Within GPT generators
How Can a Model Learn During a Prompt?
Large language models can often infer a task from examples in a prompt without changing their underlying parameters.
On this page
- From zero shot to few shot prompting
- Using prompt examples as temporary task clues
- Competing explanations for in context learning
Page outline Jump by section
Introduction
One of the most surprising features of modern large language models is that they can often perform a new task without being retrained. A model can be shown a few examples inside a prompt and then continue the pattern correctly, even though its underlying parameters remain unchanged. This behaviour is known as in-context learning.
 For example, if a prompt contains several English-to-French translation pairs and then a new English sentence, the model will often produce the French translation. No new training run occurs, no weights are updated, and no gradient descent takes place. Instead, the model uses information contained in the current prompt to infer what kind of task is being requested and how to continue the sequence. This capability became a defining feature of GPT-style systems and helped transform language models from specialised tools into flexible generators. [arXiv]arxiv.orgarXiv[2005.14165] Language Models are Few-Shot LearnersMay 28, 2020 — by TB Brown · 2020 · Cited by 71969 — GPT-3 achieves strong perform…
For example, if a prompt contains several English-to-French translation pairs and then a new English sentence, the model will often produce the French translation. No new training run occurs, no weights are updated, and no gradient descent takes place. Instead, the model uses information contained in the current prompt to infer what kind of task is being requested and how to continue the sequence. This capability became a defining feature of GPT-style systems and helped transform language models from specialised tools into flexible generators. [arXiv]arxiv.orgarXiv[2005.14165] Language Models are Few-Shot LearnersMay 28, 2020 — by TB Brown · 2020 · Cited by 71969 — GPT-3 achieves strong perform…
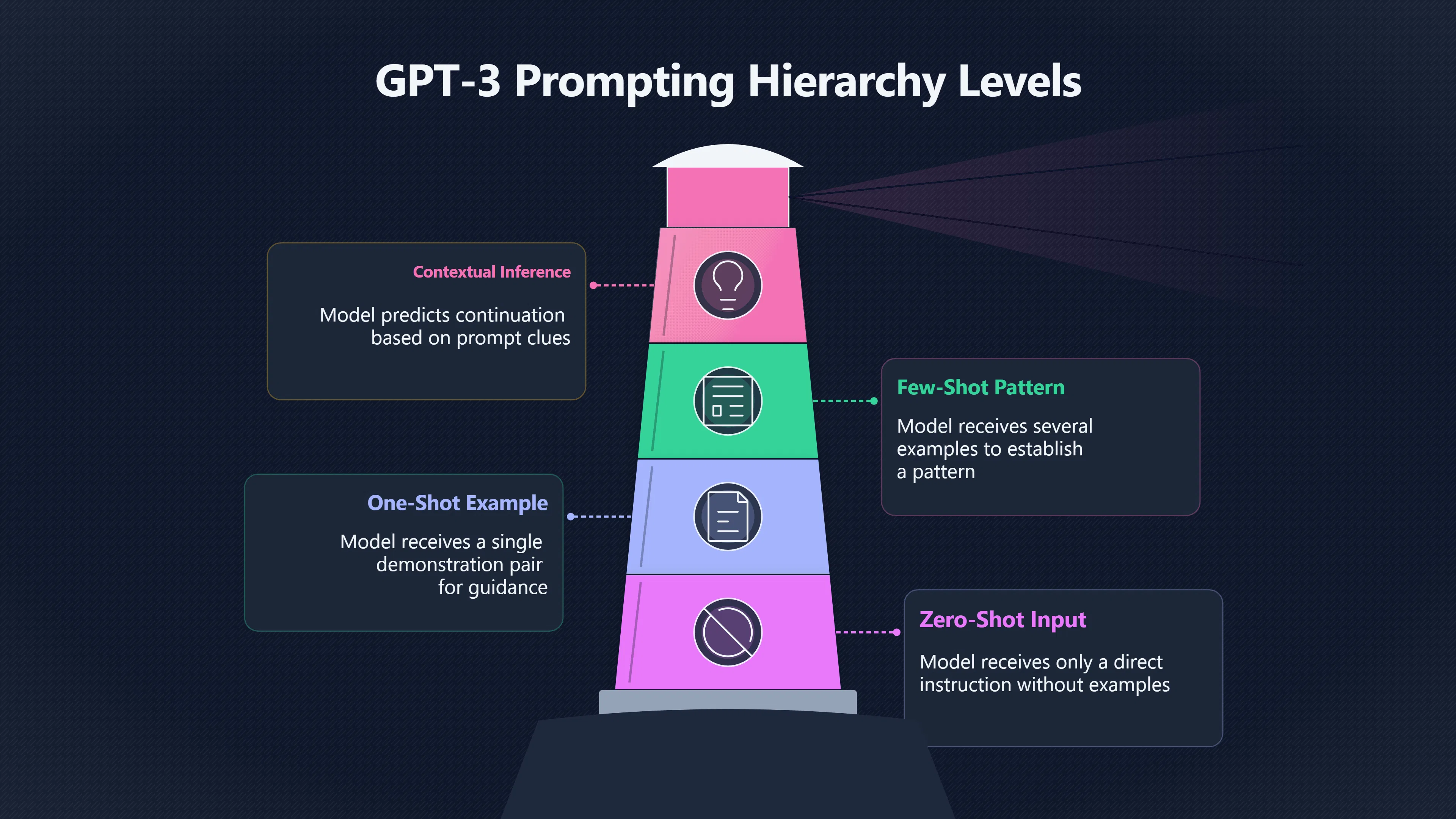
From Zero-Shot to Few-Shot Prompting
Researchers commonly distinguish three levels of prompting:
- Zero-shot: the model receives only an instruction.
- One-shot: the model receives a single example.
- Few-shot: the model receives several examples demonstrating the task.
GPT-3 popularised these distinctions and demonstrated that performance often improved when examples were included in the prompt. Importantly, these improvements occurred without fine-tuning or gradient updates. The task specification existed entirely within the text supplied to the model. [arXiv+2arXiv]arxiv.orgarXiv Language Models are Few-Shot LearnersLanguage Models are Few-Shot LearnersMay 28, 2020 — by TB Brown · 2020 · Cited by 73753 — For each task, we evaluate GPT-3 under 3 c…
