluated the performance of a DNN-based acoustic model for noise…
The central challenge is not simply recognising speech in known noise conditions. A useful system must continue working when confronted with new speakers, unfamiliar microphones or background sounds that were never explicitly represented in the training set. That problem has become one of the defining tests of representation learning in speech AI. [arXiv]arxiv.orgarXiv Invariant Representations for Noisy Speech RecognitionarXiv Invariant Representations for Noisy Speech Recognition
How deeper acoustic models build stable cues
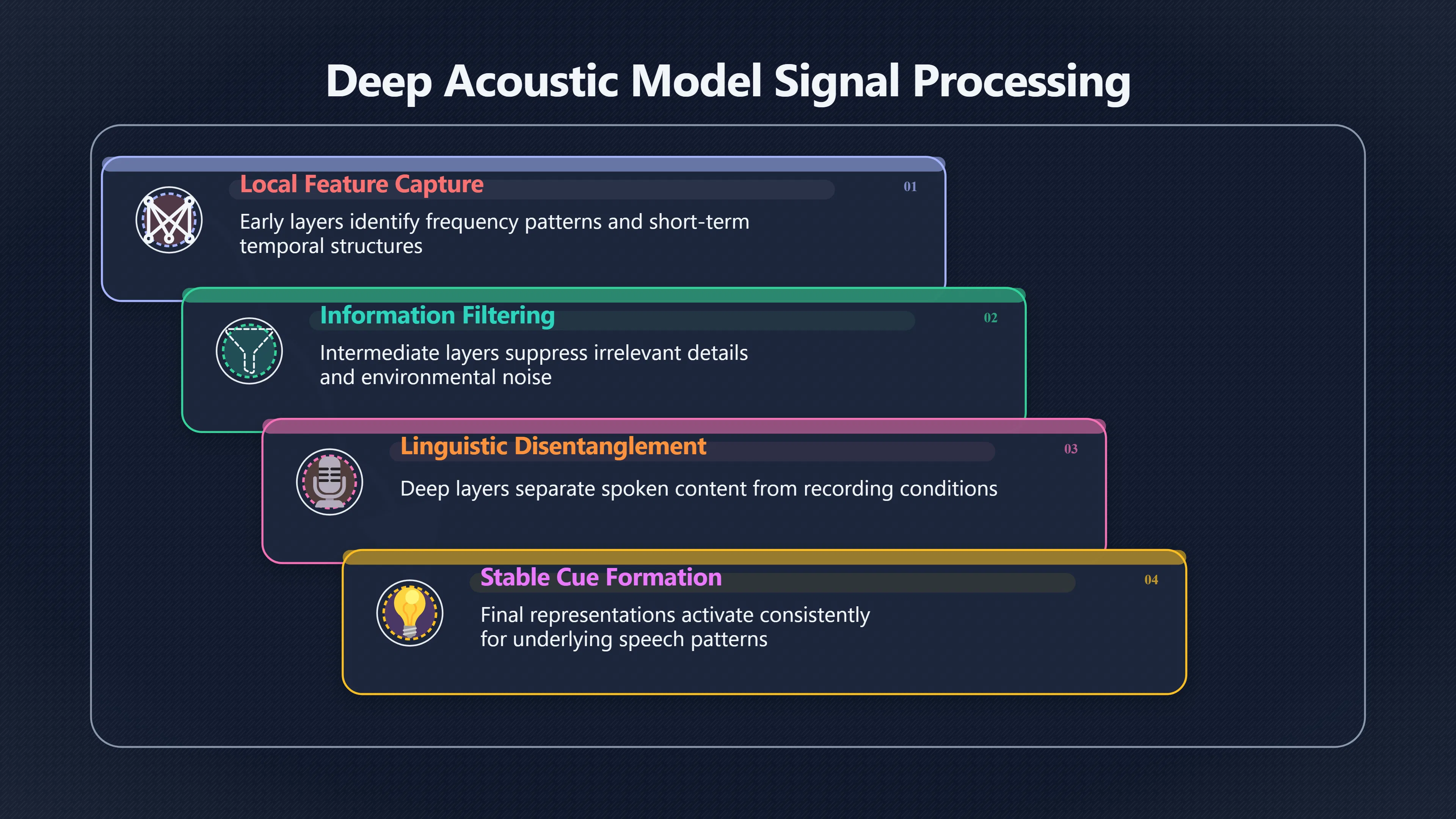
Deep speech models process audio through multiple layers, with each layer transforming the signal into a more useful representation. Early layers often capture local acoustic information such as frequency patterns, transitions and short-term temporal structure. Deeper layers progressively emphasise information that matters for recognising sounds and words while suppressing details that are less relevant.
