Within Attention
Did transformers really replace deep learning?
Transformers changed the main layer type inside language models, but they still rely on stacked neural layers trained on large datasets.
On this page
- What makes a transformer a deep neural network
- How stacked attention layers refine representations
- Why the misconception matters
Page outline Jump by section
Introduction
When transformers became the dominant architecture for language models, many people concluded that attention had replaced deep learning. That interpretation is understandable but incorrect. Attention changed how modern language models process information, yet transformers remain deep neural networks trained with the same broad principles that define deep learning: large datasets, layered representations, gradient-based optimisation, and learned parameters distributed across many neural layers.
 The transformer revolution was therefore an architectural shift within deep learning, not a departure from it. Attention replaced specific components such as recurrent processing in many language systems, but it did not replace the deeper idea of learning hierarchical representations through multi-layer neural networks. The distinction matters because it affects how we understand both the strengths and limitations of modern AI. [arXiv+2Google Research]arxiv.orgarXiv[1706.03762] Attention Is All You NeedJune 12, 2017 — 12 Jun 2017 — We propose a new simple network architecture, the Transformer, b…
The transformer revolution was therefore an architectural shift within deep learning, not a departure from it. Attention replaced specific components such as recurrent processing in many language systems, but it did not replace the deeper idea of learning hierarchical representations through multi-layer neural networks. The distinction matters because it affects how we understand both the strengths and limitations of modern AI. [arXiv+2Google Research]arxiv.orgarXiv[1706.03762] Attention Is All You NeedJune 12, 2017 — 12 Jun 2017 — We propose a new simple network architecture, the Transformer, b…
Did transformers really replace deep learning?
The short answer is no.
Deep learning is a broad approach to machine learning in which neural networks learn representations through multiple layers of computation. A transformer is one particular neural-network architecture within that broader family. The famous 2017 paper Attention Is All You Need proposed replacing recurrence and convolution for sequence processing with attention mechanisms, but it did not abandon neural networks themselves. The authors explicitly introduced the transformer as a new network architecture rather than an alternative to deep learning. [arXiv+2NeurIPS Papers]arxiv.orgarXiv[1706.03762] Attention Is All You NeedJune 12, 2017 — 12 Jun 2017 — We propose a new simple network architecture, the Transformer, b…
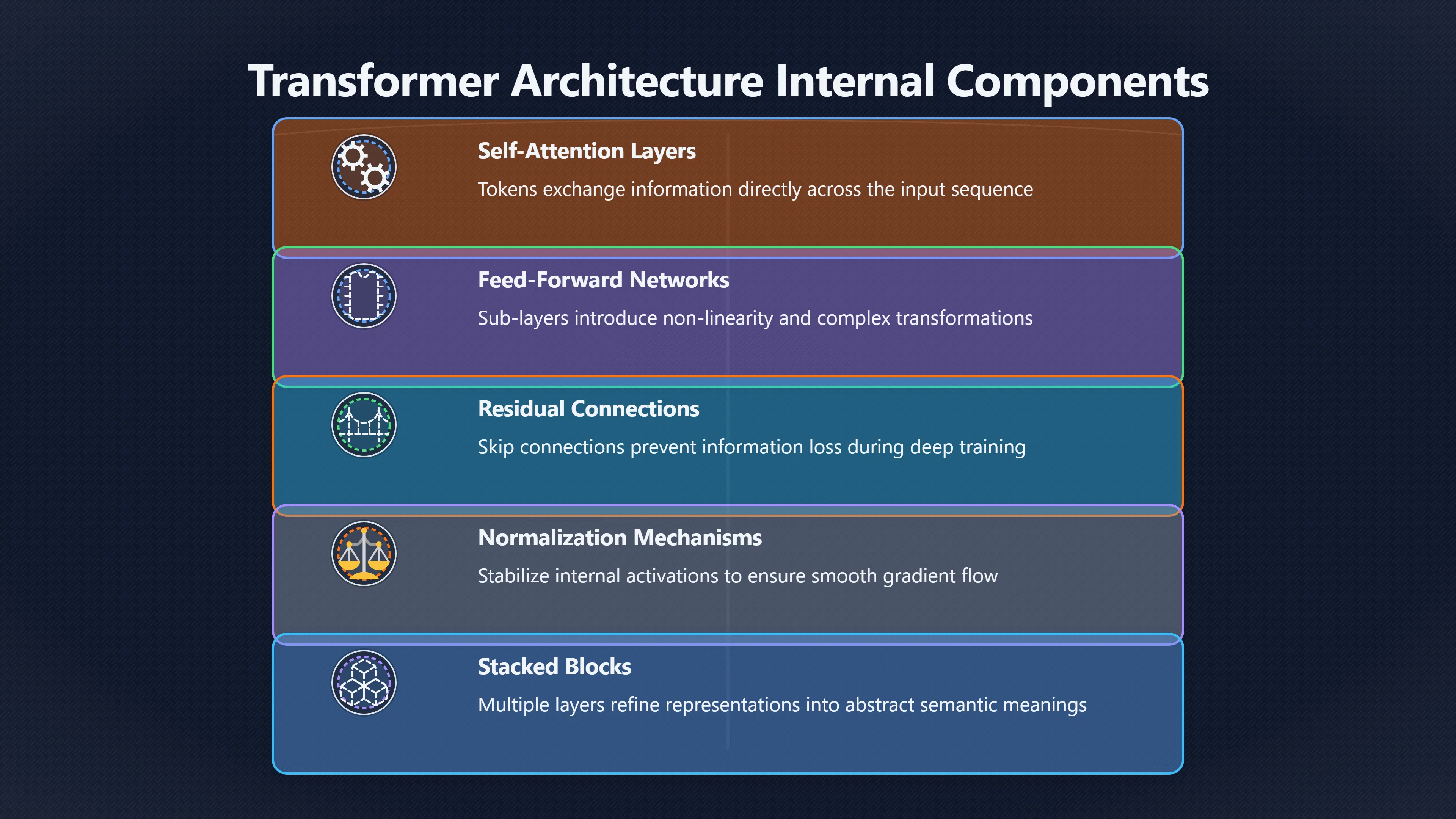
