Within Web Filters
Can cleaner data make AI less fair?
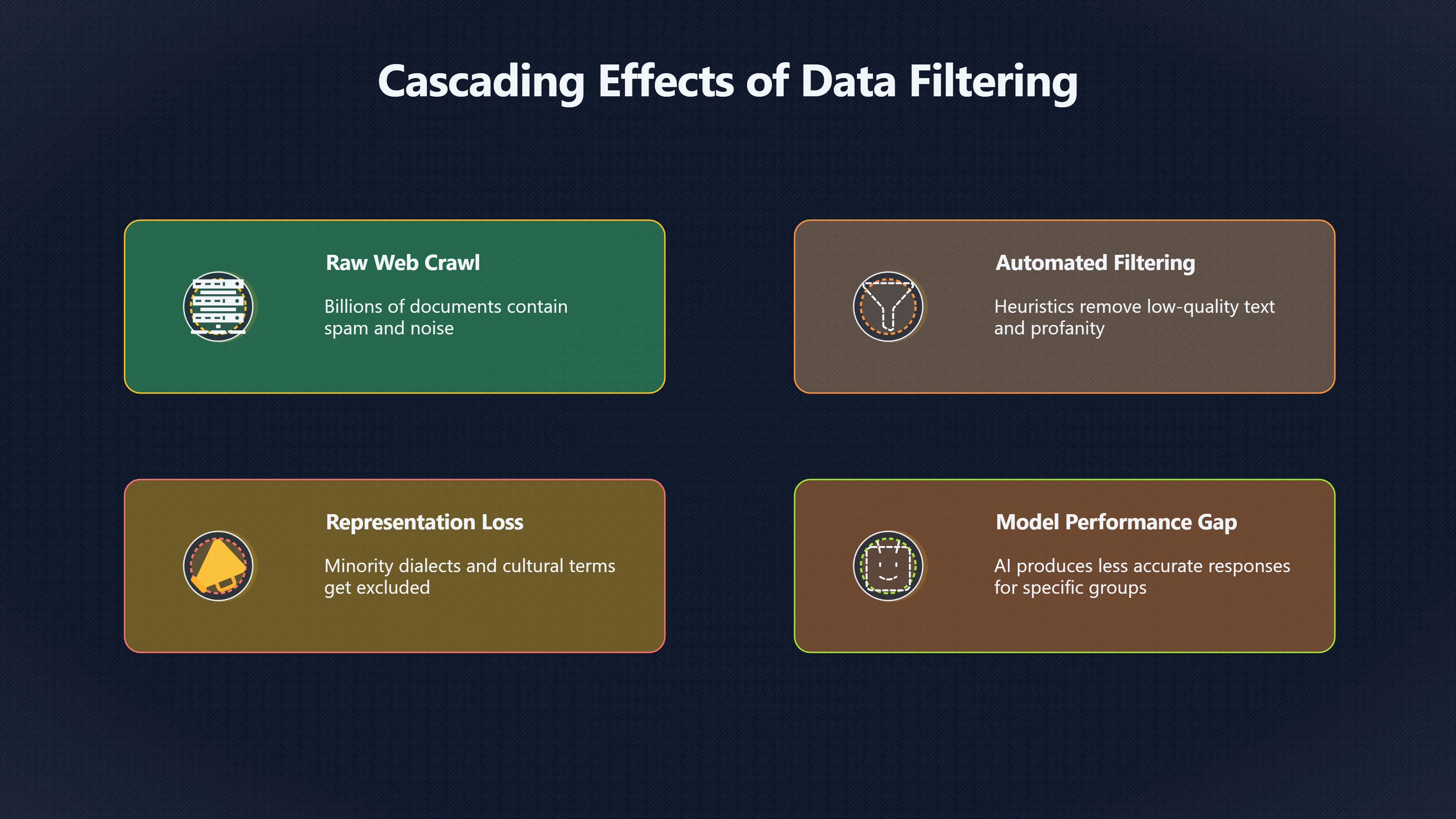
Cleaning web data improves quality, but aggressive filtering can make models less reliable for underrepresented dialects and communities.
