Within Language Models
Why attention made prediction scale
The Transformer architecture made attention-based sequence modeling easier to scale, helping next-token prediction become far more capable.
On this page
- What changed from recurrent sequence models
- How attention connects tokens across context
- Why scaling made simple prediction more powerful
Page outline Jump by section
Introduction
The 2017 paper Attention Is All You Need did not change the basic objective of language models. They still learned by predicting the next token in a sequence. What changed was the architecture used to perform that prediction. By replacing recurrent processing with self-attention, the Transformer made it practical to train much larger models on far more data and much longer contexts. That shift turned next-token prediction from a useful language-modelling technique into the foundation of modern large language models and chatbots. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
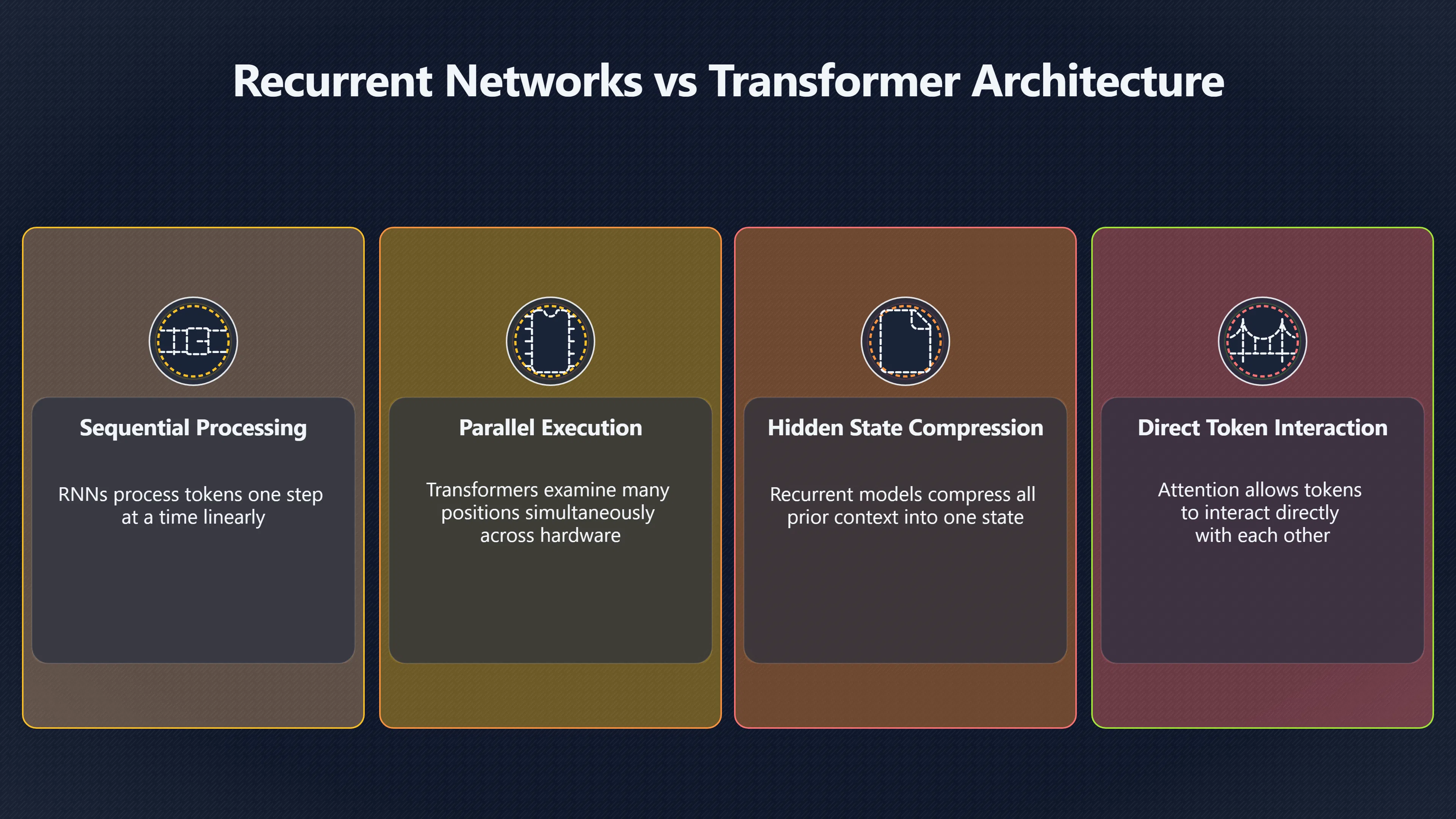
 Before the Transformer, many leading sequence models relied on recurrent neural networks (RNNs) or their variants such as Long Short-Term Memory (LSTM) networks. These systems processed text one step at a time. The Transformer showed that a model could instead examine relationships among tokens through attention mechanisms while processing many positions in parallel. That design decision proved to be one of the most important technical milestones in the history of artificial intelligence. [arXiv+2Wikipedia]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
Before the Transformer, many leading sequence models relied on recurrent neural networks (RNNs) or their variants such as Long Short-Term Memory (LSTM) networks. These systems processed text one step at a time. The Transformer showed that a model could instead examine relationships among tokens through attention mechanisms while processing many positions in parallel. That design decision proved to be one of the most important technical milestones in the history of artificial intelligence. [arXiv+2Wikipedia]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
What changed from recurrent sequence models
The key innovation was not the idea of predicting the next token. Language models had been doing that for decades. The breakthrough was changing how information flowed through the network.
In recurrent models, each token is processed after the previous one. The model carries forward an internal state that attempts to summarise everything seen so far. This sequential structure creates two limitations. First, training is difficult to parallelise because each step depends on the completion of the previous step. Second, information from distant parts of a sequence can become harder to preserve and use effectively. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