Part of the confusion comes from the paper’s title. “Attention Is All You Need” is often interpreted as meaning that attention alone performs all the work. In practice, transformer models contain multiple interacting components, including attention layers, feed-forward neural networks, residual connections, normalisation mechanisms, and deep layer stacking. Attention is central, but it is only one part of the overall system. [arXiv+2Medium]arxiv.orgarXiv[1706.03762] Attention Is All You NeedJune 12, 2017 — 12 Jun 2017 — We propose a new simple network architecture, the Transformer, b…
A useful analogy is that jet engines did not replace aviation. They replaced an earlier propulsion method while remaining part of the broader field of flight. Similarly, attention replaced certain older neural-network mechanisms while remaining inside the deep-learning framework.
What makes a transformer a deep neural network?
[Transformer]WikipediaTransformerA transformer is a passive component that transfers electrical energy from one electrical circuit to another circuit, or mu… er satisfies the defining characteristics of deep learning.
First, it consists of many stacked layers. Models such as BERT are explicitly described as deep bidirectional transformers, with versions containing 12 or 24 transformer blocks arranged in sequence. Each layer transforms the representation produced by previous layers, creating progressively richer abstractions. [arXiv+2ACL Anthology]arxiv.orgBERT: Pre-training of Deep Bidirectional Transformers for…October 11, 2018 — by J Devlin · 2018 · Cited by 167535 — Unlike recent…
Second, transformers learn their behaviour from data rather than from hand-written rules. During training, billions or trillions of parameters are adjusted through gradient descent to reduce prediction error. This is the same learning process used across modern deep learning. [arXiv]arxiv.orgBERT: Pre-training of Deep Bidirectional Transformers for…October 11, 2018 — by J Devlin · 2018 · Cited by 167535 — Unlike recent…
Third, transformers build hierarchical representations. Early layers tend to capture relatively local or shallow patterns, while later layers develop more abstract semantic information. This layered progression is a hallmark of deep neural networks. Research examining transformer feed-forward layers and model internals has found evidence that different layers contribute different levels of abstraction rather than performing a single flat computation. [arXiv]arxiv.orgarXiv Transformer Feed-Forward Layers Are Key-Value MemoriesTransformer Feed-Forward Layers Are Key-Value MemoriesDecember 29, 2020…
If the attention mechanism were removed from a transformer, it would no longer be the same architecture. But if the deep layered structure were removed, it would no longer be a deep-learning model at all.

How stacked attention layers refine representations
Attention is powerful because it allows tokens to exchange information directly across a sequence. However, a single attention operation is not what gives transformers their remarkable capabilities.