On this page
- Why unfiltered web data is still a problem
- Where quality control becomes representation risk
- Practical checks before filtering choices become model behavior
Page outline Jump by section
Introduction
Cleaning web data usually makes language models more useful. Removing spam, duplicated pages, machine-generated noise, and corrupted text helps models learn more reliable patterns. Yet every filtering rule also acts as a decision about which forms of language are considered valuable enough to keep. As a result, efforts to improve quality can sometimes reduce fairness. When filters disproportionately remove dialects, minority-language content, identity-related discussions, or text from underrepresented communities, the model may become less capable of understanding the people whose data was excluded. Research on major training datasets has shown that filtering choices can reshape representation in ways that persist throughout model training and deployment. The fairness question is therefore not whether data should be filtered, but how to balance quality control against the risk of systematically excluding particular voices. [arXiv+2ACL Anthology]arxiv.orgDocumenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled CorpusApril 18, 2021…

Can cleaner data make AI less fair?
The central tradeoff is straightforward: cleaner datasets often produce more efficient and reliable models, but aggressive filtering can narrow the range of language, experiences, and communities represented in training data.
This tension appears because many filtering systems rely on automated signals rather than human understanding. A dataset pipeline may remove pages containing words on a block list, unusual spelling patterns, non-standard grammar, short sentences, or language judged to be low quality. These heuristics are effective at eliminating spam at web scale, but they can also treat legitimate forms of expression as noise. [arXiv]arxiv.orgDocumenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled CorpusApril 18, 2021…
Fairness concerns arise when those mistakes are not evenly distributed. If a filtering rule removes a particular community’s language more often than others, the resulting model receives less exposure to that community’s vocabulary, cultural references, communication styles, and topics of discussion. The model may then perform worse for those users despite having been trained on enormous amounts of data. [ACL Anthology]aclanthology.orgACL Anthology Bias and Fairness in Large Language Models: A SurveyACL AnthologyBias and Fairness in Large Language Models: A SurveySeptember 11, 2024 — by IO Gallegos · 2024 · Cited by 1893 — Bias evalua…
Why unfiltered web data is still a problem
The fairness argument against over-filtering should not be confused with an argument for leaving web data untouched.
Raw web crawls contain substantial amounts of undesirable material, including spam networks, duplicated content, search-engine manipulation, malware pages, machine-generated text, misinformation, and abusive content. Training directly on such data can reduce model quality, increase harmful outputs, and waste computational resources. Large-scale filtering emerged because developers needed practical methods to improve signal-to-noise ratios in datasets containing billions of documents. [ResearchGate+2TensorFlow]researchgate.net350991473 Documenting the English Colossal Clean Crawled CorpusDocumenting the English Colossal Clean Crawled Corpus18 Apr 2021 — In this work we provide the first documentation for the Co…
There are also fairness reasons to remove some content. Hate speech, harassment, coordinated disinformation, and exploitative material can disproportionately harm already vulnerable groups if incorporated without safeguards. Governance therefore involves managing competing fairness objectives rather than choosing between fairness and quality. A model that learns from everything may reproduce harmful stereotypes, while a model that filters too aggressively may erase important forms of representation. [European Parliament]europarl.europa.euThis includes…Read more…
The real challenge is deciding where to draw the boundary.
Where quality control becomes representation risk
One of the clearest examples comes from audits of the Colossal Clean Crawled Corpus (C4), a widely used dataset built from Common Crawl. Researchers found that block-list filtering removed text associated with some minority groups at higher rates than text associated with dominant language varieties. In particular, documents containing features of African American English, Hispanic-associated language varieties, and certain LGBTQ+-related terms were more likely to be excluded because filtering systems interpreted specific words as indicators of low-quality or offensive content. [arXiv+2ACL Anthology]arxiv.orgDocumenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled CorpusApril 18, 2021…
This illustrates a broader governance problem. A filtering system may appear neutral because it applies the same rule to everyone. However, if different communities use language differently, a single rule can have unequal effects.
Several mechanisms commonly create representation risks:
- Profanity and block-list filtering: Identity terms, reclaimed slurs, or community-specific vocabulary can trigger automated removals.
- Grammar and fluency filters: Dialects that differ from standard written forms may be misclassified as lower quality.
- Language-identification filters: Minority languages and mixed-language content are more likely to be incorrectly excluded.
- Source-quality rankings: Communities with fewer institutional websites may be underrepresented when ranking systems favour established domains.
- Length and formatting requirements: Informal communication styles can be removed more often than conventional publishing formats. [arXiv+2WIMBD]arxiv.orgDocumenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled CorpusApril 18, 2021…
The result is not necessarily overt discrimination. Instead, representation gradually declines through thousands or millions of small filtering decisions.