Consider a sentiment-classification prompt:
Review: “Excellent service.” → Positive Review: “Terrible experience.” → Negative Review: “Very helpful staff.” →?
The model can infer that it should classify sentiment and produce “Positive”. Nothing inside the model has been permanently altered. The prompt temporarily establishes a pattern, and the model predicts the continuation most consistent with that pattern. [arXiv]arxiv.orgarXiv[2005.14165] Language Models are Few-Shot LearnersMay 28, 2020 — by TB Brown · 2020 · Cited by 71969 — GPT-3 achieves strong perform…
This ability is particularly valuable because it reduces the need for separate task-specific training. A single pre-trained model can switch between translation, summarisation, classification, coding, and many other activities simply by changing the prompt format.
Using Prompt Examples as Temporary Task Clues
A useful way to think about in-context learning is that examples inside the prompt act as temporary clues about the task currently being performed.
During pre-training, large language models encounter countless patterns in text: question-answer pairs, translations, definitions, code snippets, lists, tables, dialogues, and explanations. As a result, they learn statistical regularities about how these patterns typically continue. [arXiv]arxiv.orgarXiv[2005.14165] Language Models are Few-Shot LearnersMay 28, 2020 — by TB Brown · 2020 · Cited by 71969 — GPT-3 achieves strong perform…
When the model sees examples in a prompt, it does not store them permanently. Instead, the examples become part of the current context window. The self-attention mechanism allows the model to compare different parts of that context and identify relationships between inputs and outputs.
For instance, suppose a prompt contains:
red → colour dog → animal oak →?
The model can detect that the examples map specific objects to broader categories. It can then continue the pattern with “tree”. The model is not creating a new permanent classifier. It is temporarily inferring the rule that connects the examples. [Oxford University Research Archive]ora.ox.ac.ukford University Research ArchiveUnderstanding in-context learning in transformers and LLMs…by S Bhattamishra · 2024 · Cited by 86 —…
This distinction is crucial:
- Training-time learning changes model parameters. [stackoverflow.com]stackoverflow.comChanges in GPT2/GPT3 model during few shot learningDuring transfer learning, we take a pre-trained network and some observation pair (inp…
- In-context learning changes only the information available within the current prompt.