Researchers studying invariant speech recognition have found evidence that deeper representations increasingly disentangle linguistic content from nuisance factors such as noise and recording conditions. In other words, later layers become better at representing “what was said” rather than “how it happened to sound”. [CBMM]cbmm.mit.eduCBMMUntangling in Invariant Speech RecognitionNovember 12, 2019 — by C Stephenson · Cited by 38 — Finally, we find that the deep representations carry out significant temporal untangl…
This process is especially important because speech varies over time. A spoken word is not a static image but a sequence of changing sounds. Deep networks learn patterns across many moments simultaneously, allowing them to recognise recurring structures even when individual acoustic fragments are distorted. The result is a hierarchy in which higher-level representations can remain relatively stable despite substantial variation in the raw waveform. [CBMM]cbmm.mit.eduCBMMUntangling in Invariant Speech RecognitionNovember 12, 2019 — by C Stephenson · Cited by 38 — Finally, we find that the deep representations carry out significant temporal untangl…
A practical example is the word “hello”. Different speakers may pronounce it differently, and background noise may obscure portions of the signal. Yet the network can learn representations that consistently activate for the underlying speech pattern across many conditions. This ability to form stable internal cues is one reason modern systems outperform earlier speech-recognition methods in realistic environments. [Opus Augsburg]opus.bibliothek.uni-augsburg.deOpus AugsburgDeep learning for environmentally robust speech recognitionby Z Zhang · 2018 · Cited by 499 — Eliminating the negative effec…

Why training data matters as much as architecture
Architecture alone does not create noise robustness. Training strategy plays a major role.
One common approach is multi-condition training, where systems are exposed to many noisy examples during learning. Researchers have repeatedly shown that adding diverse noise conditions helps models become less sensitive to environmental changes. Data augmentation techniques deliberately mix speech with background sounds, reverberation or channel distortions so the model learns to focus on speech-relevant information rather than accidental recording characteristics. [Amazon Science+2PMC]cdn.amazon.scienceAmazon Sciencelearning-noise-invariant-representations-for-robust-speech…September 26, 2018 — by D Liang · Cited by 69 — One simple st…
More recent work goes further by explicitly encouraging models to learn noise-invariant representations. Instead of only requiring noisy and clean recordings to produce the same transcription, these methods push internal representations themselves to remain similar across noise conditions. Experiments have shown that such approaches can improve recognition performance not only on familiar noise but also on previously unseen acoustic environments. [Amazon Science+2arXiv]amazon.scienceLearning noise-invariant representations for robust speech…by D Liang · 2018 · Cited by 69 — We propose invariantrepresentation-learni…
Large-scale self-supervised learning has extended this idea. Systems such as wav2vec 2.0 learn from enormous quantities of unlabelled audio before being adapted to recognition tasks. Because they encounter a broad range of speech characteristics during pretraining, they often develop representations that transfer more effectively across speakers, microphones and domains. ISCA Archive+2campus-fryslan.studenttheses.ub.rug.nl [isca-archive.org]isca-archive.orgISCA Archive Analyzing Domain Shift in Self-Supervised Pre-TrainingISCA Archive Analyzing Domain Shift in Self-Supervised Pre-Training
Why modern speech models cope better with accents and microphones
Noise is not the only source of variability. Accent differences, vocal characteristics and recording hardware can create shifts as large as environmental noise.
Modern deep speech models benefit from exposure to diverse data and from representation-learning techniques that separate linguistic content from superficial acoustic details. Continued pretraining and adaptation methods have been shown to improve robustness not only to background noise but also to microphone variation and demographic differences among speakers. [arXiv]arxiv.orgCPT-Boosted Wav2vec2.0: Towards Noise Robust Speech…13 Sept 2024 — In this paper, we propose continued pretraining (CPT) as an ef…
Large-scale training datasets contribute significantly to this effect. Models trained on diverse internet-scale audio collections encounter a much wider range of speaking styles, recording qualities and acoustic environments than earlier systems trained on carefully controlled laboratory speech. Exposure to this diversity encourages representations that generalise beyond a single recording setup. [Medium]medium.comWhisper: Robust Speech Recognition via Large-ScaleNoisy environments and varying recording quality. - Different accents, speaking styles, and domains. -…Read more…
However, robustness is rarely absolute. A model may appear highly reliable on benchmark datasets while still struggling when deployed in specialised environments such as aviation communications, classrooms, industrial settings or low-resource languages. Performance often depends on whether the model has previously encountered sufficiently similar conditions. [arXiv]arxiv.orgOpen source on arxiv.org.

Where speech models still struggle to extrapolate
Despite major progress, speech recognition remains vulnerable to extreme acoustic variation.