Why missing representation affects model behaviour
Language models learn statistical patterns from examples. If examples become scarce, performance often declines.
A model exposed to fewer examples of a dialect may misunderstand its grammar, incorrectly classify its tone, or generate less accurate responses for speakers of that dialect. Likewise, if discussions of certain identities or cultural experiences are filtered out, the model may have weaker knowledge of those topics or respond in ways that appear insensitive or uninformed. [ACL Anthology]aclanthology.orgACL Anthology Bias and Fairness in Large Language Models: A SurveyACL AnthologyBias and Fairness in Large Language Models: A SurveySeptember 11, 2024 — by IO Gallegos · 2024 · Cited by 1893 — Bias evalua…
Importantly, fairness problems can emerge even when no group is explicitly targeted. A model may simply have fewer opportunities to learn relevant linguistic patterns. Researchers increasingly describe these effects as data-representation problems rather than purely algorithmic bias problems. The model reflects the distribution of examples that survived the filtering process. [arXiv]arxiv.orgData and AI governance: Promoting equity, ethics…5 Aug 2025 — Data and AI governance: Promoting equity, ethics, and fairness in l…
This is one reason why modern AI governance increasingly focuses on dataset decisions alongside model architecture and evaluation.

Filtering is also a governance decision
Dataset cleaning is often presented as a technical preprocessing step, but many scholars argue that it should be treated as a governance issue because filtering determines whose language becomes part of the model’s knowledge base. [Knowing Machines]knowingmachines.orgKnowing MachinesThe case of 'Colossal Cleaned Common Crawl' (C4)A primary objective of the project was to create a publicly accessible da…
Questions that appear technical frequently contain value judgments:
- Which websites are considered trustworthy?
- Which forms of language count as high quality?
- Which types of content are removed for safety reasons?
- Who decides whether a filtering error is acceptable?
- How much representation loss is tolerated in exchange for cleaner data?
These decisions affect downstream users even though they are made long before a model is released. For that reason, transparency about filtering pipelines has become a recurring recommendation in AI governance discussions. Researchers have argued that documentation, auditing, and disclosure are necessary because hidden filtering choices can produce hidden fairness consequences. [arXiv]arxiv.orgDocumenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled CorpusApril 18, 2021…
Practical checks before filtering choices become model behaviour
Organisations developing language models increasingly use safeguards designed to identify representation losses before they become embedded in model behaviour.
Useful governance practices include:
Auditing removed data rather than only retained data.
Many dataset reviews historically focused on what remained after filtering. The C4 audits demonstrated the value of examining what was excluded and whether exclusions disproportionately affected particular communities. [arXiv]arxiv.orgDocumenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled CorpusApril 18, 2021…
Measuring impact across demographic and linguistic groups.
Filtering quality should be evaluated not only by reduced noise but also by changes in representation. If one language variety disappears at a much higher rate than others, that difference should be visible in reporting. [ACL Anthology]aclanthology.orgACL Anthology Bias and Fairness in Large Language Models: A SurveyACL AnthologyBias and Fairness in Large Language Models: A SurveySeptember 11, 2024 — by IO Gallegos · 2024 · Cited by 1893 — Bias evalua…
Making filtering pipelines transparent. [kili-technology.com]kili-technology.comBut teams should still maintain human-in-the-loop review…Read more…
Open documentation allows researchers to inspect assumptions, reproduce results, and identify unintended consequences. Several recent governance proposals emphasise dataset documentation as a core accountability mechanism. [ResearchGate]researchgate.net350991473 Documenting the English Colossal Clean Crawled CorpusDocumenting the English Colossal Clean Crawled Corpus18 Apr 2021 — In this work we provide the first documentation for the Co…
Including affected communities in review processes.