Once the conversation ends and the context disappears, the temporary adaptation disappears as well. The model reverts to the same underlying parameters it had before. [arXiv]arxiv.orgarXiv[2005.14165] Language Models are Few-Shot LearnersMay 28, 2020 — by TB Brown · 2020 · Cited by 71969 — GPT-3 achieves strong perform…

Why It Looks Like Learning Even Though Nothing Is Retrained
The term “learning” can be misleading because no traditional learning algorithm runs during inference.
In conventional machine learning, a model improves by adjusting weights through optimisation. In in-context learning, the weights remain fixed. Yet the model often behaves as though it has learned a new rule. Researchers therefore describe the phenomenon as a form of learning within the context window rather than learning through parameter updates. [yacinemahdid.com]yacinemahdid.comwhats in context learning in deepWhat's In-Context Learning in Deep Learning and Why Is…20 Aug 2024 — In-context learning is loosely defined as showing a few examples…
A simple analogy is a person taking an open-book test. Their brain does not change dramatically during the exam, but access to notes allows them to perform tasks they might otherwise struggle with. Similarly, the prompt supplies temporary information that the model can use while generating its response.
The comparison is imperfect because language models are not consciously consulting notes. However, it captures the key idea: improved performance can arise from additional context rather than permanent learning.
What Attention Mechanisms Contribute
The Transformer architecture makes in-context learning possible because every generated token can attend to relevant information earlier in the prompt.
Self-attention allows the model to identify patterns, relationships, and examples within the context window. When generating a new token, the model can focus on previous demonstrations and use them as guides for prediction. [Oxford University Research Archive]ora.ox.ac.ukford University Research ArchiveUnderstanding in-context learning in transformers and LLMs…by S Bhattamishra · 2024 · Cited by 86 —…
For example, if several input-output pairs appear in a prompt, attention layers can connect the new query to similar earlier examples. Rather than recalling a memorised answer, the model may identify a pattern that is currently active in the prompt and continue it.
This helps explain why prompt formatting matters. Small changes in examples, ordering, or wording can influence which patterns the model identifies and follows.
Competing Explanations for In-Context Learning
Researchers agree that in-context learning exists, but they do not fully agree on why it works.
One family of explanations views the model as performing a form of implicit meta-learning. During pre-training, the model may learn general procedures for extracting rules from examples. When presented with a new prompt, it effectively applies those procedures to infer the task. Evidence from theoretical and empirical studies suggests that Transformers can learn algorithms that adapt to patterns appearing in context rather than relying solely on memorised knowledge. [Oxford University Research Archive]ora.ox.ac.ukford University Research ArchiveUnderstanding in-context learning in transformers and LLMs…by S Bhattamishra · 2024 · Cited by 86 —…
Another influential explanation focuses on specific Transformer circuits known as induction heads. Research from Anthropic’s Transformer Circuits programme identified attention patterns that appear capable of matching repeated sequences and copying continuations. These circuits emerge during training at roughly the same point that models exhibit a sharp increase in in-context learning ability. [arXiv+2Transformer Circuits]arxiv.orgarXiv In-context Learning and Induction HeadsIn-context Learning and Induction HeadsSeptember 24, 2022…
An induction head can be understood as a “match-and-copy” mechanism. If a model encounters a pattern such as:
A B… A
it can learn to predict that B is likely to follow the second A because it appeared after the first one. This simple capability can support many forms of pattern completion and may contribute substantially to in-context learning. [arXiv+2lesswrong.com]arxiv.orgarXiv In-context Learning and Induction HeadsIn-context Learning and Induction HeadsSeptember 24, 2022…
A third line of research argues that Transformer layers may behave somewhat like temporary learning systems. Recent theoretical work suggests that interactions between attention and feed-forward layers can create context-dependent computations resembling low-rank updates to internal representations, allowing the model to adapt behaviour without altering stored parameters. These ideas remain active areas of research rather than settled explanations. [Google Research]research.googleGoogle ResearchThe implicit dynamics of in-context learningSpecifically, we show how a transformer block implicitly transforms a context…

What In-Context Learning Can and Cannot Do
In-context learning is powerful, but it has limits. [thegradient.pub]thegradient.pubin context learning in contextIn-Context Learning, In Context29 Apr 2023 — When studying transformers under the lens of mechanistic interpretability, researchers at An…
It works best when:
- The prompt contains clear examples. [intuitivepapers.ai]intuitivepapers.aiLanguage Models are Few-Shot LearnersGPT-3 is a 175-billion-parameter language model that learns new tasks from a few examples in its pro…
- The task resembles patterns seen during pre-training.