The Transformer removed recurrence entirely. Instead of forcing information through a chain of sequential states, it allowed each token representation to interact directly with other relevant tokens through attention. The original paper explicitly described the architecture as being based solely on attention mechanisms, dispensing with recurrence and convolutions. The result was a model that trained faster, scaled more efficiently across hardware, and achieved state-of-the-art translation performance at the time. [arXiv+2arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
For next-token prediction, this meant that the model no longer had to compress all prior context into a single evolving hidden state. Relevant information could be accessed more directly when estimating the next token. [arXiv]arxiv.orgarXiv Mechanics of Next Token Prediction with Self-AttentionMechanics of Next Token Prediction with Self-AttentionMarch 12, 2024 — by Y Li · 2024 · Cited by 73 — Abstract:Transformer-based lan…
How attention connects tokens across context
Self-attention is the mechanism that made the Transformer distinctive.
When predicting the next token, the model examines the tokens already present in the context. Rather than treating nearby tokens as inherently more important than distant ones, self-attention allows the model to calculate which earlier tokens are most relevant to the current prediction. Each token can effectively “look at” other tokens and assign different weights to them. [Sebastian Raschka’s Magazine]magazine.sebastianraschka.comvisual attention variantsSebastian Raschka’s MagazineA Visual Guide to Attention Variants in Modern LLMs22 Mar 2026 — In transformers, that mechanism is called se…
Consider a sentence containing a pronoun such as:
The scientist presented her findings after months of research.
To predict words that follow, the model benefits from connecting “her” with “scientist”. In a recurrent architecture, that relationship must survive through a chain of intermediate processing steps. In a Transformer, attention creates a more direct pathway between those tokens. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
This ability becomes even more important in longer documents. A question at the end of a prompt may depend on information introduced many paragraphs earlier. Attention allows the model to establish links across that context without relying entirely on a compressed memory state. The original Transformer also introduced multi-head attention, allowing the model to track different kinds of relationships simultaneously. One attention head might focus on grammatical structure while another focuses on semantic relationships or topic continuity. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
The result is not human understanding in the ordinary sense. The model is still performing statistical prediction. However, it can use contextual information much more effectively when making those predictions. [arXiv]arxiv.orgarXiv Mechanics of Next Token Prediction with Self-AttentionMechanics of Next Token Prediction with Self-AttentionMarch 12, 2024 — by Y Li · 2024 · Cited by 73 — Abstract:Transformer-based lan…

Why scaling made simple prediction more powerful
The most important long-term consequence of the Transformer was scalability.