The strength comes from repetition. A token representation is updated, passed to another layer, updated again, and refined through many stages. Each layer receives the results of previous computations and performs additional transformations. This iterative refinement is fundamentally a deep-learning process. [Medium+2poloclub.github.io]medium.comAttention Is All You Need: A Complete Guide to TransformersThe transformer follows an architecture containing stacked attention la…
Consider a sentence containing ambiguity:
“The scientist thanked the engineer because she solved the problem.”
One layer might help connect “she” with potential referents. Later layers can combine broader context, grammatical cues, and semantic information to strengthen one interpretation over another. The final representation emerges through multiple stages rather than a single attention calculation. [poloclub.github.io]poloclub.github.ioLLM Transformer Model Visually ExplainedThe core innovation and power of Transformers lie in their use of self-attention mechanism, which…
Equally important, attention layers are paired with feed-forward neural networks. These feed-forward components introduce additional transformations and non-linearity, enabling the model to build complex representations. Analyses of transformers show that these feed-forward networks account for a large share of the model’s parameters and perform substantial representational work. [arXiv+2Medium]arxiv.orgarXiv Transformer Feed-Forward Layers Are Key-Value MemoriesTransformer Feed-Forward Layers Are Key-Value MemoriesDecember 29, 2020…
The practical lesson is that modern language models succeed because of the interaction between attention and depth, not because attention acts alone.
Why attention alone is not enough
Research has repeatedly shown that pure attention mechanisms are insufficient without the surrounding deep-learning machinery.
One theoretical analysis found that self-attention networks without key supporting components such as feed-forward layers and residual connections tend toward representational degeneration, where outputs become increasingly uniform. The study argued that the additional neural-network structures are essential for preventing this collapse and maintaining expressive power. [arXiv]arxiv.orgAttention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with DepthMarch 5, 2021…
This finding highlights an important misconception. Attention determines which pieces of information should influence one another, but it does not automatically provide all the computation needed to build sophisticated internal representations. Other neural-network components perform critical roles, including transforming, storing, refining, and stabilising information. [arXiv+2arXiv]arxiv.orgAttention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with DepthMarch 5, 2021…
Even the transformer architecture described in the original paper includes far more than attention. Every encoder and decoder layer combines attention mechanisms with feed-forward neural networks and other supporting operations. The architecture’s success comes from the system as a whole. [arXiv+2Medium]arxiv.orgarXiv[1706.03762] Attention Is All You NeedJune 12, 2017 — 12 Jun 2017 — We propose a new simple network architecture, the Transformer, b…

Why the misconception matters
Treating attention as a replacement for deep learning can lead to misunderstandings about how modern AI advances occur.
One misconception is that a single clever mechanism suddenly solved language understanding. In reality, progress emerged from combining several ideas: attention-based architectures, large-scale training data, powerful hardware, optimisation techniques, and increasingly deep models. Removing any of these elements significantly changes performance. [arXiv+2Google Research]arxiv.orgarXiv[1706.03762] Attention Is All You NeedJune 12, 2017 — 12 Jun 2017 — We propose a new simple network architecture, the Transformer, b…
Another misconception is that attention somehow eliminates the challenges associated with deep learning. Transformers still require vast amounts of data, extensive computation, careful training procedures, and large parameter counts. They inherit many of the same strengths and weaknesses as other deep neural networks. [arXiv]arxiv.orgBERT: Pre-training of Deep Bidirectional Transformers for…October 11, 2018 — by J Devlin · 2018 · Cited by 167535 — Unlike recent…
Understanding this distinction also helps explain why researchers continue experimenting with new architectures. If attention were literally all that mattered, architectural innovation would have stopped. Instead, researchers continue studying alternative mechanisms, more efficient replacements, and modifications to self-attention itself. The ongoing search reflects the fact that attention is a highly successful component, not the final word in neural-network design. [arXiv]arxiv.orgarXiv Attention Is Not All You Need AnymoreAttention Is Not All You Need AnymoreAugust 15, 2023…
The real takeaway: attention changed deep learning from the inside
The transformer era represents one of the most important architectural shifts in artificial intelligence. Attention replaced recurrence as the dominant way of handling language sequences and enabled models to scale far beyond earlier approaches. Yet transformers remain deeply rooted in the principles of deep learning.
A modern large language model is still a deep neural network. It learns from data, builds layered representations, adjusts parameters through optimisation, and relies on many stacked computational layers. Attention changed the internal machinery of those layers, but it did not replace the broader framework that made them possible. [Wikipedia+3arXiv+3Google Research]arxiv.orgarXiv[1706.03762] Attention Is All You NeedJune 12, 2017 — 12 Jun 2017 — We propose a new simple network architecture, the Transformer, b…
Amazon book picks
Further Reading
Books and field guides related to Did transformers really replace deep learning?. Use these as the next step if you want deeper reading beyond the article.