Communities whose language is likely to be filtered can often identify problems that automated metrics miss. Emerging governance frameworks increasingly advocate participatory approaches to data stewardship, particularly for minority-language communities. [arXiv]arxiv.orgCulturally-Grounded Governance for Multilingual Language Models: Rights, Data Boundaries, and Accountable AI DesignJanuary 31, 2026…
Evaluating models after training. [knowingmachines.org]knowingmachines.orgKnowing MachinesThe case of 'Colossal Cleaned Common Crawl' (C4)A primary objective of the project was to create a publicly accessible da…
Even carefully designed filtering can have unexpected effects. Fairness testing across dialects, demographic groups, and cultural contexts helps reveal whether training-data decisions created performance gaps. [ACL Anthology]aclanthology.orgACL Anthology Bias and Fairness in Large Language Models: A SurveyACL AnthologyBias and Fairness in Large Language Models: A SurveySeptember 11, 2024 — by IO Gallegos · 2024 · Cited by 1893 — Bias evalua…

The enduring tradeoff
There is no realistic path to training powerful language models without filtering web data. The internet contains too much noise, duplication, and harmful content to use raw at scale. At the same time, filtering is never a purely mechanical operation. Every cleaning rule changes the distribution of voices that remain available for learning.
The fairness tradeoff therefore lies in recognising that quality control and representation are both legitimate goals. Better filtering can improve reliability, safety, and efficiency. Yet when filtering removes the language of particular communities more often than others, models may become less fair even as they become cleaner. Understanding that tension is an important part of understanding how language models learn from the web—and how governance choices made during dataset construction can shape the behaviour of AI systems long after training is complete. [arXiv]arxiv.orgDocumenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled CorpusApril 18, 2021…
Amazon book picks
Further Reading
Books and field guides related to Can cleaner data make AI less fair?. Use these as the next step if you want deeper reading beyond the article.
The Atlas of AI
Shows how data collection and classification shape AI capabilities and harms.
The Alignment Problem
Connects fairness failures to broader machine-learning alignment and feedback problems.
Weapons of Math Destruction
Explains how automated systems can produce unfair outcomes despite technical intentions.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: arxiv.org
Link: https://arxiv.org/abs/2104.08758Source snippet
Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled CorpusApril 18, 2021...
Published: April 18, 2021
-
Source: arxiv.org
Link: https://arxiv.org/html/2501.10383v1Source snippet
The [Generative AI]({{ 'generative-ai/' | relative_url }}) Ethics Playbook17 Dec 2024 — In the C4 dataset, they filter out documents containing “bad words”, which has a side effe...
-
Source: researchgate.net
Title: 350991473 Documenting the English Colossal Clean Crawled Corpus
Link: https://www.researchgate.net/publication/350991473_Documenting_the_English_Colossal_Clean_Crawled_CorpusSource snippet
Documenting the English Colossal Clean Crawled Corpus18 Apr 2021 — In this work we provide the first documentation for the Co...
-
Source: tensorflow.org
Link: https://www.tensorflow.org/datasets/catalog/c4Source snippet
TensorFlow DatasetsDec 6, 2022 — A colossal, cleaned version of Common Crawl's web crawl corpus. Documentation: Explore on Papers. Englis...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2410.23825 -
Source: arxiv.org
Link: https://arxiv.org/html/2508.03970v1Source snippet
Data and AI governance: Promoting equity, ethics...5 Aug 2025 — Data and AI governance: Promoting equity, ethics, and fairness in l...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2602.00497Source snippet
Culturally-Grounded Governance for [Multilingual]({{ 'language-bias/' | relative_url }}) Language Models: Rights, Data Boundaries, and Accountable AI DesignJanuary 31, 2026...
Published: January 31, 2026
-
Source: researchgate.net
Title: 398471409 Fairness Auditing of Limited Access Models Using Protected Datasets
Link: https://www.researchgate.net/publication/398471409_Fairness_Auditing_of_Limited-Access_Models_Using_Protected_DatasetsSource snippet
(PDF) Fairness Auditing of Limited-Access Models Using...15 Mar 2026 — Fairness auditing of machine learning models is essential for ens...
-
Source: researchgate.net
Title: 392162234 The Importance of AI Data Governance in Large Language Models
Link: https://www.researchgate.net/publication/392162234_The_Importance_of_AI_Data_Governance_in_Large_Language_ModelsSource snippet
The Importance of AI Data Governance in Large Language...20 Mar 2026 — AI data governance is a crucial framework for ensuring that data...
-
Source: cdn.governance.ai
Title: Model Evaulations for Extreme Risks
Link: https://cdn.governance.ai/Model_Evaulations_for_Extreme_Risks.pdfSource snippet
evaluation for extreme risksby T Shevlane · 2023 · Cited by 303 — Current approaches to building general-purpose AI systems tend to produ...
-
Source: aclanthology.org
Link: https://aclanthology.org/2021.emnlp-main.98.pdfSource snippet
ACL AnthologyA Case Study on the Colossal Clean Crawled Corpusby J Dodge · 2021 · Cited by 784 — Upon inspecting the in- cluded data (§4)...