Researchers quickly discovered that Transformer-based models improved predictably as they were trained with more parameters, more data, and more computing power. Because the architecture could process training examples in parallel, organisations could train models at a scale that was far more difficult with earlier recurrent approaches. [arXiv+2Wikipedia]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
This mattered because next-token prediction is a data-hungry objective. A model trained on a small corpus learns limited patterns. A model trained on vast portions of the internet, books, code repositories, and other text sources learns an enormous range of statistical relationships. The Transformer provided a practical way to exploit that scale. [Sebastian Raschka, PhD+2arXiv]sebastianraschka.comOpen source on sebastianraschka.com.
An important historical irony is that the original paper focused on machine translation rather than chatbots. The authors demonstrated strong results on translation benchmarks and emphasised efficiency and parallelisation. Yet the architectural changes they introduced turned out to be ideally suited for large-scale self-supervised language modelling, where the task is simply to predict missing or future tokens. [arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
As larger Transformer models were trained, capabilities that seemed unrelated to next-token prediction began to emerge. Models became increasingly effective at summarisation, question answering, coding assistance, instruction following, and dialogue. The training objective remained fundamentally the same, but the scale of the model and the richness of its learned representations expanded dramatically. [arXiv+2arXiv]arxiv.orgarXiv Mechanics of Next Token Prediction with Self-AttentionMechanics of Next Token Prediction with Self-AttentionMarch 12, 2024 — by Y Li · 2024 · Cited by 73 — Abstract:Transformer-based lan…
The lasting significance of the Transformer shift
The Transformer did not replace next-token prediction with a new goal. Instead, it made that goal vastly more productive.
Before 2017, predicting the next token was a useful but relatively constrained technique. After the Transformer, the same objective could be applied to larger datasets, longer contexts, and much larger models. Attention provided a more flexible way to connect information across text, while parallel processing made large-scale training economically and technically feasible. [arXiv+2arXiv]arxiv.orgarXiv Attention Is All You NeedAttention Is All You NeedJune 12, 2017…
Modern chatbots are therefore not the result of abandoning next-token prediction. They are largely the result of combining that simple objective with an architecture that scales extraordinarily well. The Transformer transformed next-token prediction from a specialised language-modelling method into the core engine of contemporary generative AI. [arXiv+2arXiv]arxiv.orgarXiv Mechanics of Next Token Prediction with Self-AttentionMechanics of Next Token Prediction with Self-AttentionMarch 12, 2024 — by Y Li · 2024 · Cited by 73 — Abstract:Transformer-based lan…

Amazon book picks
Further Reading
Books and field guides related to Why attention made prediction scale. Use these as the next step if you want deeper reading beyond the article.
Hands-On Large Language Models
Explains transformers, attention, scaling, and next-token prediction in practical terms.
Natural Language Processing with Transformers
Focused directly on transformer architectures and their NLP applications.
Build a Large Language Model (From Scratch)
Shows how transformer-based language models are built and trained.
Transformers for Natural Language Processing
Covers self-attention, encoder-decoder models, BERT, GPT, and scaling concepts.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: arxiv.org
Title: arXiv Attention Is All You Need
Link: https://arxiv.org/abs/1706.03762Source snippet
Attention Is All You NeedJune 12, 2017...
Published: June 12, 2017
-
Source: Wikipedia
Title: Transformer (deep learning)
Link: https://en.wikipedia.org/wiki/Transformer_%28deep_learning%29Source snippet
Transformer (deep learning)In deep learning, the transformer is a family of artificial neural network architectures based on the multi...
-
Source: arxiv.org
Link: https://arxiv.org/pdf/1706.03762Source snippet
We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with...
-
Source: arxiv.org
Title: arXiv Mechanics of Next Token Prediction with Self-Attention
Link: https://arxiv.org/abs/2403.08081Source snippet
Mechanics of Next Token Prediction with Self-AttentionMarch 12, 2024 — by Y Li · 2024 · Cited by 73 — Abstract:Transformer-based lan...
Published: March 12, 2024
-
Source: Wikipedia
Title: Attention Is All You Need
Link: https://en.wikipedia.org/wiki/Attention_Is_All_You_NeedSource snippet
Attention Is All You Need"Attention Is All You Need" is a 2017 research paper in [machine learning]({{ 'machine-learning/' | relative_url }}) authored by eight scientists and eng...