Hands-on Machine Learning with Scikit-Learn, Keras, and Tenso...
Shows transformers as one family within the wider deep-learning landscape.
Natural Language Processing with Transformers
Demonstrates how transformers fit into deep-learning workflows rather than replacing them.
Understanding Deep Learning
Explains neural-network fundamentals that underpin transformer models.
Deep Learning
Rating: 3.5/5 from 6 Google Books ratings
Directly addresses what deep learning is, making it ideal for clarifying transformers versus deep learning.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.



Endnotes
-
Source: arxiv.org
Link: https://arxiv.org/abs/1706.03762Source snippet
arXiv[1706.03762] Attention Is All You NeedJune 12, 2017 — 12 Jun 2017 — We propose a new simple network architecture, the Transformer, b...
Published: June 12, 2017
-
Source: Wikipedia
Link: https://en.wikipedia.org/wiki/Attention_Is_All_You_NeedSource snippet
Attention Is All You NeedThe paper introduced a new deep learning architecture known as the transformer, based on the attention mechan...
-
Source: papers.neurips.cc
Title: 7181 attention is all you need
Link: https://papers.neurips.cc/paper/7181-attention-is-all-you-need.pdfSource snippet
NeurIPS PapersAttention is All you Needby A Vaswani · Cited by 252609 — We propose a new simple network architecture, the Transformer, ba...
-
Source: medium.com
Link: https://medium.com/%40alejandro.itoaramendia/attention-is-all-you-need-a-complete-guide-to-transformers-8670a3f09d02Source snippet
Attention Is All You Need: A Complete Guide to TransformersThe transformer follows an architecture containing stacked attention la...
-
Source: arxiv.org
Link: https://arxiv.org/abs/1810.04805Source snippet
BERT: Pre-training of Deep Bidirectional Transformers for...October 11, 2018 — by J Devlin · 2018 · Cited by 167535 — Unlike recent...
Published: October 11, 2018
-
Source: arxiv.org
Title: arXiv Transformer Feed-Forward Layers Are Key-Value Memories
Link: https://arxiv.org/abs/2012.14913Source snippet
Transformer Feed-Forward Layers Are Key-Value MemoriesDecember 29, 2020...
Published: December 29, 2020
-
Source: poloclub.github.io
Link: https://poloclub.github.io/transformer-explainer/Source snippet
LLM Transformer Model Visually ExplainedThe core innovation and power of Transformers lie in their use of self-attention mechanism, which...
-
Source: medium.com
Link: https://medium.com/%40kuberca.io/deep-dive-into-transformer-layers-self-attention-feedforward-and-add-norm-1f59395d376bSource snippet
ayer introduces non-linearity and complexity, and the Add & Norm...Read more...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2103.03404Source snippet
Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with DepthMarch 5, 2021...
Published: March 5, 2021
-
Source: arxiv.org
Title: arXiv Attention Is Not All You Need Anymore
Link: https://arxiv.org/abs/2308.07661Source snippet
Attention Is Not All You Need AnymoreAugust 15, 2023...
Published: August 15, 2023
-
Source: Wikipedia
Link: https://en.wikipedia.org/wiki/TransformerSource snippet
TransformerA transformer is a passive component that transfers electrical energy from one electrical circuit to another circuit, or mu...
-
Source: Wikipedia
Title: BERT (language model)
Link: https://en.wikipedia.org/wiki/BERT_%28language_model%29Source snippet
BERT (language model)Bidirectional encoder representations from transformers (BERT) is a language model introduced in October 2018 by...
Published: October 2018
-
Source: Wikipedia
Title: Transformer (deep learning)
Link: https://en.wikipedia.org/wiki/Transformer_%28deep_learning%29Source snippet
Transformer (deep learning)In deep learning, the transformer is an artificial neural network architecture based on the [multi-head]({{ 'multi-heads/' | relative_url }}) atte...
-
Source: medium.com
Link: https://medium.com/%40punya8147_26846/understanding-feed-forward-networks-in-transformers-77f4c1095c67Source snippet
They take the context-rich outputs from self-attention layers and transform them...Read more...
-
Source: medium.com
Link: https://medium.com/data-science/guide-to-llm-part-1-bert-3d1bf880386a -
Source: medium.com
Link: https://medium.com/%40tnodecode/bert-bidirectional-encoder-representations-from-transformers-0696d29f9d11Source snippet
BERT — Bidirectional Encoder Representations from...Layer by layer, it constructs the deep contextual representations that made BERT suc...