- The required information fits within the context window.
- The underlying reasoning is not too complex.
Performance often degrades when examples are ambiguous, contradictory, or excessively long. Unlike genuine retraining, in-context learning does not permanently improve the model’s capabilities. The model cannot accumulate durable knowledge from one conversation to the next unless its parameters are updated through a separate training process. [arXiv]arxiv.orgarXiv[2005.14165] Language Models are Few-Shot LearnersMay 28, 2020 — by TB Brown · 2020 · Cited by 71969 — GPT-3 achieves strong perform…
This limitation highlights an important distinction in modern AI: large language models can appear to learn new tasks during a conversation, yet much of that adaptation comes from sophisticated use of context rather than changes to the model itself.
Why In-Context Learning Matters
In-context learning helped turn GPT-style Transformers into general-purpose systems. Instead of building and training a separate model for every task, users can often describe the task in natural language or provide a handful of examples. The model then adapts its behaviour on the fly using information contained in the prompt. [arXiv+2NeurIPS Proceedings]arxiv.orgarXiv[2005.14165] Language Models are Few-Shot LearnersMay 28, 2020 — by TB Brown · 2020 · Cited by 71969 — GPT-3 achieves strong perform…
This capability sits at the centre of modern prompting. It explains why the same model can act as a translator, tutor, coding assistant, editor, classifier, or conversational partner without being retrained each time. The model is not learning new parameters during the prompt; it is learning how to use the prompt itself as a temporary source of task-specific guidance. [NeurIPS Papers+2yacinemahdid.com]papers.nips.ccNeurIPS PapersLanguage Models are Few-Shot Learnersby T Brown · 2020 · Cited by 73255 — GPT-3 achieves strong performance on many NLP dat…
Amazon book picks
Further Reading
Books and field guides related to How Can a Model Learn During a Prompt?. Use these as the next step if you want deeper reading beyond the article.
Hands-On Large Language Models
Explains prompting, few-shot learning, GPT behaviour, and in-context learning.
Natural Language Processing with Transformers
Covers transformer language models and prompt-based usage.
Transformers for Natural Language Processing
Includes GPT-style models, prompting, and transformer concepts.
Deep Learning
Rating: 3.5/5 from 6 Google Books ratings
Provides theoretical foundations behind representation learning and generative models.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.


Endnotes
-
Source: arxiv.org
Link: https://arxiv.org/abs/2005.14165Source snippet
arXiv[2005.14165] Language Models are Few-Shot LearnersMay 28, 2020 — by TB Brown · 2020 · Cited by 71969 — GPT-3 achieves strong perform...
Published: May 28, 2020
-
Source: proceedings.neurips.cc
Title: 1457c0d6bfcb4967418bfb8ac142f64a Paper
Link: https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdfSource snippet
as context for all of the problems we evaluated...Read more...
-
Source: arxiv.org
Title: arXiv Language Models are Few-Shot Learners
Link: https://arxiv.org/pdf/2005.14165Source snippet
Language Models are Few-Shot LearnersMay 28, 2020 — by TB Brown · 2020 · Cited by 73753 — For each task, we evaluate GPT-3 under 3 c...
Published: May 28, 2020
-
Source: yacinemahdid.com
Title: whats in context learning in deep
Link: https://www.yacinemahdid.com/p/whats-in-context-learning-in-deepSource snippet
What's In-Context Learning in [Deep Learning]({{ 'deep-learning/' | relative_url }}) and Why Is...20 Aug 2024 — In-context learning is loosely defined as showing a few examples...
-
Source: arxiv.org
Title: arXiv In-context Learning and Induction Heads
Link: https://arxiv.org/abs/2209.11895Source snippet
In-context Learning and Induction HeadsSeptember 24, 2022...
Published: September 24, 2022
-
Source: transformer-circuits.pub
Link: https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.htmlSource snippet
Transformer CircuitsIn-context Learning and Induction Heads8 Mar 2022 — Induction heads are implemented by a circuit consisting of a pair...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2404.07129 -
Source: lesswrong.com
Title: Induction heads
Link: https://www.lesswrong.com/posts/TvrfY4c9eaGLeyDkE/induction-heads-illustratedSource snippet
illustratedJan 2, 2023 — Induction heads are a well-studied and understood circuit in transformers. They allow a model to perform in-cont...