-
Source: arxiv.org
Link: https://arxiv.org/html/2509.24435v1Source snippet
Alternatives To Next Token Prediction In Text GenerationSep 29, 2025 — Defined as the task of predicting the next subword token given the...
-
Source: arxiv.org
Link: https://arxiv.org/html/1706.03762v7 -
Source: arxiv.org
Link: https://arxiv.org/abs/2104.08771Source snippet
Adapting Pretrained Transformers for Machine Translationby M Gheini · 2021 · Cited by 249 — We study the power of cross-attention in the...
-
Source: artificial-intelligence.blog
Title: attention is all you need
Link: https://www.artificial-intelligence.blog/ai-news/attention-is-all-you-needSource snippet
Revolutionizing AI with the Transformer Model: “Attention Is...12 Jun 2025 — In 2017, a groundbreaking paper titled “Attention Is All Yo...
-
Source: magazine.sebastianraschka.com
Title: visual attention variants
Link: https://magazine.sebastianraschka.com/p/visual-attention-variantsSource snippet
Sebastian Raschka’s MagazineA Visual Guide to Attention Variants in Modern LLMs22 Mar 2026 — In transformers, that mechanism is called se...
-
Source: sebastianraschka.com
Link: https://sebastianraschka.com/faq/docs/next-token-prediction.html -
Source: academia.edu
Title: Attention Is All You Need
Link: https://www.academia.edu/113744173/Attention_Is_All_You_NeedSource snippet
(PDF) Attention Is All You NeedEffective approaches to attention- based neural machine translation. arXiv preprint arXiv:1508.04025, 2015...
Additional References
-
Source: medium.com
Link: https://medium.com/%40weidagang/coffee-time-papers-attention-is-all-you-need-3c7d6bc75eabSource snippet
Coffee Time Papers: Attention Is All You NeedThe paper introduces the Transformer, a new neural network architecture that relies entirely...
-
Source: medium.com
Link: https://medium.com/%40pacosun/how-large-language-models-learn-to-predict-1edd6ab8d0d7Source snippet
How Large Language Models Learn to PredictThe answer is simple: they predict what comes next. LLMs are trained with one goal in mind, and...
-
Source: research.google
Link: https://research.google/pubs/mechanics-of-next-token-prediction-with-transformers/Source snippet
Mechanics of Next Token Prediction with TransformersTransformer-based language models are trained on large datasets to predict the next t...
-
Source: zeroentropy.dev
Link: https://zeroentropy.dev/concepts/large-language-model/Source snippet
LLM: transformer next-token predictors as reasoning enginesA large language model is a transformer trained on vast text to predict the ne...
-
Source: inspirehep.net
Link: https://inspirehep.net/literature/2702854 -
Source: github.com
Link: https://github.com/LMM101/Awesome-Multimodal-Next-Token-Prediction -
Source: towardsai.net
Link: https://towardsai.net/p/machine-learning/attention-is-all-you-need-a-deep-dive-into-the-revolutionary-transformer-architectureSource snippet
A Deep Dive into the Revolutionary Transformer ArchitectureApr 10, 2025 — This paper introduced the Transformer architecture, a novel app...
-
Source: ai.stackexchange.com
Title: why people always say the transformer is parallelizable while the self attention
Link: https://ai.stackexchange.com/questions/29903/why-people-always-say-the-transformer-is-parallelizable-while-the-self-attentionSource snippet
people always say the Transformer is parallelizable...29 Jul 2021 — The reason transformers are parallelizable while RNNs are not is not...
-
Source: omerseyfeddinkoc.medium.com
Title: why attention is all you need changed ai forever 02e42797905e
Link: https://omerseyfeddinkoc.medium.com/why-attention-is-all-you-need-changed-ai-forever-02e42797905eSource snippet
“Attention Is All You Need” Changed AI ForeverThis paper introduced the Transformer model, an architecture that completely eliminated rec...
-
Source: lesswrong.com
Title: Less Wrong How did ‘large’ language models get that way?
Link: https://www.lesswrong.com/posts/gcKhnqysxj9bBvbWD/how-did-large-language-models-get-that-way-the-role-ofSource snippet
The role of...May 3, 2026 — The milestone transformer architecture, introduced in the 2017 paper Attention Is All You Need, totally upen...
Published: May 3, 2026
Topic Tree