-
Source: medium.com
Link: https://medium.com/the-owl/paper-reading-club-day-1-paper-1-bert-bidirectional-encoder-representations-from-transformers-b4c0d9a3a5efSource snippet
BERT: Bidirectional Encoder Representations from...BERT's model architecture is a multi-layer bidirectional Transformer encoder based on...
-
Source: medium.com
Title: Attention Is All You Need!
Link: https://medium.com/data-science-collective/attention-is-all-you-need-661cb8db5f21Source snippet
Demystifying the Transformer…The Transformer architecture represents one of the most significant breakthroughs in artificial intelligence...
-
Source: medium.com
Link: https://medium.com/image-processing-with-python/the-feedforward-network-ffn-in-the-transformer-model-6bb6e0ff18dbSource snippet
The Feedforward Network (FFN) in The Transformer ModelIn summary, the Feedforward Network is a cornerstone of the Transformer architectur...
-
Source: medium.com
Link: https://medium.com/%40adnanmasood/attention-is-all-you-need-explained-like-youre-smart-and-busy-2a3d7436144fSource snippet
ism, and reshaped modern language models. Adnan Masood, PhD.Read more...
-
Source: medium.com
Title: attention is all you need the paper that revolutionized ai 6e606e6a847b
Link: https://medium.com/%40vijay.poudel1/attention-is-all-you-need-the-paper-that-revolutionized-ai-6e606e6a847bSource snippet
Attention Is All You Need: The Paper That Revolutionized AIIn 2017, a groundbreaking paper titled “Attention Is All You Need” was publish...
-
Source: dilipkumar.medium.com
Title: transformers neural network architecture a6fd825d2d5f
Link: https://dilipkumar.medium.com/transformers-neural-network-architecture-a6fd825d2d5fSource snippet
Neural network architecture | by Dilip KumarMasked Multi-Head Attention: This is a self-attention layer that looks at the sentence being...
-
Source: medium.com
Link: https://medium.com/read-a-paper/bert-read-a-paper-811b836141e9Source snippet
Read A Paper | BERT | Language ModelA language representation model that is designed to pre-train deep bidirectional representations from...
-
Source: medium.com
Link: https://medium.com/%40robin5002234/attention-is-all-you-need-a-deep-dive-into-transformer-architecture-8c34753098c7Source snippet
model to weigh the importance of different words in a sentence when encoding or...Read more...
-
Source: shreyansh26.github.io
Link: https://shreyansh26.github.io/post/2021-05-09_pretraining_deep_bidirectional_transformers_bert/Source snippet
Paper Summary #4 - BERT: Pre-training of Deep...09 May 2021 — The underlying architecture of BERT is a multi-layer Transformer encoder...
Published: May 2021
-
Source: github.com
Link: https://github.com/GitYCC/machine-learning-papers-summary/blob/master/nlp/bert.mdSource snippet
BERT uses masked language models to enable pre-trained...Read more...
-
Source: youtube.com
Title: Transformers, explained: Understand the model behind GPT, BERT, and T5
Link: https://www.youtube.com/watch?v=SZorAJ4I-sASource snippet
What are Transformer Neural Networks?...
-
Source: youtube.com
Title: What are Transformers (Machine Learning Model)?
Link: https://www.youtube.com/watch?v=ZXiruGOCn9sSource snippet
Transformers Explained | Simple Explanation of Transformers...
-
Source: youtube.com
Title: Transformers Explained | Simple Explanation of Transformers
Link: https://www.youtube.com/watch?v=ZhAz268Hdpw -
Source: research.google
Link: https://research.google/blog/transformer-a-novel-neural-network-architecture-for-language-understanding/Source snippet
Google ResearchTransformer: A Novel Neural Network Architecture for...In “Attention Is All You Need”, we introduce the Transformer, a no...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/transformers-simplified-guide-attention-all-you-need-moiz-asghar-zdvmcSource snippet
Transformers Simplified: A Guide to Attention Is All You NeedThe Transformer model consists of two main parts: the encoder and the decode...
-
Source: aclanthology.org
Link: https://aclanthology.org/N19-1423.pdfSource snippet
(i.e., Transformer blocks) as L, the hidden size as. H, and the number of self-attention heads as A.3. We...Read more...
-
Source: aclanthology.org
Link: https://aclanthology.org/N19-1423/Source snippet
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers.Re...