Several research programmes have highlighted that deep models can still suffer when confronted with unseen noise types, severe reverberation, unusual recording channels or substantial domain shifts. Systems that perform well on benchmark tasks may experience significant error increases when operating in unfamiliar real-world conditions. [CMU School of Computer Science]cs.cmu.eduCMU School of Computer ScienceRobust Features in Deep Learning-Based Speech Recognitionby V Mitra · Cited by 47 — DNNs are data sensitive…
This limitation reveals an important distinction between robustness and true understanding. A speech model may learn highly effective invariances from its training data, yet those invariances remain shaped by experience. When conditions move far outside that experience, performance can deteriorate unexpectedly. Researchers continue to investigate domain adaptation, self-supervised learning, speech enhancement and invariant representation learning as ways to reduce this gap. [arXiv+2arXiv]arxiv.orgarXiv Invariant Representations for Noisy Speech RecognitionarXiv Invariant Representations for Noisy Speech Recognition
The broader lesson for understanding artificial intelligence is that deep learning succeeds not because it removes variability from the world, but because it learns representations that make important patterns easier to detect despite that variability. Speech recognition provides one of the clearest demonstrations of this principle: countless noisy and imperfect sounds are transformed into internal cues that remain useful across many speakers, environments and recording conditions, even though the process remains imperfect and incomplete. [CBMM+2Intel Community]cbmm.mit.eduCBMMUntangling in Invariant Speech RecognitionNovember 12, 2019 — by C Stephenson · Cited by 38 — Finally, we find that the deep representations carry out significant temporal untangl…
Amazon book picks
Further Reading
Books and field guides related to How do speech models hear through noise?. Use these as the next step if you want deeper reading beyond the article.
Speech and Language Processing: Pearson New International Edi...
Covers speech recognition, acoustic modelling, and robustness.
Deep Learning
Rating: 3.5/5 from 6 Google Books ratings
Provides the deep learning foundations used in modern speech systems.
Artificial Intelligence
Rating: 4.5/5 from 10 Google Books ratings
Places deep learning within the wider AI landscape.
Fundamentals of Speech Recognition
Explains the core challenges of recognising speech under varying conditions.
eBay marketplace picks
Marketplace Samples
Topic-anchored marketplace searches for visual, collectible, or second-hand items related to this page.


Endnotes
-
Source: microsoft.com
Link: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/0007398.pdfSource snippet
In this paper, we have evaluated the performance of a DNN-based acoustic model for noise...
-
Source: arxiv.org
Title: arXiv Invariant Representations for Noisy Speech Recognition
Link: https://arxiv.org/abs/1612.01928 -
Source: cs.cmu.edu
Link: https://www.cs.cmu.edu/afs/cs/user/robust/www/Papers/MitraEtAl_100116.pdfSource snippet
CMU School of Computer ScienceRobust Features in Deep Learning-Based Speech Recognitionby V Mitra · Cited by 47 — DNNs are data sensitive...
-
Source: cbmm.mit.edu
Title: CBMMUntangling in Invariant Speech Recognition
Link: https://cbmm.mit.edu/sites/default/files/publications/9583-untangling-in-invariant-speech-recognition.pdfSource snippet
November 12, 2019 — by C Stephenson · Cited by 38 — Finally, we find that the deep representations carry out significant temporal untangl...
Published: November 12, 2019
-
Source: community.intel.com
Title: New Research Shows How Neural Networks Process Invariant Speech
Link: https://community.intel.com/t5/Blogs/Tech-Innovation/Artificial-Intelligence-AI/New-Research-Shows-How-Neural-Networks-Process-Invariant-Speech/post/1335680Source snippet
Intel CommunityNew Research Shows How Neural Networks Process...20 Dec 2019 — Taken together, these findings shed light on how deep audi...
-
Source: cdn.amazon.science
Link: https://cdn.amazon.science/a8/2a/aef830bf4a85bd43ca4618dcb2b2/learning-noise-invariant-representations-for-robust-speech-recognition.pdfSource snippet
Amazon Sciencelearning-noise-invariant-representations-for-robust-speech...September 26, 2018 — by D Liang · Cited by 69 — One simple st...
Published: September 26, 2018
-
Source: pmc.ncbi.nlm.nih.gov
Title: PMCIncorporating Noise Robustness in Speech Command
Link: https://pmc.ncbi.nlm.nih.gov/articles/PMC7219662/Source snippet
by A Pervaiz · 2020 · Cited by 82 — A novel technique is proposed for noise robustness by augmenting noise in training data. Our propo...
-
Source: arxiv.org
Link: https://arxiv.org/pdf/1705.10874Source snippet
Besides, with the rise of big data era, it is now feasible...Read more...
-
Source: amazon.science
Link: https://www.amazon.science/publications/learning-noise-invariant-representations-for-robust-speech-recognitionSource snippet
Learning noise-invariant representations for robust speech...by D Liang · 2018 · Cited by 69 — We propose invariantrepresentation-learni...