-
Source: arxiv.org
Link: https://arxiv.org/html/2507.16003v3Source snippet
The implicit dynamics of in-context learning22 Dec 2025 — In this work, we show that the stacking of a self-attention layer with an MLP...
-
Source: papers.nips.cc
Link: https://papers.nips.cc/paper_files/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.htmlSource snippet
NeurIPS PapersLanguage Models are Few-Shot Learnersby T Brown · 2020 · Cited by 73255 — GPT-3 achieves strong performance on many NLP dat...
-
Source: ora.ox.ac.uk
Link: https://ora.ox.ac.uk/objects/uuid%3A5c6bc9ad-3eb6-41e1-ac06-8a36128bb20eSource snippet
ford University Research ArchiveUnderstanding in-context learning in transformers and LLMs...by S Bhattamishra · 2024 · Cited by 86 —...
-
Source: thegradient.pub
Title: in context learning in context
Link: https://thegradient.pub/in-context-learning-in-context/Source snippet
In-Context Learning, In Context29 Apr 2023 — When studying transformers under the lens of mechanistic interpretability, researchers at An...
-
Source: research.google
Link: https://research.google/pubs/learning-without-training-the-implicit-dynamics-of-in-context-learning/Source snippet
Google ResearchThe implicit dynamics of in-context learningSpecifically, we show how a transformer block implicitly transforms a context...
-
Source: papers.nips.cc
Title: We also identify some datasets where GPT-3’s
Link: https://papers.nips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.htmlSource snippet
Models are Few-Shot Learnersby T Brown · 2020 · Cited by 71969 — GPT-3 achieves strong performance on many NLP datasets, including transl...
Additional References
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/363859214_In-context_Learning_and_Induction_HeadsSource snippet
(PDF) In-context Learning and Induction HeadsWe present six complementary lines of evidence, arguing that induction heads may be the mech...
-
Source: stackoverflow.com
Link: https://stackoverflow.com/questions/66451430/changes-in-gpt2-gpt3-model-during-few-shot-learningSource snippet
Changes in GPT2/GPT3 model during few shot learningDuring transfer learning, we take a pre-trained network and some observation pair (inp...
-
Source: merriam-webster.com
Link: https://www.merriam-webster.com/dictionary/inSource snippet
IN Definition & Meaning5 days ago — The meaning of IN is —used as a function word to indicate inclusion, location, or position within lim...
-
Source: intuitivepapers.ai
Link: https://intuitivepapers.ai/gpt-3/Source snippet
Language Models are Few-Shot LearnersGPT-3 is a 175-billion-parameter language model that learns new tasks from a few examples in its pro...
-
Source: medium.com
Link: https://medium.com/%40pankaj_pandey/the-power-of-few-shot-learning-in-language-models-4fe79060fef4Source snippet
The Power of Few-Shot Learning in Language ModelsIn this setting, GPT-3 is applied without any gradient updates or fine-tuning, with task...
-
Source: medium.com
Link: https://medium.com/%40natisie/[understandingSource snippet
Understanding Transformer's Induction Heads | by NatisieInduction heads are a special type of attention heads, formed only on transformer...
-
Source: mlmi.eng.cam.ac.uk
Link: https://www.mlmi.eng.cam.ac.uk/files/2020-2021_dissertations/gpt_3_for_few_shot_dialogue_state_tracking.pdfSource snippet
cam.ac.ukGPT-3 for Few-Shot Dialogue State Trackingby N Pezzotti — Moreover, it was capable of performing many other NLP tasks without fi...
-
Source: collinsdictionary.com
Link: https://www.collinsdictionary.com/dictionary/english/in -
Source: sh-tsang.medium.com
Title: review gpt 3 language models are few shot learners ff3e63da944d
Link: https://sh-tsang.medium.com/review-gpt-3-language-models-are-few-shot-learners-ff3e63da944dSource snippet
GPT-3: Language Models are Few-Shot LearnersThese “learning” curves involve no gradient updates or fine-tuning, just increasing numbers...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/in-context-learning-ais-version-ill-figure-out-spot-moghal-sheeba-wwqmeSource snippet
olve tasks solely from examples presented inside the prompt, without any gradient...Read more...
Topic Tree