-
Source: aclanthology.org
Title: ACL Anthology Bias and Fairness in Large Language Models: A Survey
Link: https://aclanthology.org/2024.cl-3.8.pdfSource snippet
ACL AnthologyBias and Fairness in Large Language Models: A SurveySeptember 11, 2024 — by IO Gallegos · 2024 · Cited by 1893 — Bias evalua...
Published: September 11, 2024
-
Source: europarl.europa.eu
Link: https://www.europarl.europa.eu/RegData/etudes/STUD/2022/729541/EPRS_STU%282022%29729541_EN.pdfSource snippet
This includes...Read more...
-
Source: wimbd.apps.allenai.org
Title: WIMBDWIMBD: Corpora
Link: https://wimbd.apps.allenai.org/corporaSource snippet
It contains a length filter for improving data quality that filters out documents with short sentences.Read more...
-
Source: knowingmachines.org
Link: https://knowingmachines.org/publications/9-ways-to-see/essays/c4Source snippet
Knowing MachinesThe case of 'Colossal Cleaned Common Crawl' (C4)A primary objective of the project was to create a publicly accessible da...
-
Source: aclanthology.org
Title: 2021.emnlp main.98
Link: https://aclanthology.org/2021.emnlp-main.98/Source snippet
A Case Study on the Colossal Clean Crawled Corpusby J Dodge · 2021 · Cited by 801 — In this work we provide some of the first documentati...
Additional References
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/ai-governance-primer-addressing-bias-systems-yadav-ranjan-she-her–jrsocSource snippet
AI Governance Primer: Addressing Bias in AI SystemsIn this primer, we will dive into the types of AI bias, its societal implications, and...
-
Source: openreview.net
Link: https://openreview.net/pdf?id=vUtQFnlDyvSource snippet
DataRater: Meta-Learned Dataset Curationby DA Calian · Cited by 19 — On both C4/noclean and the Pile, models trained on DataRater filtere...
-
Source: sh-tsang.medium.com
Link: https://sh-tsang.medium.com/review-documenting-largewebtext-corpora-a-case-study-on-the-colossal-clean-crawled-corpus-0bcc6554e4b6Source snippet
Documenting Large Webtext Corpora: A Case...The English Colossal Clean Crawled Corpus (C4) is created by taking the April 2019 snapsho...
Published: April 2019
-
Source: github.com
Link: https://github.com/allenai/c4-documentationSource snippet
allenai/c4-documentationThis is a companion website for our paper Documenting the English Colossal Clean Crawled Corpus. We present some...
-
Source: eurac.edu
Link: https://www.eurac.edu/en/blogs/midas/reframing-minority-rights-amid-global-challenges-the-role-of-ai-and-algorithmic-fSource snippet
EURAC ResearchReframing Minority Rights Amid Global Challenges: The Role...12 May 2025 — This article explores the intersection of AI, m...
Published: May 2025
-
Source: unite.ai
Title: minority voices filtered out of google natural language processing models
Link: https://www.unite.ai/minority-voices-filtered-out-of-google-natural-language-processing-models/Source snippet
Minority Voices 'Filtered' Out of Google Natural Language...24 Sept 2021 — The report, titled Documenting Large Webtext Corpora: A Case...
-
Source: deepai.org
Title: documenting the english colossal clean crawled corpus
Link: https://www.deepai.org/publication/documenting-the-english-colossal-clean-crawled-corpusSource snippet
18 Apr 2021 — In this work we provide the first documentation for the Colossal Clean Crawled Corpus (C4; Raffel et al., 2020), a dataset...
-
Source: kili-technology.com
Link: https://kili-technology.com/blog/9-open-sourced-datasets-for-training-large-language-modelsSource snippet
But teams should still maintain human-in-the-loop review...Read more...
-
Source: essert.io
Link: https://essert.io/ai-governance-frameworks/Source snippet
Learn about ethical AI practices, compliance regulations...
-
Source: digitalcommons.lib.uconn.edu
Link: https://digitalcommons.lib.uconn.edu/cgi/viewcontent.cgi?article=1642&context=law_reviewSource snippet
Governance: Overcoming Policy Barriers to Fairness...by M AKINWUMI · 2025 · Cited by 2 — This Essay explores the policy considerations e...
Topic Tree