-
Source: arxiv.org
Title: arXiv Learning Noise-Invariant Representations for Robust Speech Recognition
Link: https://arxiv.org/abs/1807.06610 -
Source: isca-archive.org
Title: ISCA Archive Analyzing Domain Shift in Self-Supervised Pre-Training
Link: https://www.isca-archive.org/interspeech_2021/hsu21_interspeech.pdf -
Source: campus-fryslan.studenttheses.ub.rug.nl
Title: MSc S4802829 CS Su
Link: https://campus-fryslan.studenttheses.ub.rug.nl/543/1/MSc-S4802829-CS-Su.pdfSource snippet
A Fine-Tuning Approach Using wav2vec 2.0by C Su · 2024 — This model excels in extracting robust speech representations, which are crucial...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2203.16822 -
Source: arxiv.org
Link: https://arxiv.org/html/2409.14494v1Source snippet
CPT-Boosted Wav2vec2.0: Towards Noise Robust Speech...13 Sept 2024 — In this paper, we propose continued pretraining (CPT) as an ef...
-
Source: medium.com
Title: Whisper: Robust Speech Recognition via Large-Scale
Link: https://medium.com/%40krishnaprasath42213/whisper-robust-speech-recognition-via-large-scale-weak-supervision-2b818a86ce08Source snippet
Noisy environments and varying recording quality. - Different accents, speaking styles, and domains. -...Read more...
-
Source: isca-archive.org
Title: du14 interspeech
Link: https://www.isca-archive.org/interspeech_2014/du14_interspeech.pdfSource snippet
mapping from...
-
Source: opus.bibliothek.uni-augsburg.de
Link: https://opus.bibliothek.uni-augsburg.de/opus4/files/71717/71717.pdfSource snippet
Opus AugsburgDeep learning for environmentally robust speech recognitionby Z Zhang · 2018 · Cited by 499 — Eliminating the negative effec...
-
Source: huggingface.co
Link: https://huggingface.co/papers?q=acoustic+robustness+bottleneckSource snippet
Daily Papers21 May 2026 — Robust Speech Recognition via Large-Scale Weak Supervision · We study the capabilities of speech processing sys...
Published: May 2026
Additional References
-
Source: datamundi.ai
Link: https://datamundi.ai/white-paper/from-speech-recognition-to-speech-reasoning-building-the-data-foundations-for-the-next-generation-of-voice-ai/Source snippet
From Speech Recognition to Speech ReasoningExplore the future of Speech AI and how it transforms voice interfaces into smart systems that...
-
Source: oamonitor.ireland.openaire.eu
Link: https://oamonitor.ireland.openaire.eu/rpo/rcsi/search/publication?pid=10.1109%2Ficassp.2013.6639100 -
Source: iris.polito.it
Link: https://iris.polito.it/retrieve/db3d29d0-13fe-4deb-a998-e081e525925f/Koudounas_PhD_Thesis.pdfSource snippet
Robust, [Responsible]({{ 'responsible-ai/' | relative_url }}) and Trustworthy Speech...This thesis introduces comprehensive frameworks and methodologies for build- ing robust, re...
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/354221587_Robust_wav2vec_20_Analyzing_Domain_Shift_in_Self-Supervised_Pre-TrainingSource snippet
Analyzing Domain Shift in Self-Supervised Pre-Training21 May 2026 — Speech enhancement (SE) aims to recover clean speech signals from noi...
Published: May 2026
-
Source: sri.com
Link: https://www.sri.com/wp-content/uploads/2021/12/evaluating_robust_features_on_deep_neural_networks_for_speech_recognition_in_noisy_and_channel_mismatched_conditions.pdfSource snippet
We present an exhaustive study on the use...Read...
-
Source: aclanthology.org
Title: 2025.naacl industry.74
Link: https://aclanthology.org/2025.naacl-industry.74.pdfSource snippet
Pisets: A Robust Speech Recognition System for Lectures...by I Bondarenko · 2025 · Cited by 1 — This paper presents a novel framework ai...
-
Source: youtube.com
Title: Fellowship: Robust Self Supervised Audio Visual Speech Recognition
Link: https://www.youtube.com/watch?v=CS4t0iRU034Source snippet
Unsupervised Speech Enhancement - YouTube Unsupervised Speech Enhancement - YouTube...
-
Source: aclanthology.org
Title: 2020.findings emnlp.106
Link: https://aclanthology.org/2020.findings-emnlp.106.pdfSource snippet
8000 hours of diverse and noisy speech, using an extended version of contrastive predictive coding model:...Read more...
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/311458959_Invariant_Representations_for_Noisy_Speech_RecognitionSource snippet
We use ideas from recent...Read more...
-
Source: youtube.com
Title: Conformer-2: A state-of-the-art speech recognition model
Link: https://www.youtube.com/watch?v=r-CEc_ZYV9ESource snippet
Fellowship: Robust Self Supervised Audio Visual Speech Recognition...
Topic Tree