-
Source: mbrenndoerfer.com
Title: transformer feed forward networks
Link: https://mbrenndoerfer.com/writing/transformer-feed-forward-networksSource snippet
Michael BrenndoerferFeed-Forward Networks in Transformers: Architecture...Jun 8, 2025 — Learn how feed-forward networks provide nonlinea...
-
Source: techradar.com
Link: https://www.techradar.com/pro/what-are-transformer-modelsSource snippet
Transformers utilize a structure composed of encoders, decoders, and a dynamic attention mechanism, allowing more efficient handling of l...
-
Source: electronics-tutorials.ws
Link: https://www.electronics-tutorials.ws/transformer/transformer-basics.htmlSource snippet
Transformer Basics and Transformer PrinciplesTransformers are electrical devices consisting of two or more coils of wire used to transfer...
-
Source: geeksforgeeks.org
Title: getting started with transformers
Link: https://www.geeksforgeeks.org/machine-learning/getting-started-with-transformers/Source snippet
Transformers in Machine Learning11 May 2026 — Transformer is a neural network architecture used for various machine learning tasks, espec...
Published: May 2026
-
Source: transformerindia.com
Link: https://www.transformerindia.com/Source snippet
on transformers ranging from 250KVA to 10,000KVA and up to 33 kV...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/alexxubyte_the-most-important-paper-attention-is-all-activity-7404924500187865088-7LDpSource snippet
Transformer Model Explained: Attention Is All You NeedA Transformer is simply a neural network where inputs talk to each other. That comm...
-
Source: huggingface.co
Title: attention is all you need
Link: https://huggingface.co/blog/Esmail-AGumaan/attention-is-all-you-needSource snippet
Transformers2 Jul 2024 — The paper titled "Attention Is All You Need" introduces a new network architecture called the Transformer, which...
-
Source: codecademy.com
Link: https://www.codecademy.com/article/transformer-architecture-self-attention-mechanismSource snippet
Add & norm...Read more...
Additional References
-
Source: d2l.ai
Link: https://www.d2l.ai/chapter_attention-mechanisms-and-transformers/index.htmlSource snippet
11. Attention Mechanisms and TransformersThe core idea behind the Transformer model is the attention mechanism, an innovation that was or...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/bert-bidirectional-encoder-representations-from-shradha-agarwal-xnelcSource snippet
BERT-Bidirectional Encoder Representations from...Unlike traditional models, BERT does not mask the upper triangle embeddings before app...
-
Source: datacamp.com
Link: https://www.datacamp.com/tutorial/how-transformers-workSource snippet
How Transformers Work: A Detailed Exploration of...Transformers are neural network architectures that use self-attention mechanisms to p...
-
Source: web.stanford.edu
Link: https://web.stanford.edu/~jurafsky/slp3/8.pdfSource snippet
stanford.edu8 Transformers... self-attention layer, includes three other kinds of layers: (1) a feedforward layer, (2) residual connectio...
-
Source: d2l.ai
Link: https://d2l.ai/chapter_attention-mechanisms-and-transformers/transformer.html -
Source: inspirehep.net
Link: https://inspirehep.net/literature/2702854 -
Source: towardsai.net
Link: https://towardsai.net/p/machine-learning/attention-is-all-you-need-a-deep-dive-into-the-revolutionary-transformer-architectureSource snippet
A Deep Dive into the Revolutionary Transformer Architecture10 Apr 2025 — This paper introduced the Transformer architecture, a novel appr...
-
Source: blog.paperspace.com
Title: bert pre training of deep bidirectional transformers for language understanding
Link: https://blog.paperspace.com/bert-pre-training-of-deep-bidirectional-transformers-for-language-understanding/Source snippet
paperspace.comBERT: Pre-training of Deep Bidirectional Transformers for...This study proposes improving fine-tuning-based techniques by...
-
Source: quantpedia.com
Title: bert model bidirectional encoder representations from transformers
Link: https://quantpedia.com/bert-model-bidirectional-encoder-representations-from-transformers/Source snippet
BERT Model – Bidirectional Encoder Representations from...12 Apr 2023 — The BERT model employs fine-tuning and bidirectional transformer...
-
Source: geeksforgeeks.org
Title: architecture and working of transformers in deep learning
Link: https://www.geeksforgeeks.org/deep-learning/architecture-and-working-of-transformers-in-deep-learning/Source snippet
18 Oct 2025 — Feed-Forward Neural Network: This sub-layer processes the combined output of the masked self-attention and encoder-decoder...
Topic Tree